挖洞经验 | 用跨站搜索(XS-Search)在谷歌问题跟踪平台实现敏感信息获取
前言
本文中,作者详细介绍了在谷歌的Monorail问题跟踪平台(https://bugs.chromium.org/)上 ,实现跨站搜索攻击(XS-Search attack),从一些谷歌未公开的漏洞报告中,获取源代码和涉及函数所在行数等敏感的漏洞报告信息。


Monorail 服务介绍
Monorail是谷歌旗下用于针对Chromium浏览器项目的开源问题跟踪平台(Issue Tracker),它具备云托管、自定义ACL问题和用户权限、组件和代码结构的相互映衬、组件所有者具备一定权限、问题的自定义描述、多项目托管和问题在项目间的无缝对接。
Monorail的问题跟踪机制主要应用于基于Chromium浏览器的开源项目中,当然也包括Monorail服务自身,而针对我们所熟知的谷歌其它开源项目,如Angle、PDFium、Gerrit, V8 和 开放媒体联盟(the Alliance for Open Media),谷歌安全团队Project Zero也会使用Monorail来跟踪这些项目的漏洞发现和处理进程。
从头说起
我分析Monorail服务时最先研究的功能就是,查询结果的CSV格式报告下载功能。比如说,我们以使用Monorail服务的https://bugs.chromium.org/p/chromium/问题跟踪平台为例,我们查询id号911374和911375问题,会有以下查询显示结果:
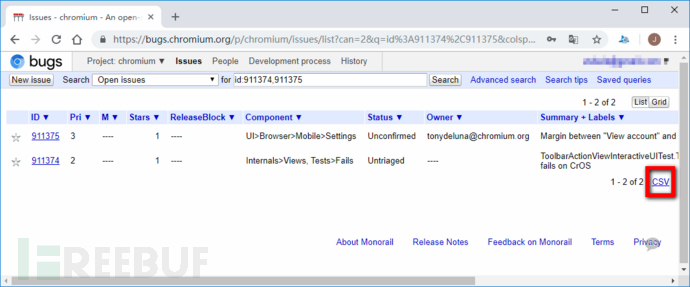
可看到,右下角会有一个CSV结果报告下载按钮,右键复制其下载链接后,可得到以下链接:
https://bugs.chromium.org/p/chromium/issues/csv?can=1&q=id%3A911374%2C911375&colspec=ID
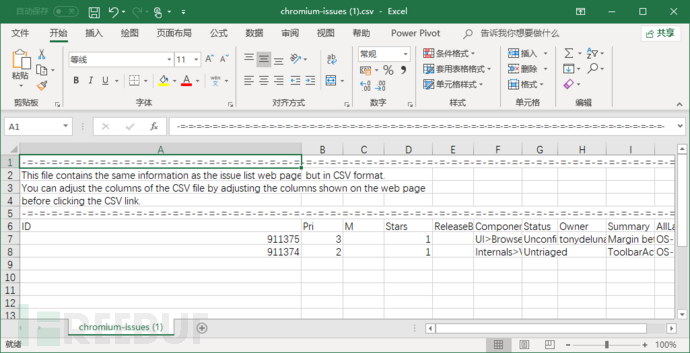
下载之后的CSV文件结果如下:
我研究了其高级搜索功能(Advanced Search),其中对查询结果作了多种过滤条件,如安全团队可看的显示视角 Restrict-View-SecurityTeam:permission securityteam needed to use view ,利用这种过滤条件,我发现该功能中存在一个CSRF漏洞,也就是说,如果某个链接是可以访问的,那么可以恶意构造针对这个链接的访问查询请求,通过下载其返回的CSV格式结果报告,间接知晓该链接下包含的内容。
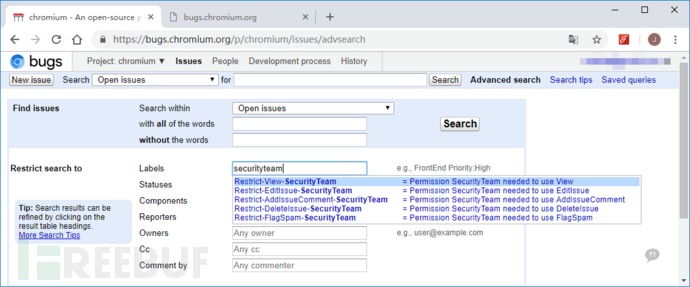
如可以构造q=Restrict=View-SecurityTeam的以下查询请求链接:
https://bugs.chromium.org/p/chromium/issues/csv?can=1&q=Restrict=View-SecurityTeam&colspec=ID
服务器对该请求的响应如下:
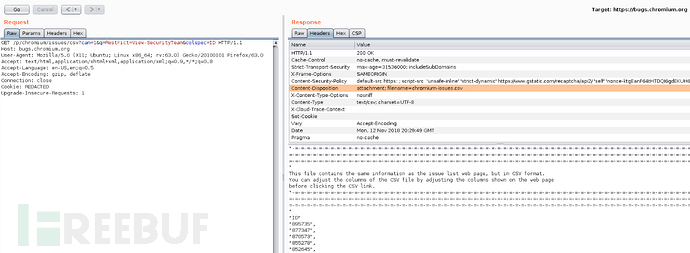
从上述图片中可知,请求响应中没有针对CSRF攻击的保护机制,因此,构造了q=Restrict=View-SecurityTeam的标签,就能将最终查询结果定义到 ”安全团队查看视角“下,该过滤条件查询出来的结果全是一些未公开的安全相关问题内容,如id号为895735、877347和870573条目等,这些条目问题是不能由普通用户查询得到的,只有谷歌安全团队或高级别的漏洞报告者才具备这种权限。
任意增加结果生成列(重复生成结果列)
另一个重要发现就是,在查询结果的CSV生成报告中,可以任意增加结果生成列,比如,我们使用包含colspec=ID+Summary+Summary+Summary的以下查询链接:
https://bugs.chromium.org/p/chromium/issues/csv?can=1&q=id:51337&colspec=ID+Summary+Summary+Summary
最终生成的CSV报告中,就会包含3个Summary列(原来只有1个Summary列):

综合利用形成跨站搜索攻击(XS-Search Attack)
跨站搜索攻击(XS-Search Attack,XS-Timing Attack on search service):类似边信道攻击,通过向目标站点发送搜索请求,结合特定搜索功能,根据响应时间差异(XS-Timing)来判断目标服务端隐私信息的准确性,间接绕过”同源策略“影响,是一种新型的Web攻击方式。在可搜索信息量较大,或目标服务端搜索功能多样化的场景下,是一种有效的信息获取手段。跨站搜索攻击 最早为以色列巴伊兰大学的安全研究员发现,可参考《 xs search attack》和《AppSecIL2015_Cross-Site-Search-Attacks_HemiLeibowitz》两篇原始议题。
综合以上两方面的漏洞发现,我们就具备了发起跨站搜索攻击(XS-Search Attack)的所有可能条件:
1、执行复杂搜索查询的能力
2、扩展显示查询响应的能力
尤其是第二个条件较为重要,如果某个搜索查询的响应和某个漏洞(bug)报告相匹配,那么利用这种扩展性,我们就能在其生成的CSV报告中显示出更多原本不存在的内容。
由于响应内容的长度存在很大差异,因此,可以计算出每个请求完成后所花费的时间,以此来推断查询是否会返回结果。基于此,我们可以实现向Google服务端抛出一些”跨域布尔问题“(cross-origin boolean questions),布尔值问题即真(True)or 假(False)的问题,看看是否能得到有效响应。
“跨域布尔问题“(cross-origin boolean questions)来源于跨站搜索攻击的共同发现者以色列巴伊兰大学Hemi Leibowitz在2015年 OWASP AppSec 大会的议题分享,其中涉及了针对Gmail发送请求的响应判断。

例如在这里,可以本质上理解为我们对服务端请求如下问题:
有与目录`src/third_party/pdfium/`相匹配的未公开漏洞报告吗?
之后,基于时间差的响应判断,我们会跨域地从服务端中间接获取到上述问题的答案。结合此例,简单地说,可用以下几个步骤来对跨站搜索攻击做个认识。
比如,我们根据bugs.chromium.org服务端的任意增加结果生成列漏洞,对其构造查询问题:
第一种情况: 构造 “Summary: This bug exists”样式查询,然后其查询结果 CSV报告中会生成以下内容:

第二种情况: 构造“Summary: This bug doesn’t exist”样式查询,然后其查询结果 CSV报告中会生成以下内容:

第三种情况:构造 ”Summary: This bug exists OR Summary: This bug doesn’t exist“样式查询,然后其查询结果 CSV报告中会生成以下内容:

可以看到,在第一和第三种情况中,由于请求的问题或bug最终匹配了summary中的 “This bug exists”,所以可以生成任意的大内容CSV结果文件;而第二种情况中,CSV结果文件除了头部内容之外,summary部份信息是空的,这是因为其请求的问题或bug结果,与summary中的 “This bug doesn’t exist”不匹配。而值得注意的是,第三种情况中,我们使用了OR逻辑符来综合了第一和第二种请求。
To ask or not to ask?
有了这种构思后,我考虑的是在漏洞利用PoC中应该向Monorail服务发出怎样的提问(搜索)?Monorail的搜索功能中不允许对漏洞报告中涉及的特定字母进行查询,只能查询单词,而我也不可能对其进行逐字符的暴力枚举查询。
意识到这点,我只好退后一步,在网上查找一些谷歌公开的漏洞报告,看看其披露的相关信息是否可以拿来进一步利用。
之后,我发现许多公开且能找到的Chromium相关漏洞报告中,其披露信息中包含了一些文件的路径和提及相关函数在代码中的行号(line number )信息,如链接为 https://bugs.chromium.org/p/chromium/issues/detail?id=770148的漏洞报告:
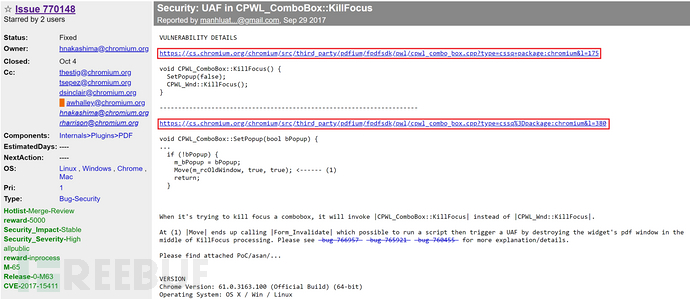
这对于跨站搜索攻击(XS-Search attack)来说非常适合,由于Chromium项目的文件结构和Monorail服务只会把斜线作为文字分隔符,也就是说,如果对某个漏洞报告涉及路径“path/to/dir” 的查询结果中,一样会包含对路径“path/to/dir/sub/dir”的查询结果。
所以,我们可以抽象地来构造出如下流程的查询请求:
1、假设我们要查询的谷歌未公开漏洞报告,涉及到了在Chromium项目文件结构中的某个文件,那么,我们可以用以下链接作为基本查询链接,再深入进行延伸:
2、可用OR连接符来对不同文件路径进行查询,如 src/blink OR src/build ,如下图所示:
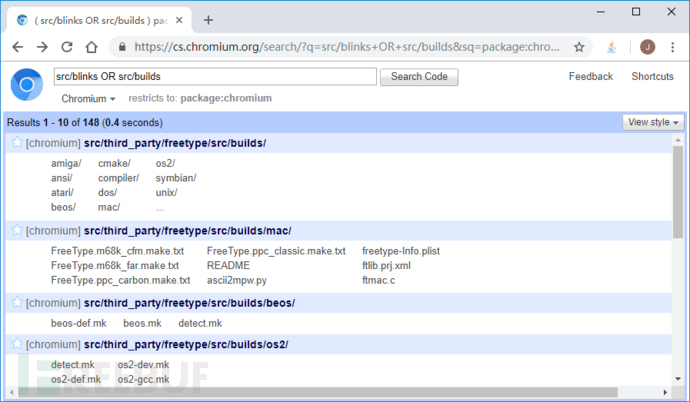
3、反复重复以上第2步的查询,如果能得到相应结果(这就等同于前面描述的生成大内容CSV结果报告),那么,把查询请求限定在前半部分src/blink;如果不能得到相应结果(这就等同于前面描述的生成的CSV结果报告为空),则把查询请求限定在后半部分src/build;
4、以此反复,得到包含文件的准确文件目录,然后,基于前述链接,继续构造其它文件目录往下一级目录深入查询。
最终,经过多轮判断,我们会得到那个包含文件的完整URL链接,也就会理所当然地得到其涉及的未公开漏洞报告信息。
一个请求就能得到所有信息
你可能奇怪,那么,我们怎样来知晓上述第3步中的CSV大小呢?因为同源策略下,限制了不同域之间的信息获取。
虽然我们不能确切知道查询响应结果的具体大小,但可以测试得到每个请求完成所需要的具体时间,然后利用跨站搜索攻击中提到的response-length inflation技术,根据不同的空响应(empty response)和全响应(full response)查询,得到不同的响应时间差异,然后根据这种时间差异来对查询结果作出可能的判断。例如,有效查询出某个漏洞报告的时间,可能会比无效查询响应的时间慢得多。
然而,要获得比较高的可信度,简单地抛出一个查询请求是远远不够的,可能需要对同一个页面做无数次的请求,同时,测出其各个请求的平均响应时间,以此才能发现可靠的漏洞利用。
这种场景下,缓存API(Cache API)就可以派上用场了,只需发出一个请求,就能重复计算响应到达缓存之间的时长,以此能确定地推断出搜索查询结果是否可有效返回想要的漏洞报告。
换句话说,较小的响应消息要比较大的响应消息所需要的缓存时间少。鉴于缓存API(Cache API)几乎没有时间限制,而且还非常快,我们可以对同一个响应进行多次的缓存和测量,然后,把其与空搜索响应的测量结果进行比较,这样就能间接区分出大响应和小/空响应了,之后,可以进一步过滤掉硬件和网络差异,来提高漏洞利用场景下的速度和可靠性。具体可参考漏洞利用代码 – gist.github: exploit code
结尾
最终,经过测试,我在Monorail服务中发现了这种跨站搜索攻击可应用的三个点,上报给谷歌之后,分别被分配给了三个不同的CVE漏洞编号:CVE-2018–10099、CVE-2018–19334 和 CVE-2018–19335,按照谷歌赏金政策,这三个漏洞各值$3133,7美金,我因此收获了共$9401.1美金的奖励。
参考
[1] Commit fixing the CSRF in Monorail’s CSV file download .
[2] Commit fixing the duplicated columns bug.
[3] Commit disallowing double grid axes and Cc axis.
[4] Commit preventing request inflation through the groupby parameter.
*参考来源:medium,clouds编译