利用jemalloc内存分配,控制Firefox堆。
原文:Exploiting the jemalloc Memory Allocator: Owning Firefox's Heap
jemalloc: 你可能早已使用过
jemalloc是一个用户区内存分配器,越来越多地被软件项目用作高性能堆管理器。 它在Mozilla Firefox中用于Windows,Mac OS X和Linux平台,以及作为FreeBSD和NetBSD操作系统上的默认系统分配器。 Facebook还在各种组件中使用jemalloc来处理其Web服务的负载。 然而,尽管如此广泛使用,目前还没有关于jemalloc使用的相关工作。
我们的研究解决了这个问题。我们首先检查jemalloc堆管理器的体系结构及其内部概念,同时重点关注识别可能的攻击向量。 jemalloc没有利用过去广泛使用的“unlinking”或“frontlinking”等概念来破坏其他分配器的安全性。 因此,我们开发了可用于攻击jemalloc堆损坏漏洞的新颖开发方法和Primitives。 作为案例研究,我们调查Mozilla Firefox并演示我们开发的开发Primitives对浏览器堆的影响。 为了帮助愿意继续研究的人员,我们使用其对Python脚本的支持为GDB开发了一个jemalloc调试工具(名为unmask_jemalloc)。
jemalloc技术概述
jemalloc认识到最小页面利用率不再是最关键的功能。 相反,它侧重于从RAM中检索数据的增强性能。 基于局部性原则,该原理声明分配在一起的项目也一起使用,jemalloc试图在内存中连续地分配。 jemalloc的另一个基本设计选择是通过尝试避免许多同时运行的线程之间的锁争用问题来支持SMP系统和多线程应用程序。 这是通过使用许多'arenas'来实现的,并且第一次线程调用内存分配器(例如通过调用malloc(3))它与特定的 arena 相关联。 threads 到 arena 的分配有三种可能的算法:
- 如果TLS可用,则在线程ID上进行简单散列
- 如果定义了MALLOC_BALANCE并且TLS不可用,则使用简单的内置线性同余伪随机数生成器
- 使用传统的循环算法。
对于后两种情况,thread 和 arena 之间的关联在 thread 的整个生命周期中不会保持不变。
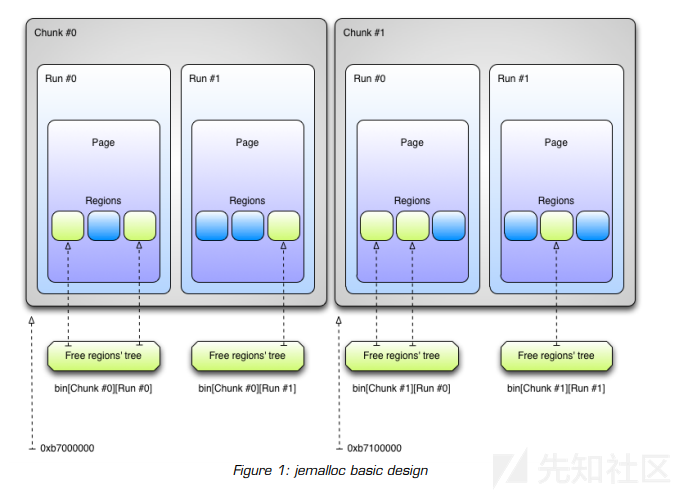
继续我们对主要jemalloc结构的概述,我们有'chunks'的概念。 jemalloc将内存划分为 chunks,总是具有相同的大小,并使用这些 chunks 来存储其所有其他数据结构(以及用户请求的内存)。 chunks 被进一步划分为“runs”,负责处理特定大小的请求/分配。用一个“run”来记录这些空闲和使用过的“regions”的大小。Regions 是用户分配返回的堆项(例如malloc(3)调用)。 最后,每个“run”与“bin”相关联。 Bins 负责存储空闲区域的结构(树)。 图1以抽象的方式说明了jemalloc的基本构建块之间的关系。
Chunks
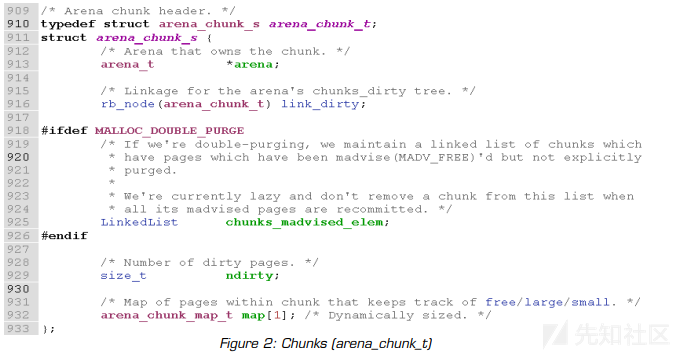
jemalloc中,在概念上对可用内存进行划分,chunks 是大的虚拟内存区域。如我们所提到的,chunks 总是具有相同的大小。但是,每个不同的jemalloc版本都有一个特定的 chunks 大小。 例如,Mozilla Firefox中使用的jemalloc版本的 chunks 大小为1 MB,而FreeBSD libc中使用的 chunks 大小为2 MB。 chunks 由'arena_chunk_t'结构描述,如图2所示。
Arenas
Arena 是一种管理jemalloc划分为 chunks 和底层页面的内存区域的结构。 Arenas可以跨越多个 chunk,并且根据 chunk 的大小,也可以跨越多个页面。 正如我们已经提到的,arenas 用于缓解与 threads 之间的锁争用问题。 因此,thread 的分配和解除分配总是发生在同一个 arena。 从理论上讲,arenas 的数量与内存分配中的并发需求直接相关。 在实践中,arenas 的数量取决于我们处理的jemalloc变体。 例如,在Firefox的jemalloc中只有一个 arena。 在单CPU系统的情况下,也只有一个 arena。 在SMP系统中,arenas 的数量等于两个(在FreeBSD 8.2中)或四个(在独立变量中)乘以可用CPU核心数。 当然,总有至少一个 arena。Arenas 由图3中所示的结构描述。

Runs
Runs 是内存进一步划分的单位,由jemalloc在 chunks 中划分。Runs 仅适用于小型和大型分配(大小类在下一段中解释),但不适用于大量分配。 从本质上讲,一个 chunk 被分成几个 runs。 每个 run 实际上是一组一个或多个连续页面(但运行不能小于一页)。 因此,它们与页面大小的倍数对齐。 runs 本身可能是非连续的,但由于jemalloc实现的树搜索启发式算法,使它们尽可能接近。
Run 的主要职责是跟踪最终用户存储器分配的状态(即,空闲或使用),或者以jemalloc术语调用这些 regions。 每个 run 都保存特定大小的 regions (但是不包括我们提到的小型和大型类中)并且使用位掩码跟踪它们的状态。 此位掩码是 run's metadata的一部分; 这些metadata如图4所示。

Regions
在jemalloc中,术语“regions”适用于malloc(3)返回的最终用户内存区域。 正如我们前面简要提到的,regions 根据其大小分为三类,即:
- small/medium,
- large and
- huge.
Huge regions 被认为是大于 chunk 大小减去一些jemalloc头部的大小。 例如,在 chunk 大小为4 MB(4096 KB)的情况下,huge region 的分配大于4078 KB。 Small/medium 是小于页面的 regions。Large regions 小于huge regions (chunk 大小减去一些头部)并且还大于small/medium regions(页面大小)。
Huge regions 有自己的 metadata ,并与 small/medium ,large regions分开管理。 具体来说,它们由分配器红黑树进行全局管理,并且它们具有自己的专用和连续的 chunks。 Large regions 有自己的runs,即每个大型分区都有专用 run。 它们的 metadata 位于相应的 arena chunk 头上。 根据具体大小,将Small/medium regions 放置在不同的 runs 中。 正如我们已经解释过的,每个 run 都有自己的头,其中有一个位掩码数组,用于指定 run 中的空闲和已使用 regions 。
Bins
jemalloc使用 bins 来存放空闲的 regions。 “Bins”通过 runs 组织空闲的 regions 并保留有关其regions 的 metadata ,例如大小类,regions 总数等。特定 bin 可以与多个 runs 相关联,但是特定run 只能与特定的 bin 相关联,即在 bin 和 run 之间存在一对多的对应关系。 Bins 在树中组织了相关的 runs。 每个 bin 具有关联的大小类,并存储/管理此大小类的 regions。 通过 bin 的 runs 来管理和访问 bin 的 regions 。每个bin都有一个成员元素,表示最近使用在 bin 中被使用的 run ,称为'current run',变量名为runcur。 bin 还有 可用/空闲regions 的 runs 树。 当 bin 的current run 已满时使用此树,即它没有任何空闲 regions。 bin 结构如图5所示。

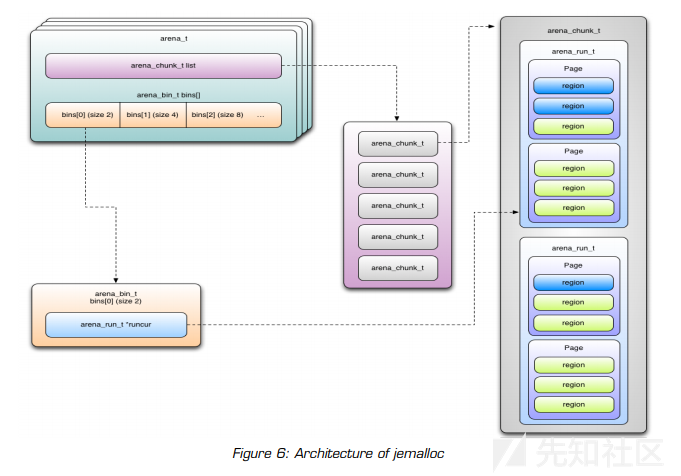
图6总结了我们对jemalloc架构的概述。
Exploitation Primitives
在我们开始分析之前,我们想指出jemalloc(以及其他malloc实现)没有实现像'unlinking'或'frontlinking'这样的概念,这些概念已被证明对dlmalloc和Microsoft Windows分配器的利用具有催化作用。也就是说,我们想强调一个事实,即我们要呈现的攻击并不能直接实现write-4-anywhere primitive。相反,我们关注如何强制malloc()(以及可能realloc())返回一个很可能指向已经初始化的内存区域的块,希望所讨论的区域可能包含对于目标应用程序(C ++ VPTR,函数指针,缓冲区大小等)。考虑到现代操作系统(ASLR,DEP等)中存在的各种反利用策略,我们认为这种结果对于攻击者来说比4字节覆盖更有用。我们的目标是涵盖所有可能的数据或metadata损坏案例,具体而言:
- 相邻区域覆盖
- Run标头损坏
- Chunk头损坏
- 由于Mozilla Firefox不使用线程缓存,因此本白皮书不涉及线程(a.k.a。线程缓存)损坏。有关此主题的更多信息,请参阅[PHRC]和[PHRK]。
相邻区域覆盖
相邻堆项目损坏背后的主要思想是,利用堆管理器将用户分配的内存连续放置在彼此旁边而不需要其他数据的事实。 在相同大小等级的jemalloc regions 放置在同一个 bin 上。 如果它们也被放置在bin的相同run 中,则它们之间没有内联 metadata。 因此,我们可以将我们要选择破坏的 object/structure 放在同一个 run 中,并且放在我们计划溢出的易受攻击的 object/structure 旁边。 唯一的要求是它们和易受攻击的 objects 需要具有相同大小,才能放入同等大小的类中,才可能在同一个 run 中。 由于这两个regions 之间没有 metadata ,我们可以从易受攻击的 region 溢出到我们选择的 victim region。 通常,victim region可以帮助我们实现任意代码执行,例如函数指针。
为了能够将jemalloc堆安排在可预测的状态,到达我们的目的,我们需要了解分配器的行为并使用堆操作策略来影响它。 在浏览器的背景下,在Alexander Sotirov的作品[FENG]之后,堆操作策略通常被称为“Heap Feng Shui”。 “可预测状态”是指堆必须尽可能可靠地排列,以便我们可以将数据放在我们想要的位置。 这使我们能够使用破坏邻近区域的策略,还可以利用 use-after-free 漏洞。 在use-after-free之后,内存区域被分配,使用,释放,然后由于错误而再次使用。 在这种情况下,如果我们知道区域的大小,我们可以操作堆,以便在再次使用之前将我们自己选择的数据放置在 run 释放的 region 的内存槽中。 在随后的错误使用后,该 region 现在拥有可以帮助我们劫持执行流程的数据。
为了探索jemalloc的行为并将其操纵为可预测的状态,我们使用类似于[HOEJ]中提出的算法。由于在一般情况下我们不能事先知道我们感兴趣的类大小的 runs 状态,我们执行这种大小的许多分配,希望覆盖现有runs 中的孔(即空闲regions)并获得新的 run。希望我们将要执行的下一系列分配将在这个新的 run 中进行,因此这将是有序的。正如我们所看到的,在很大程度上空的 run 的顺序分配也是连续的。接下来,我们执行由我们控制的一系列分配。在我们尝试使用相邻 regions 破坏的情况下,这些分配是我们选择的victim object/structure,以帮助我们在损坏时获得代码执行。以下步骤是在最后一系列受控victim 分配中解除分配每个第二个 region。这将在我们试图操作的大小类的 run 中与 victim objects/structures 之间创建漏洞。最后,我们强制触发堆溢出错误,由于我们已经安排好的状态,jemalloc将易受攻击的对象放在 run 运行的漏洞中,溢出到 victim objects 中。在讨论Mozilla Firefox浏览器的案例研究时,我们在以下段落中使用并详细说明了这种方法。
Run 标头损坏
在堆溢出情况下,攻击者能够溢出后面没有跟着其他 regions 的区域(例如dlmalloc中的wilderness chunk,但在jemalloc中这样的 regions 并不那么特殊)是很常见的。 在这种情况下,攻击者很可能会覆盖下一个 run 的头部。 由于 runs 保持相同大小的内存区域,下一页对齐的地址将是当前 run 的正常页面,或者将包含下一次run 的 metadata (头部),其将保存不同大小的 regions (更大或更小,但它并不重要)。 在第一种情况下,可以覆盖相同 run 的相邻 regions ,因此攻击者可以使用先前讨论的技术。 后一种情况是以下段落的主题。
熟悉堆利用的人可能会记得攻击者控制分配的最后一个堆项(在我们的例子中是region),也就是说,最近分配的 region 是溢出的 region 。这允许攻击者破坏 run 的标头。当覆盖 run 的 metadata 时,可以使 bin 指针指向假的 bin 结构。但这不是一个好方法,有以下两个原因。首先,攻击者需要进一步控制目标进程,以便在内存中的某处成功构建伪 bin 头。其次,最重要的是,指向 region 的 run 的'bin'指针仅在解除分配期间被解除引用。对jemalloc源代码的仔细研究表明,实际上只使用'run-> bin-> reg0_offset'(在'arena_run_reg_dalloc()'中某处),因此,从攻击者的角度来看,bin 指针并不那么有趣(' reg0_offset'覆盖可能会导致进一步的问题,导致崩溃和强制中断我们的漏洞利用)。
我们的攻击包括以下步骤。攻击者溢出 run 的最后一项(例如run #1)并覆盖下一个 run (例如,运行#2)标头。 然后,在下一个大小等于 run #2服务的大小的malloc()时,用户将得到一个指向前一个run 的内存区域的指针(在我们的例子中 run #1)。重要的是要理解,为了使攻击起作用,溢出 run 应该服务于属于任何可用bins的regions。
Chunk 头损坏
我们现在将重点关注攻击者能够破坏 arena 的 chunk 头部后可以做什么。 虽然直接影响附近arena 的概率很低,但是内存泄漏或通过连续的bin大小分配间接控制堆布局可能会使本节中描述的技术成为攻击者手中的有用工具。 我们将分析的场景如下:攻击者通过控制其堆分配强制目标应用程序分配新的 arena。 然后,它在前一个 arena 的最后一个 region (物理上与新 arena 接壤的 region )中触发溢出,从而破坏了chunk 头的 metadata部分。 当应用程序在新分配的arena的任何region上调用“free()”时,jemalloc 堆管理信息会被更改。 在下一次调用'malloc()'时,分配器将返回一个 region,该 region 指向(刚好)前一个 arena 的已分配空间。
案例研究:Mozilla Firefox
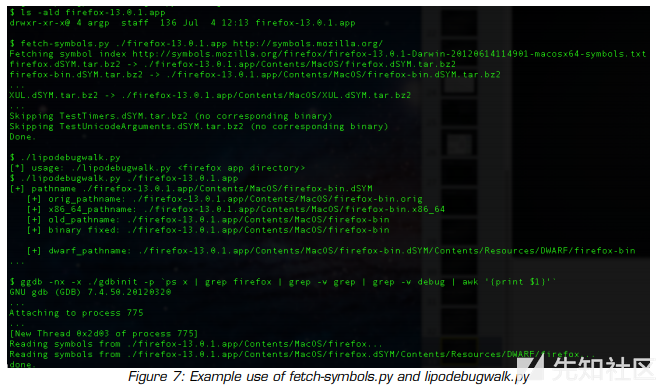
我们的jemalloc调试工具unmask_jemalloc是使用GNU调试器(gdb)的Python脚本支持实现的。 虽然unmask_jemalloc支持Linux 32位和64位Mozilla Firefox目标,但在Mac OS X操作系统方面存在问题。 Apple的gdb基于6.x gdb树,这意味着它不支持Python脚本。 新的gdb开发快照支持Mach-O二进制文件,但无法加载Apple的fat二进制文件。 为了解决这个问题,我们使用Apple的lipo实用程序和我们开发的一个名为lipodebugwalk.py的脚本。 这个脚本以递归方式在Firefox.app的二进制文件中使用Apple的lipo。 此外,lipodebugwalk.py还支持Mozilla Firefox的调试符号二进制文件。 图7包含使用fetch-symbols.py(由Mozilla提供)获取Firefox调试符号的输出,以及使用lipodebugwalk.py允许自定义编译版本的gdb加载Firefox。
上面的过程允许我们利用unmask_jemalloc来探索jemalloc如何管理Firefox的堆并帮助我们进行漏洞利用开发。 图8描绘了unmask_jemalloc的帮助消息,并显示了我们在该工具中实现的功能:
使用unmask_jemalloc,我们可以研究如何从Javascript操作Firefox的jemalloc托管堆。 以下脚本使用未转义的字符串和数组来演示受控分配和解除分配。 由于Firefox实现了对传统堆喷的缓解,因此脚本使用随机填充到已分配的块[CORL]。
<html>
<head>
<script>
function jemalloc_spray(blocks, size)
{
var block_size = size / 2;
// rop/bootstrap/whatever
var marker = unescape("%ubeef%udead");
marker += marker;
// shellcode/payload
var content = unescape("%u6666%u6666");
while(content.length < (block_size / 2))
{
content += content;
}
var arr = [];
for(i = 0; i < blocks; i++)
{
// construct the random block padding
var rnd1 = Math.floor(Math.random() * 1000) % 16;
var rnd2 = Math.floor(Math.random() * 1000) % 16;
var rnd3 = Math.floor(Math.random() * 1000) % 16;
var rnd4 = Math.floor(Math.random() * 1000) % 16;
var rndstr = "%u" + rnd1.toString() + rnd2.toString();
rndstr += "%u" + rnd3.toString() + rnd4.toString();
var padding = unescape(rndstr);
while(padding.length < block_size - marker.length - content.length)
{
padding += padding;
}
// construct the block
var block = marker + content + padding;
// if required repeat the block
while(block.length < block_size)
{
block += block;
}
// spray block
arr[i] = block.substr(0);
}
Math.asin(1);
marker = unescape("%ubabe%ucafe");
marker += marker;
content = unescape("%u7777%u7777");
while(content.length < (block_size / 2))
{
content += content;
}
for(i = 0; i < blocks; i += 2)
{
delete(arr[i]);
// arr.splice(i, 1);
arr[i] = null;
}
var ret = trigger_gc();
alert("After garbage collection: " + ret.length);
for(i = 0; i < blocks; i += 2)
{
var rnd1 = Math.floor(Math.random() * 1000) % 16;
var rnd2 = Math.floor(Math.random() * 1000) % 16;
var rnd3 = Math.floor(Math.random() * 1000) % 16;
var rnd4 = Math.floor(Math.random() * 1000) % 16;
var rndstr = "%u" + rnd1.toString() + rnd2.toString();
rndstr += "%u" + rnd3.toString() + rnd4.toString();
var padding = unescape(rndstr);
while(padding.length < block_size - marker.length - content.length)
{
padding += padding;
}
var block = marker + content + padding;
while(block.length < block_size)
{
block += block;
}
arr[i] = block.substr(0);
}
Math.atan2(6, 6);
return arr;
}
function trigger_gc()
{
// force garbage collection
var gc = [];
for(i = 0; i < 100000; i++)
{
gc[i] = new Array();
}
return gc;
}
function run_spray()
{
// 1024 spray blocks of size 320 (target run: 512)
var foo = jemalloc_spray(1024, 320);
alert(foo.length);
}
</script>
</head>
<body onload="run_spray();">
0x1337
</body>
</html>
结论
在本白皮书中,我们从开发角度分析了jemalloc内存分配器。 我们开发了可用于攻击利用jemalloc的任何应用程序的开发原语。 此外,我们已将这些原语应用于最广泛使用的jemalloc应用程序,即Mozilla Firefox浏览器。 我们的unmask_jemalloc调试实用程序可以在漏洞利用开发期间用于探索jemalloc的内部,并帮助研究人员继续我们的工作。
参考
[PHRC] argp, huku, Pseudomonarchia jemallocum
[PHRK] huku, argp, The Art of Exploitation: 关于jemalloc堆溢出的案例研究
[HOEJ] Mark Daniel, Jake Honoroff, Charlie Miller, 使用Javascript进行工程堆溢出漏洞利用
[FENG] Alexander Sotirov, Javascript 中的堆风水
[CORL] corelanc0d3r, 堆喷揭秘