使用马尔科夫链进行Android恶意软件检测
导语:本文将介绍如何使用马尔科夫链进行Android恶意软件检测。
如果你和某人聊天,如果他们给你说了一堆“aslkjeklvm,e,zk3l1”你完全听不懂的词语,显然他们是在胡言乱语。但是,在计算机中,你该如何教电脑识别类似的乱码呢?然而更重要的是,我们为什么要为这个问题烦恼?我见过很多安卓恶意软件,其中有很多包含我们不认识的乱码字符串,无论是代码中的文字,还是签名中的类名,等等。我的想法是,如果你可以对乱码进行“量化”,那这些乱码将会是机器学习模型中的一个很好的特征。我已经测试了我的想法,所以在这篇文章中,我将分享我的成果。
什么是马尔可夫链?
你可以阅读维基百科上的解释,但不是每个人都有时间阅读完这种篇幅很长的解释。简单的说,你用了很多字符串来训练一个马尔科夫链模型。一旦训练好,你可以给模型输入一个字符串,模型就会告诉你它训练的字符串是什么意思。这个过程称为获取字符串的概率。
马尔可夫链非常简单。我使用的代码可以在这里找到:https://gist.github.com/CalebFenton/a129333dabc1cc346b0874407f92b568
它是基于Rob Neuhaus的Gibberish Detector编写的。
实验测试
我一直在努力改进我在安卓恶意软件检测器——Judge中使用的模型。创建一些基于马尔科夫的特征很容易,然后将这些特征放入模型中进行不断的训练。但我想要一种更加科学的方法。每个人都会认为科学的世界是五彩斑斓的,但想象往往是美好的,真正的大部分科学研究的幕后花絮,其实是非常乏味而艰辛的。为了做出有关于哪些特征最有效以及这些特征是否有用的数据驱动决策,我对实验进行了大量的记录并保留了所有的数据。希望这些数据能对其他人有所帮助。
我一般是从收集数据集中的所有字符串作为实验的开始。我所选择的数据集包含了约185,000个样本,其中约一半是恶意的样本。恶意应用程序来自各种地方,但大部分来自于VirusTotal,其中有20多个白样本应用程序。白样本应用程序可能更加多样化,并包含多种语言的字符串。
收集完字符串后,我在从白样本应用程序中提取的字符串上训练了马尔可夫模型。对于每次出现的字符串,我都会用这些字符串进行模型训练。训练完成后,模型就会识别出可能的合法字符串或者非恶意字符串。然后,我计算了每个白样本中的字符串的概率,并在曲线上绘制了分布情况。
最后,我使用在白样本中的字符串训练的马尔可夫模型来计算所有恶意字符串的概率并绘制了结果。在我花时间为提取特征而编写任何代码之前,我想知道概率分布是否存在显着差异。如果没有差异,我可能会继续编写代码,因为我就是这样度过我的周末的,但事实证明,这里有一个显著的差异,让我觉得更加自信,因为这说明我提取的特征非常有用。
我的马尔可夫链模型使用了双字母组合,字符串会根据其类别进行标记。以下是模型使用的模式:
@Nullable
private static String getTokenSplitPattern(String stringType) {
switch (stringType) {
case "activityNames":
case "receiverNames":
case "serviceNames":
return null;
case "appLabels":
case "appNames":
case "stringLiterals":
return "(?:[\\s+\\p{Punct}]+)";
case "classNames":
case "fieldNames":
case "methodNames":
return null;
case "packageNames":
return "(?:\\.)";
case "packagePaths":
return "(?:/)";
case "issuerCommonNames":
case "issuerCountryNames":
case "issuerLocalities":
case "issuerOrganizationalUnits":
case "issuerOrganizations":
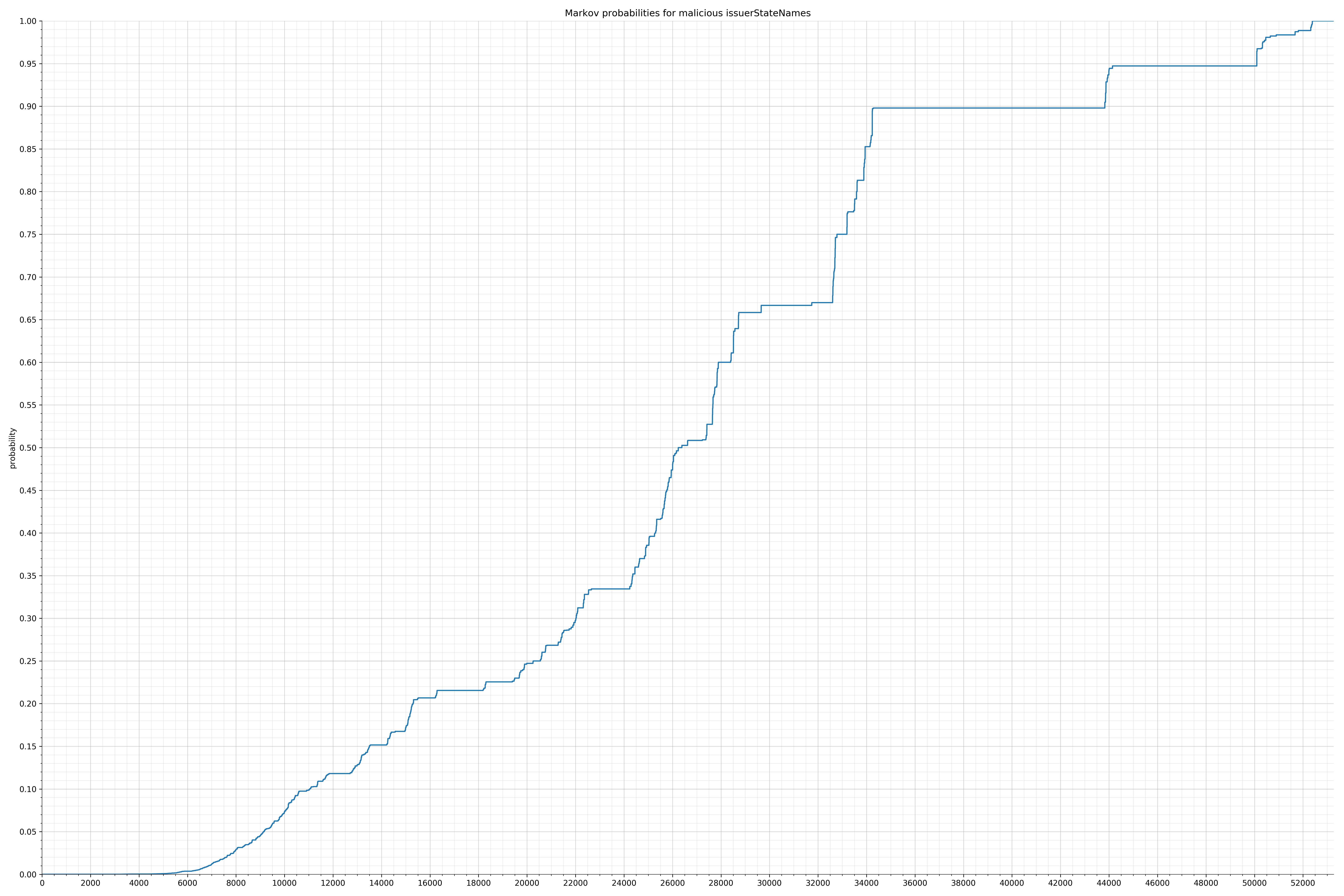
case "issuerStateNames":
case "subjectCommonNames":
case "subjectCountryNames":
case "subjectLocalities":
case "subjectOrganizationalUnits":
case "subjectOrganizations":
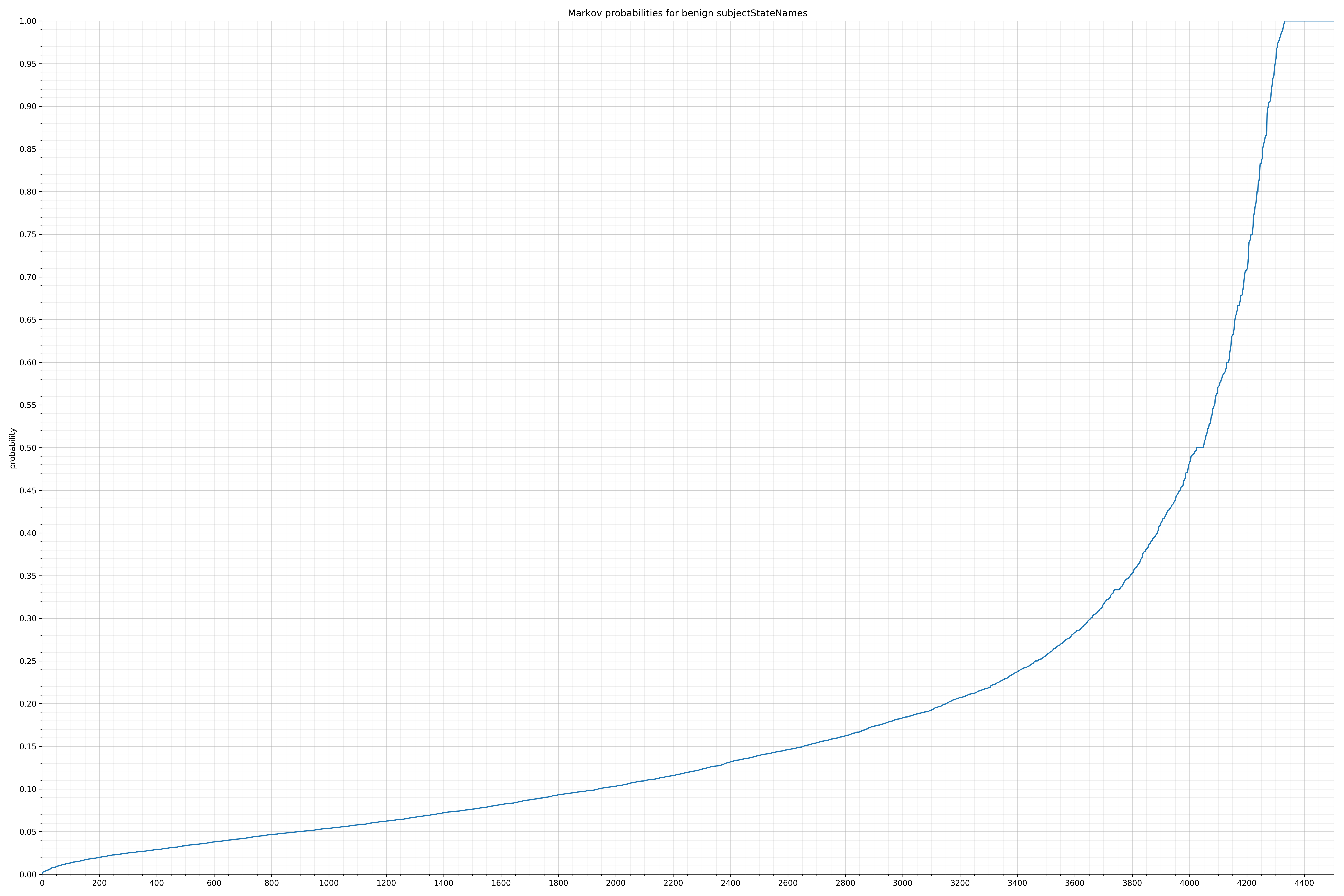
case "subjectStateNames":
return "(?:\\s+)";
default:
return null;
}
}
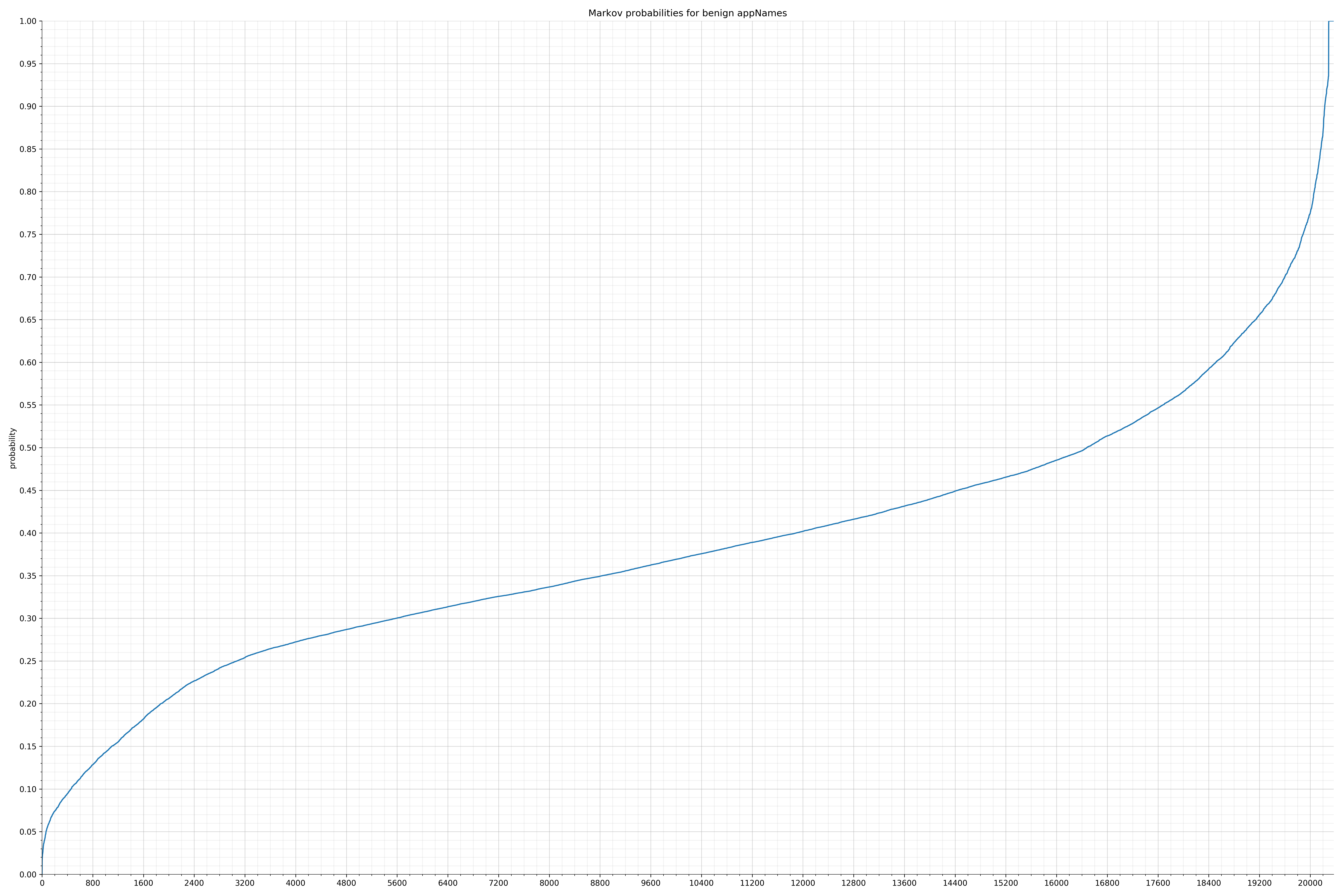
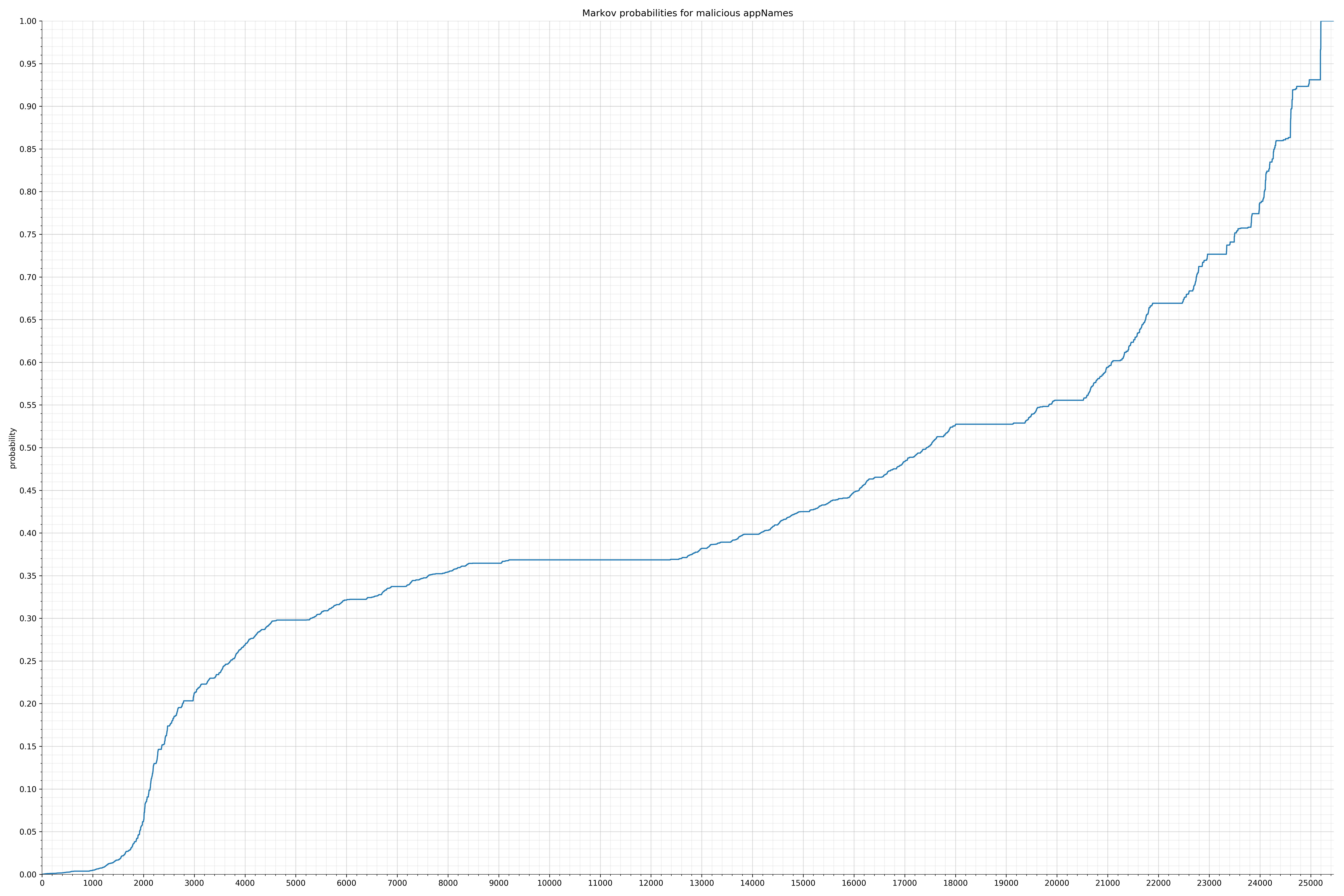
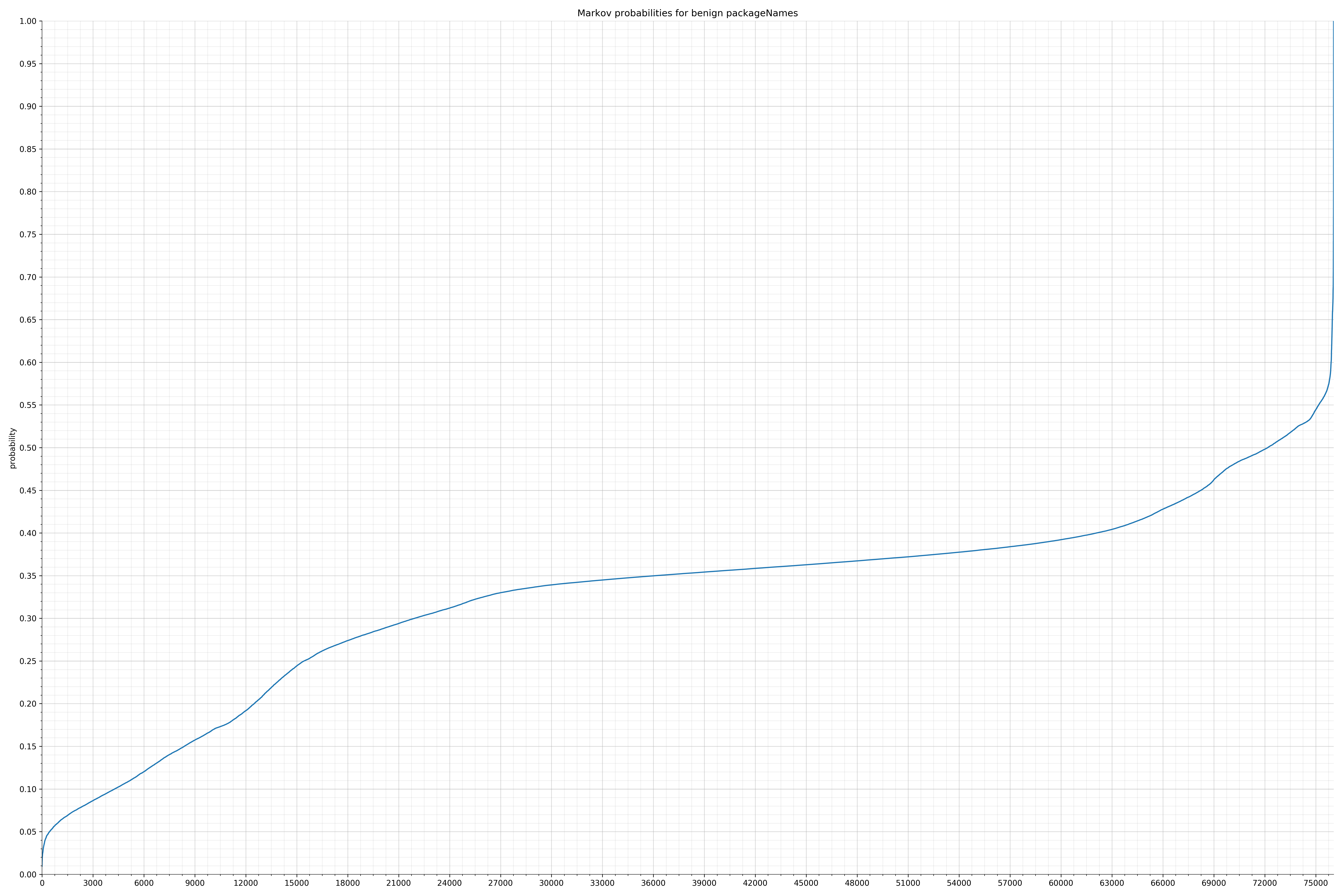
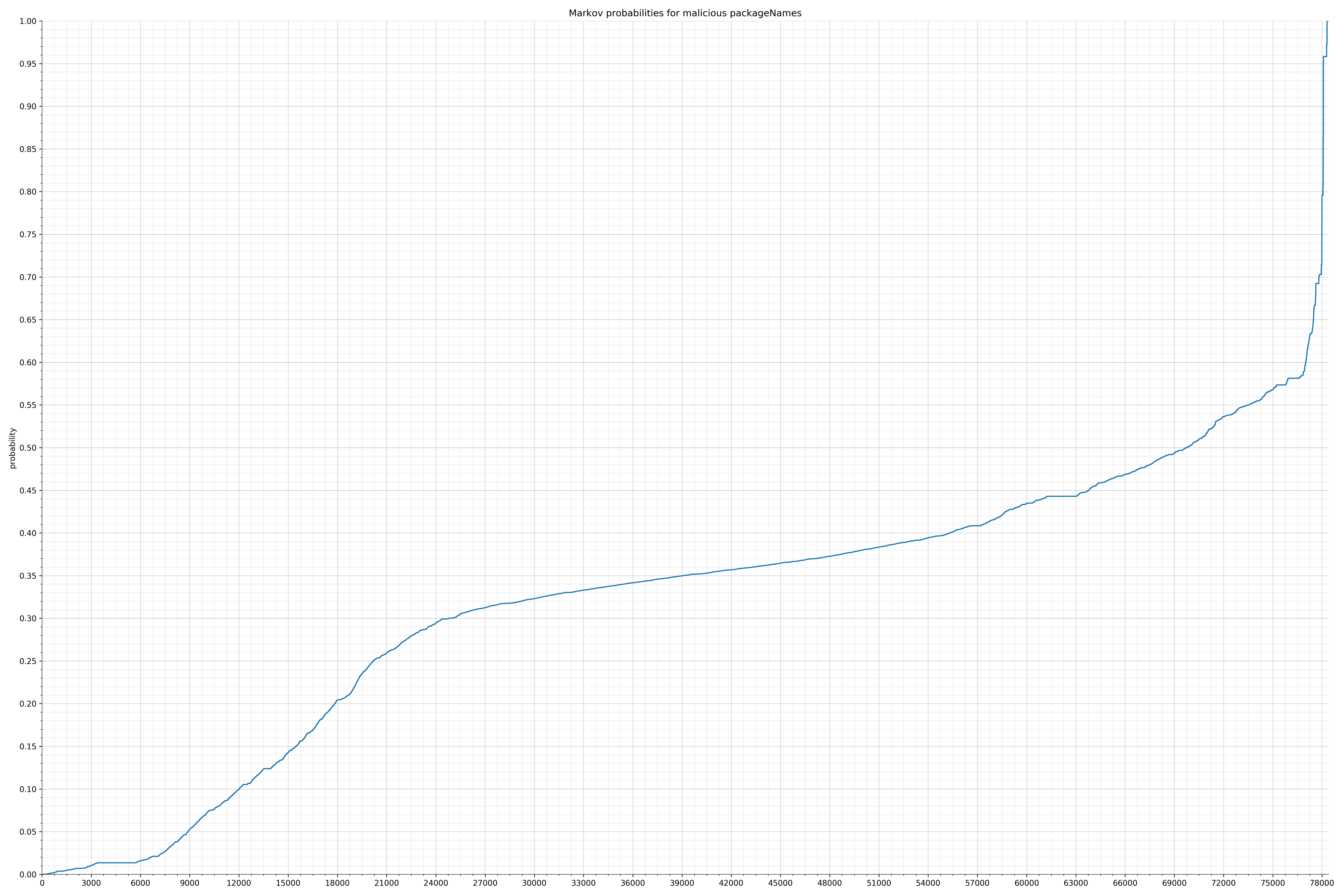
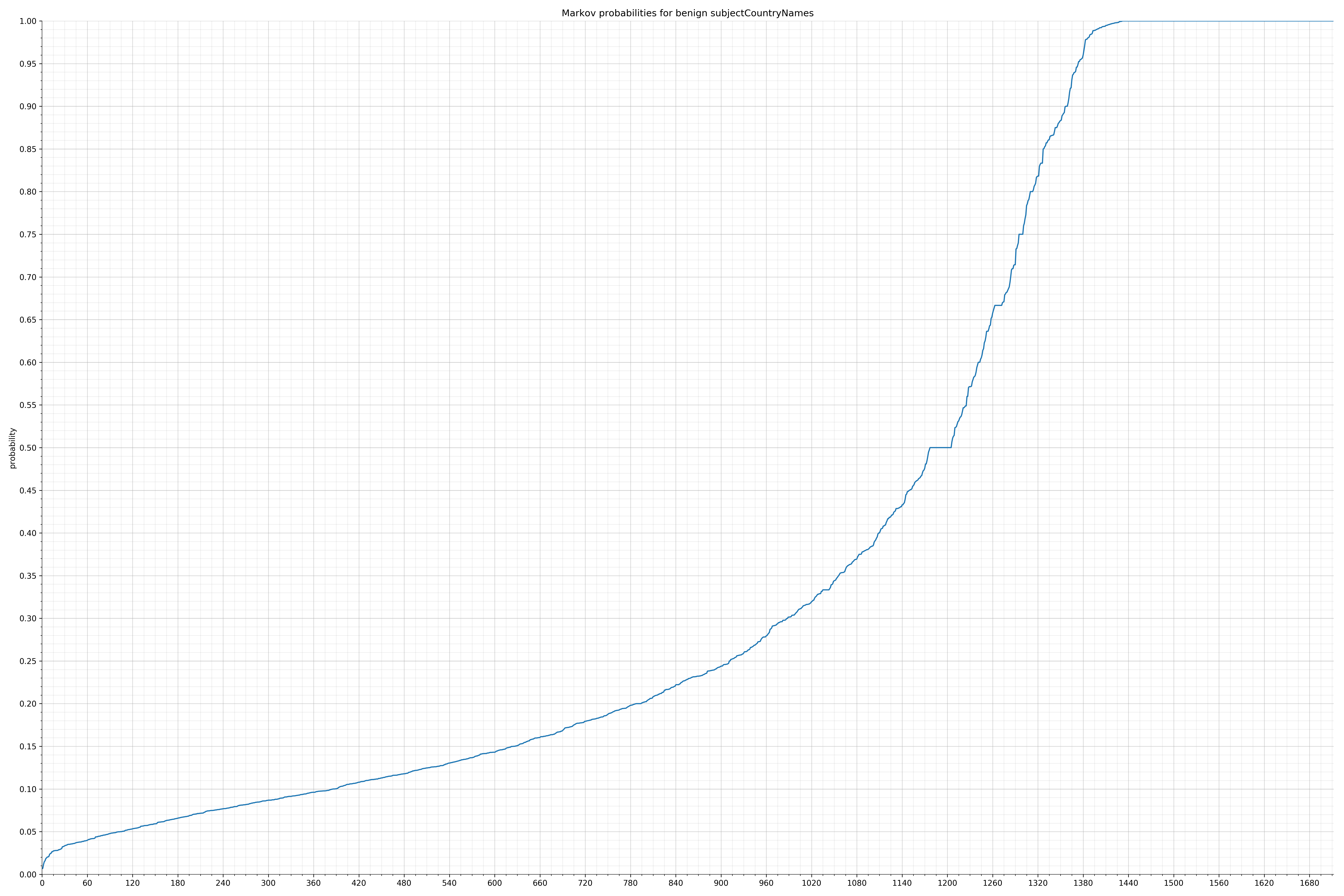
下面列出了字符串的类别和概率分布。
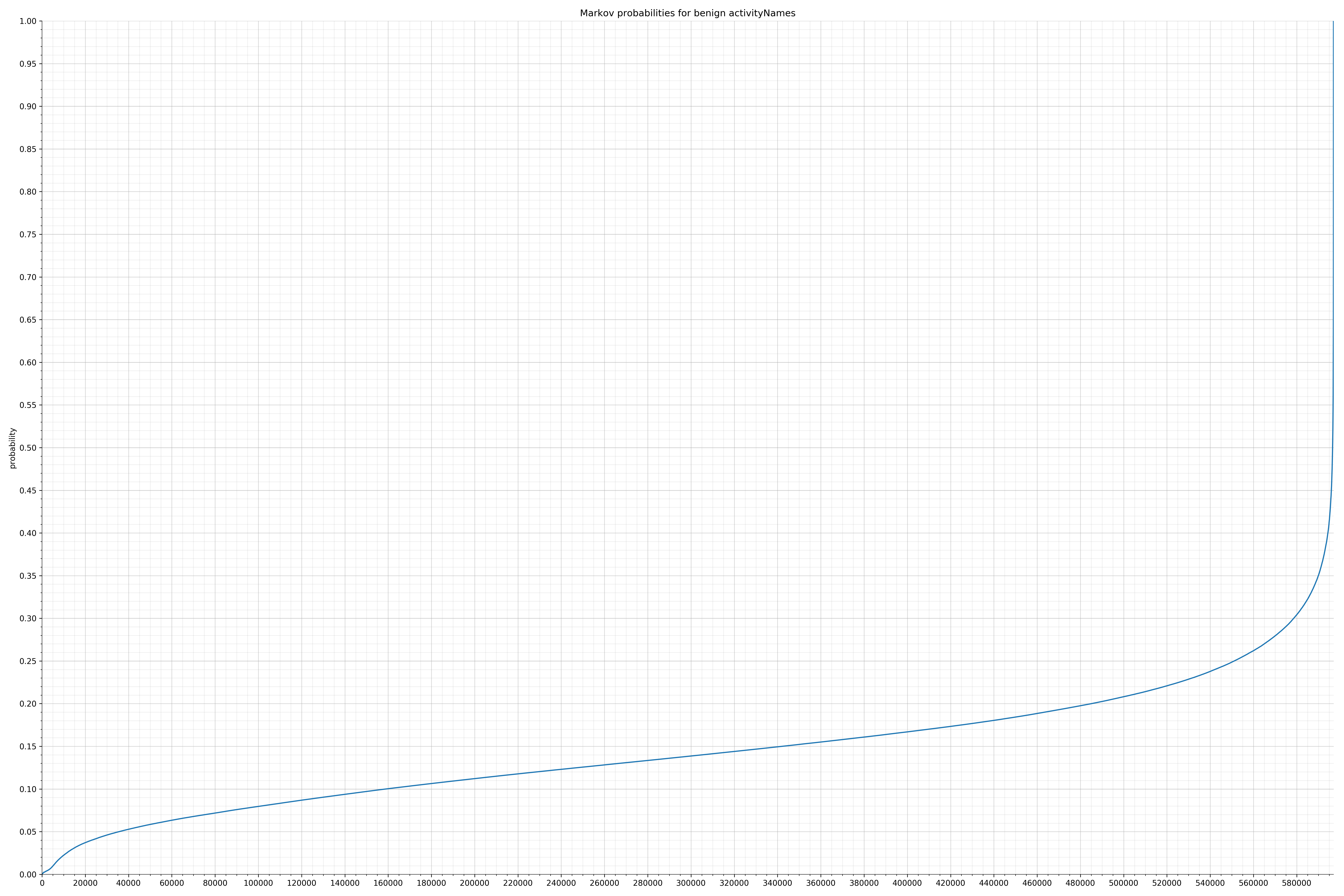
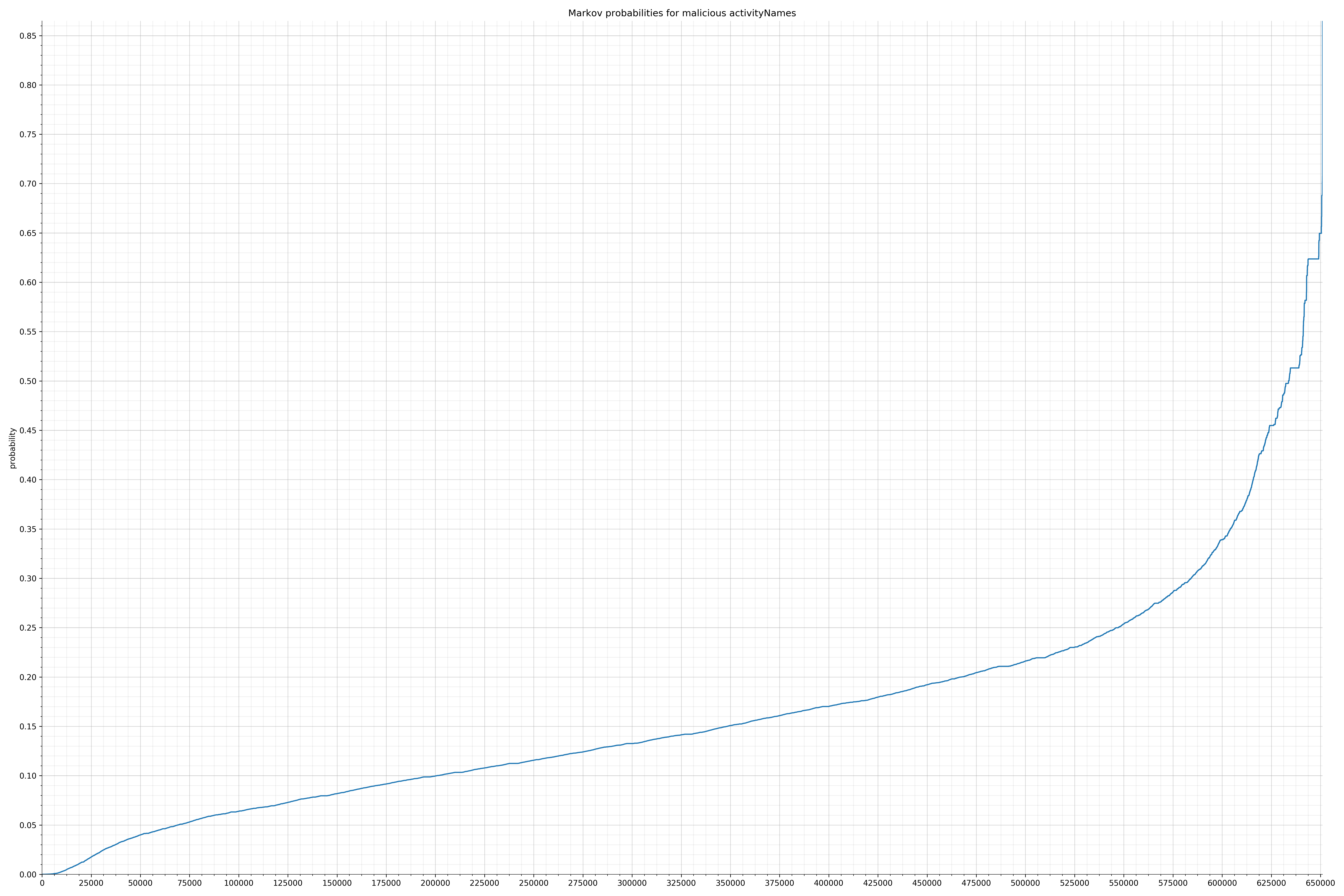
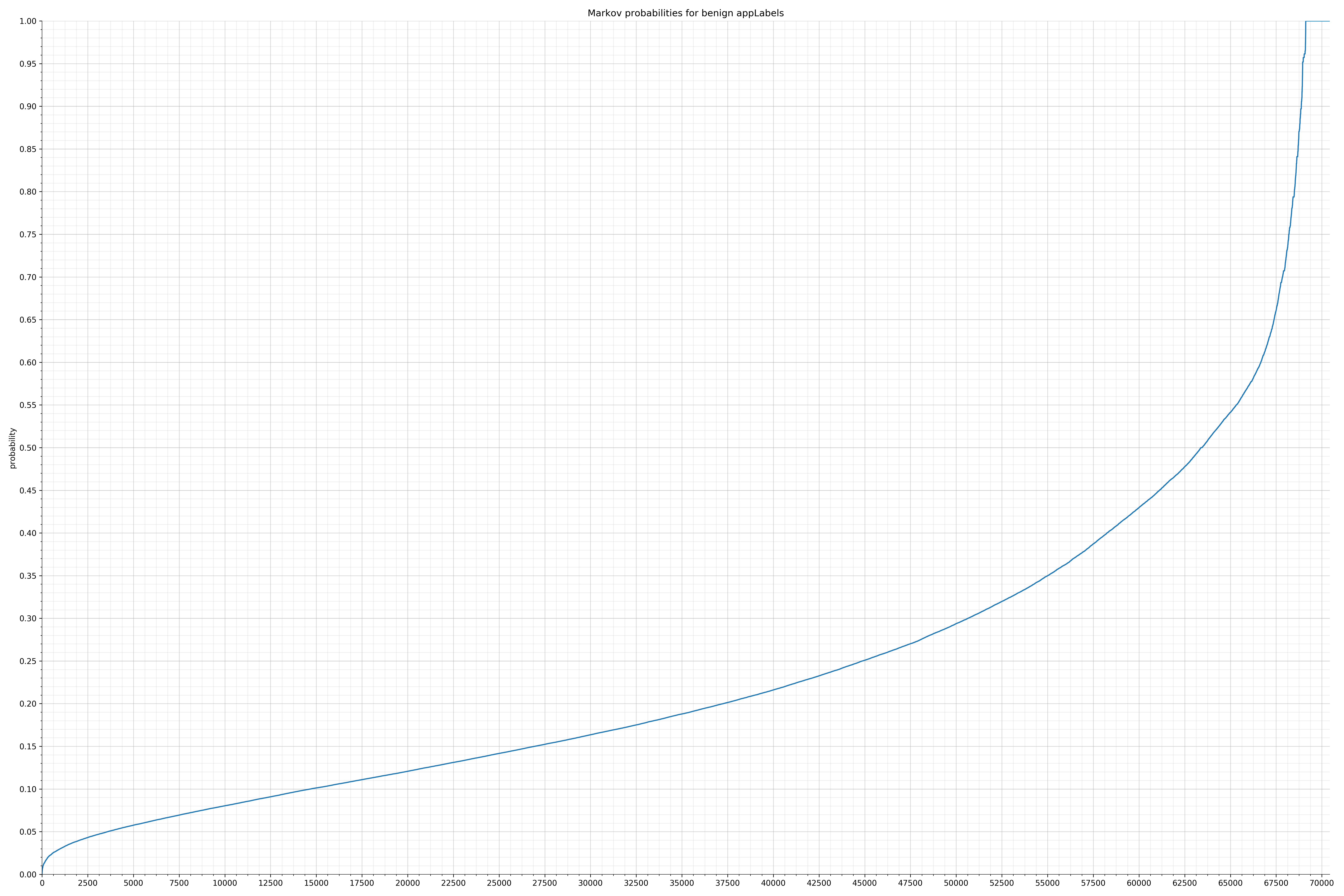
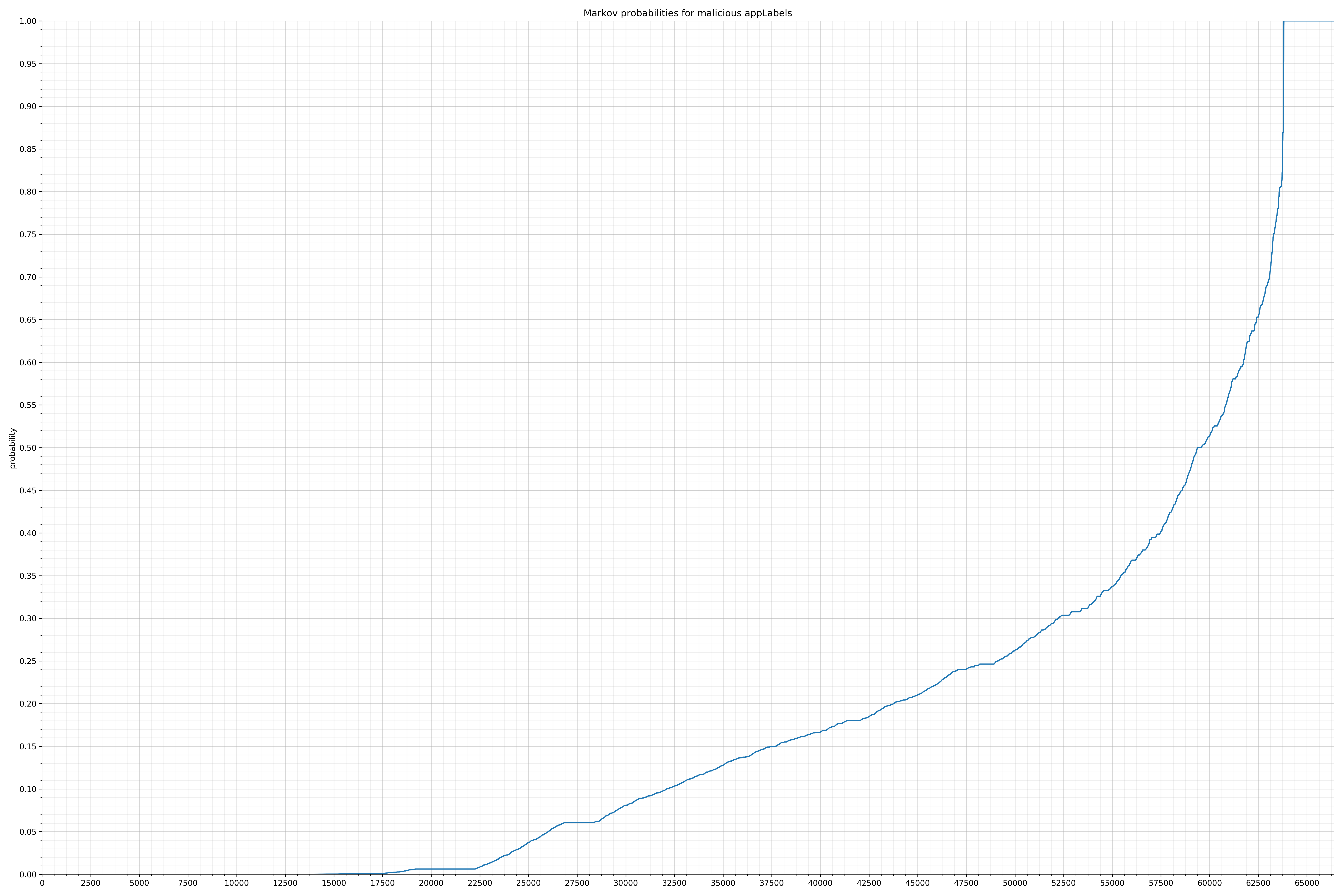
来自Android的清单文件:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
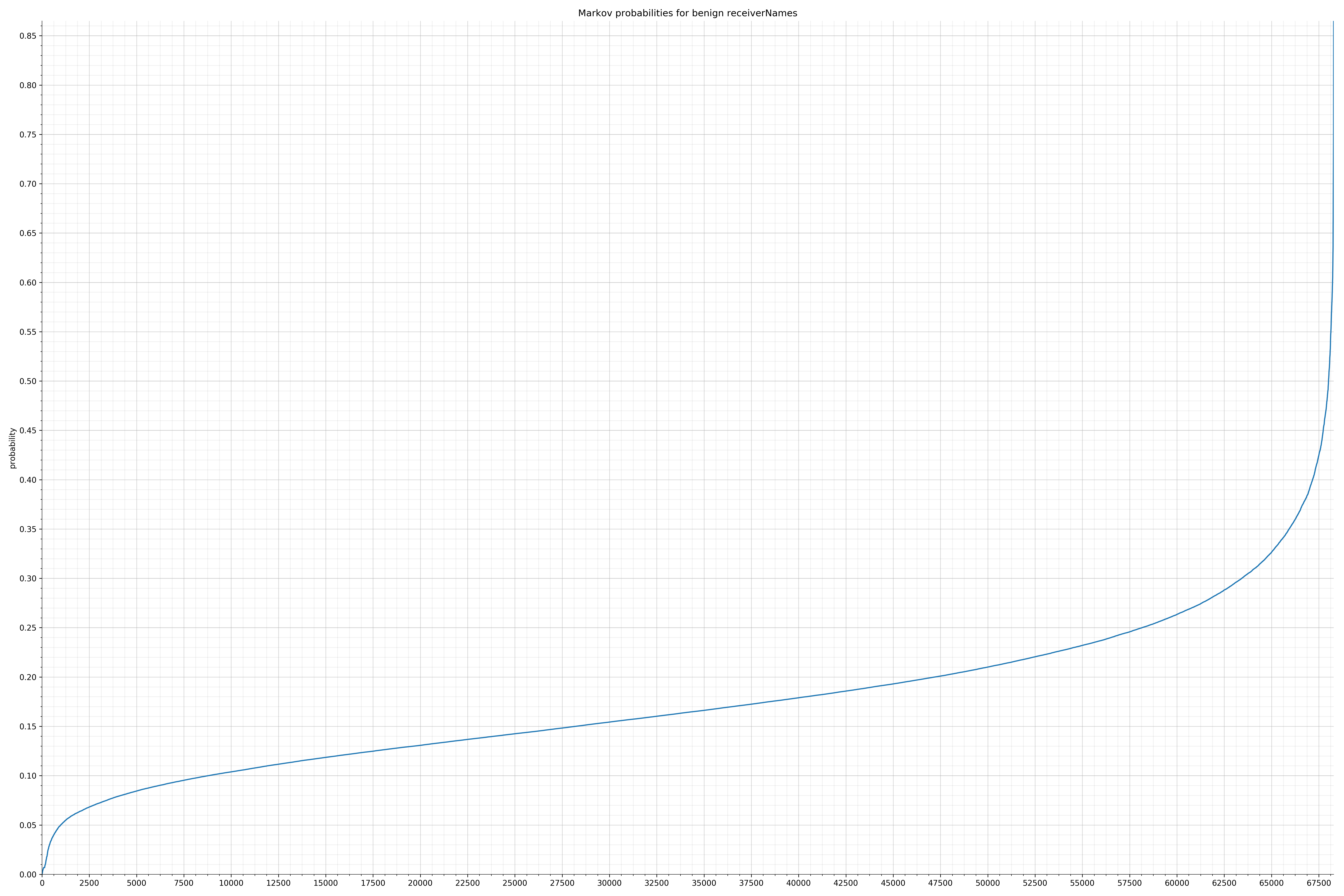{kind=link}
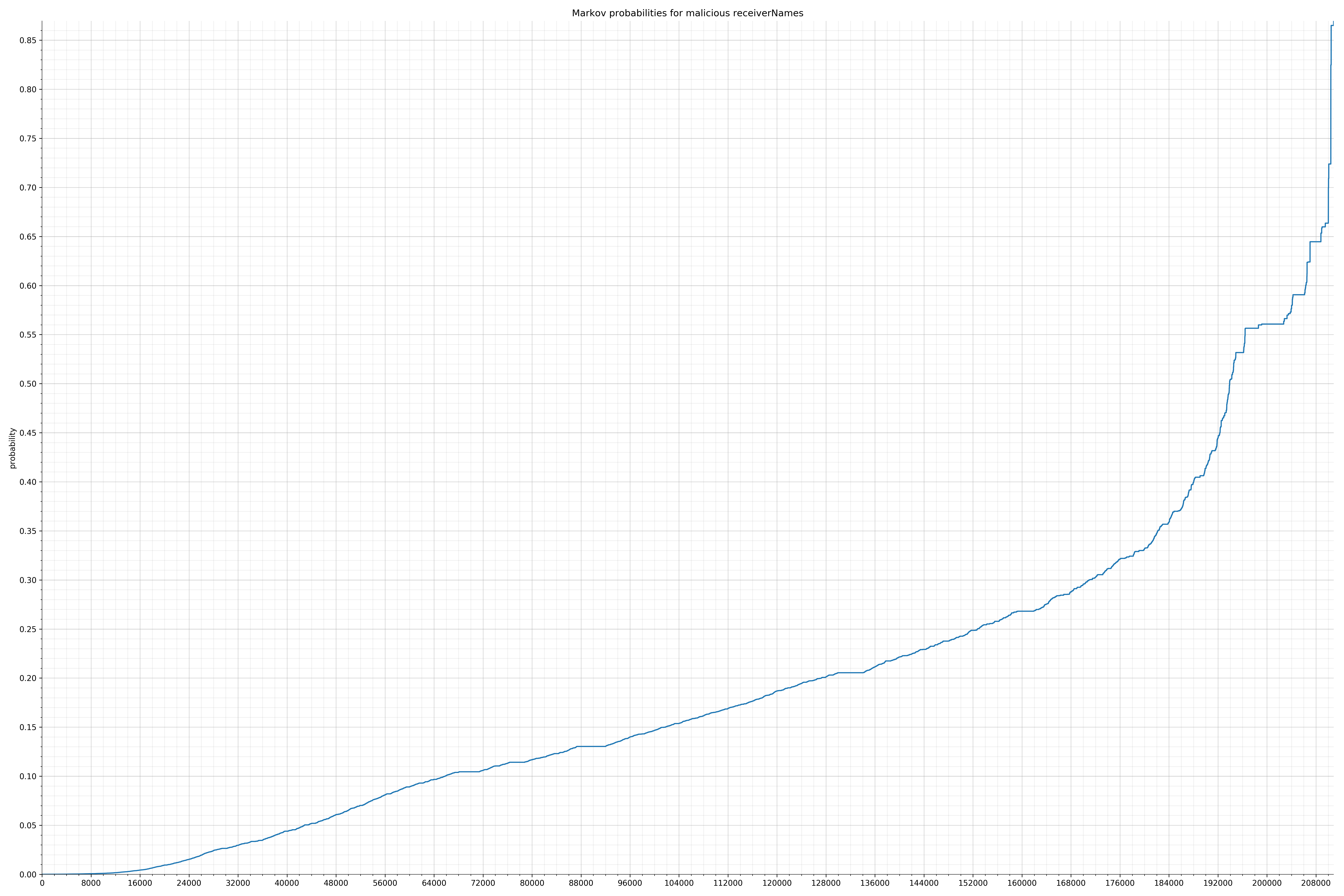{kind=link}
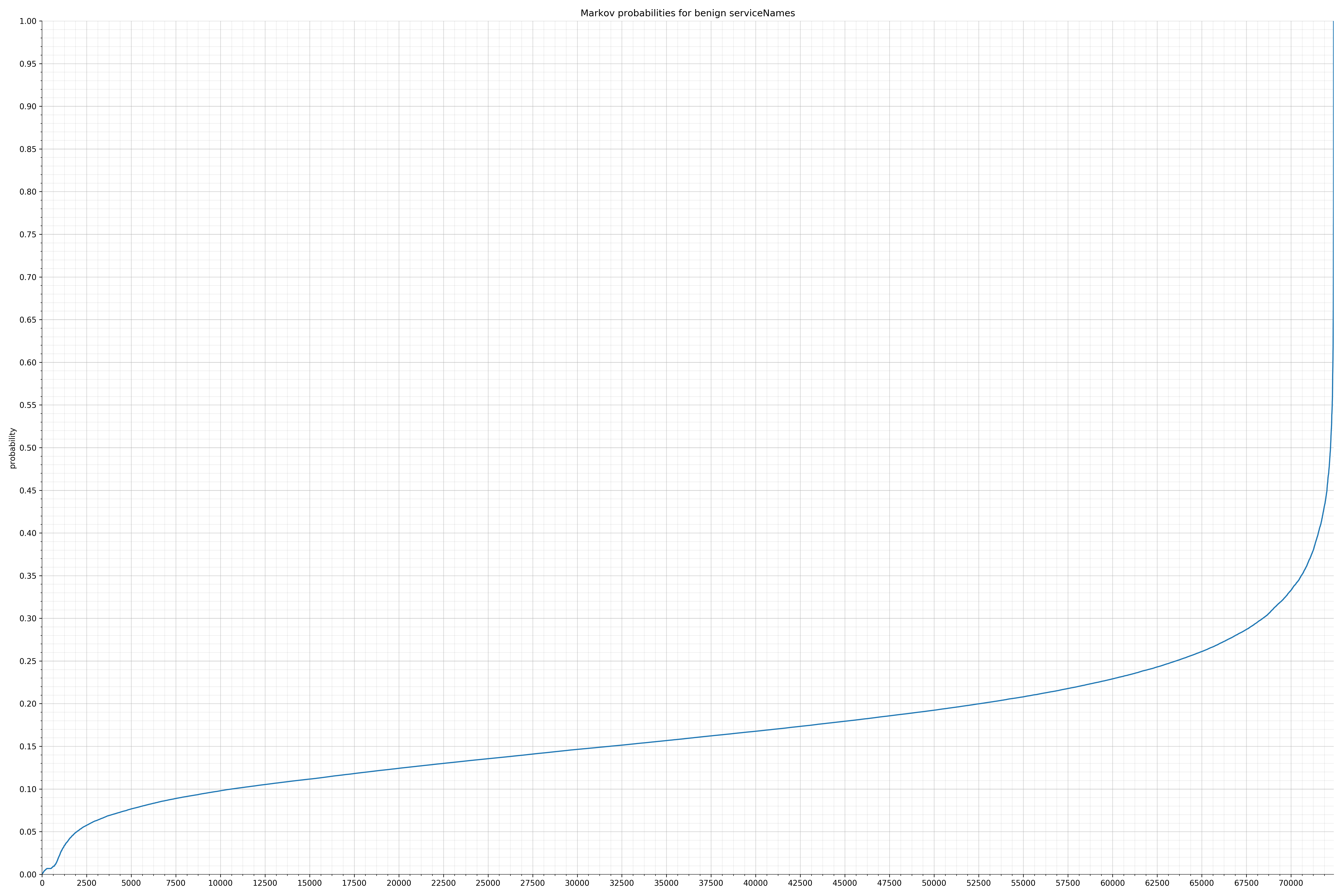{kind=link}
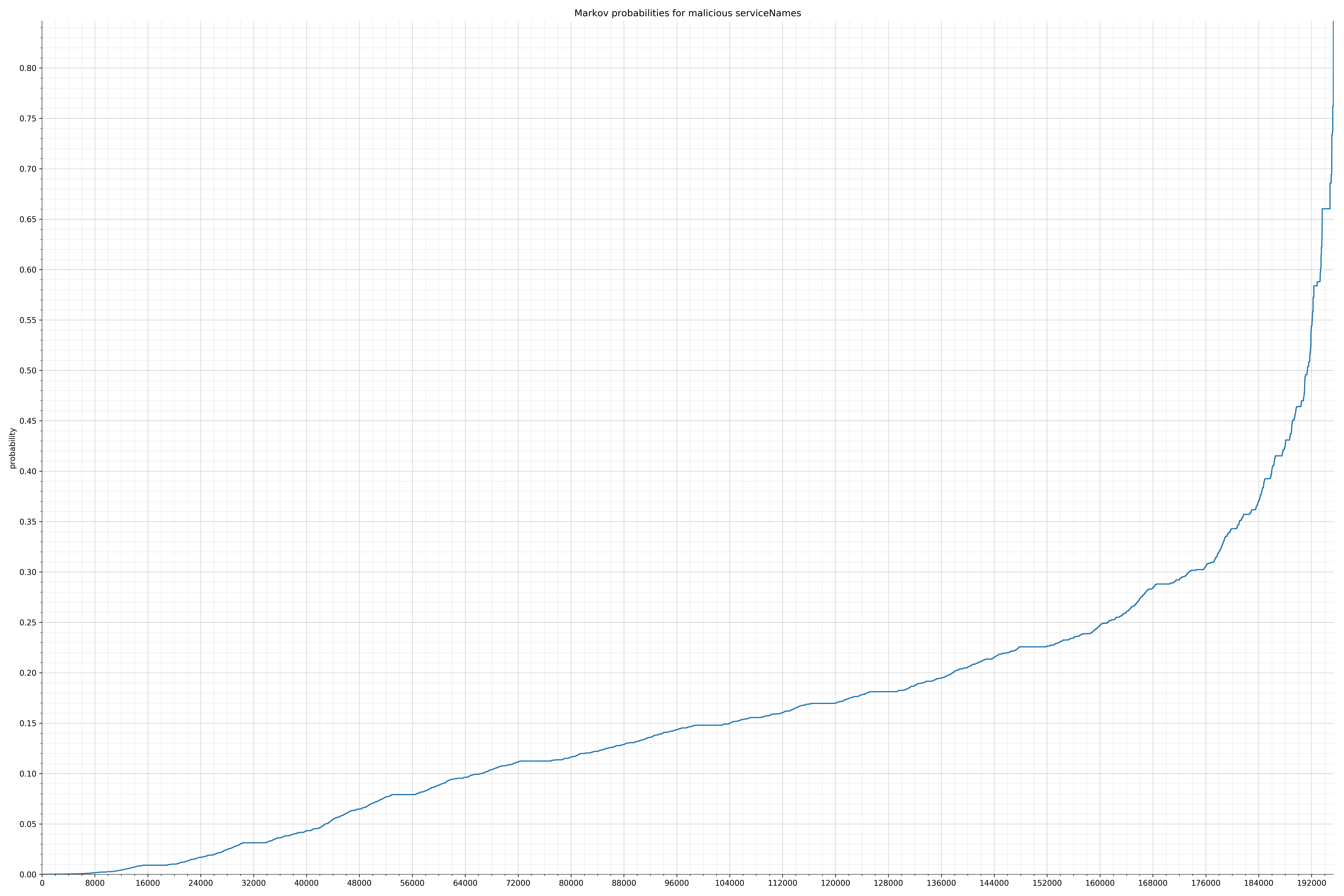{kind=link}
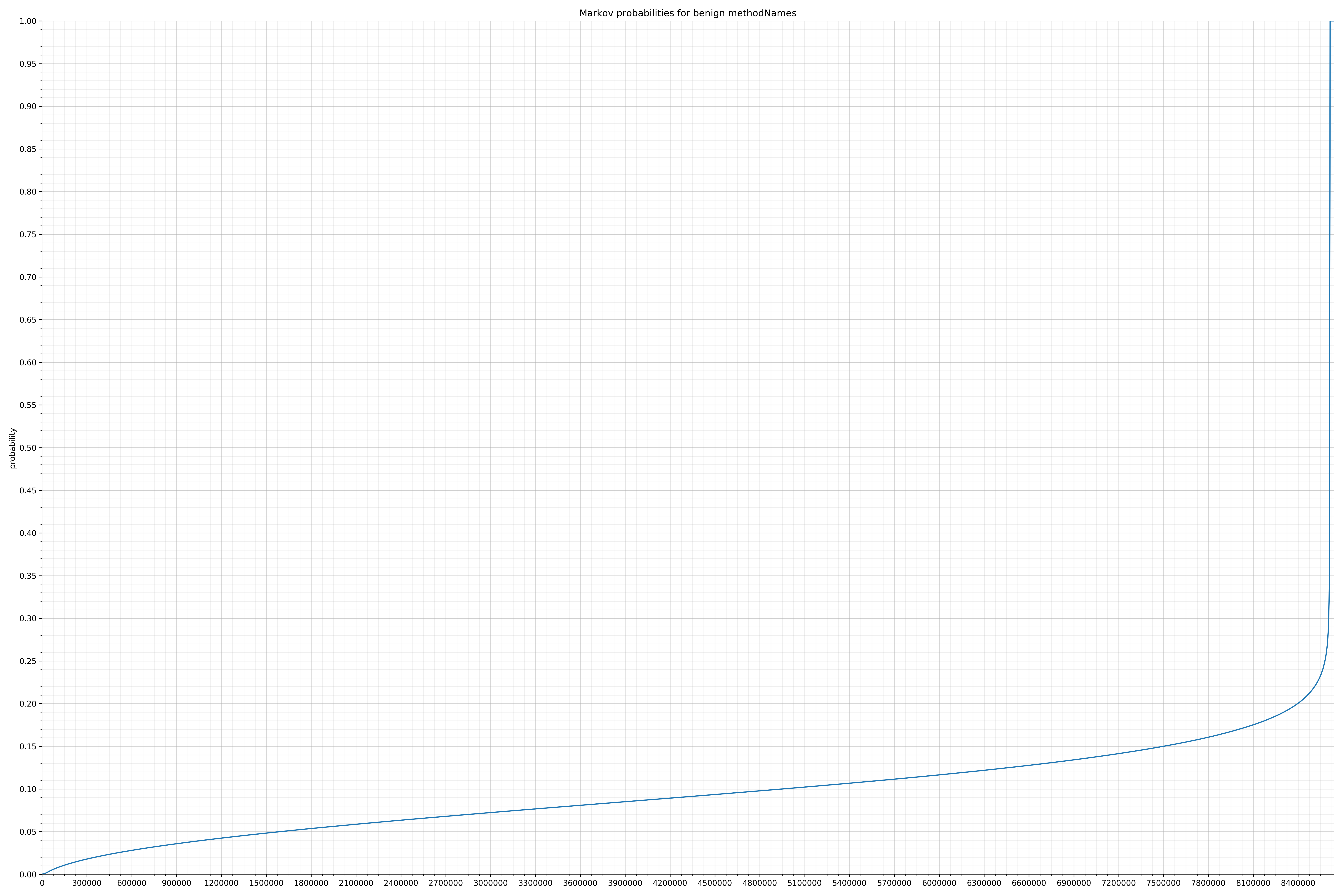
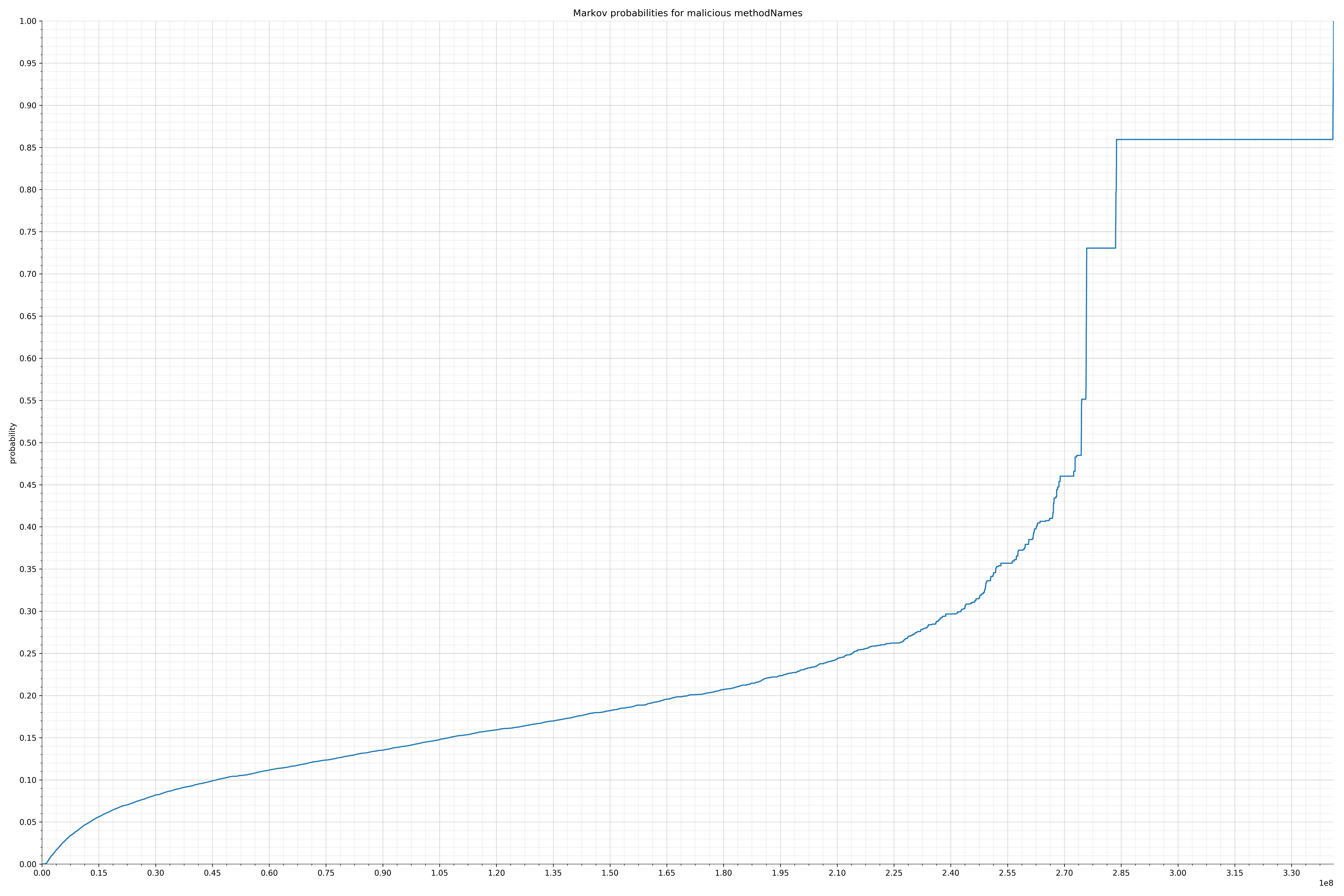
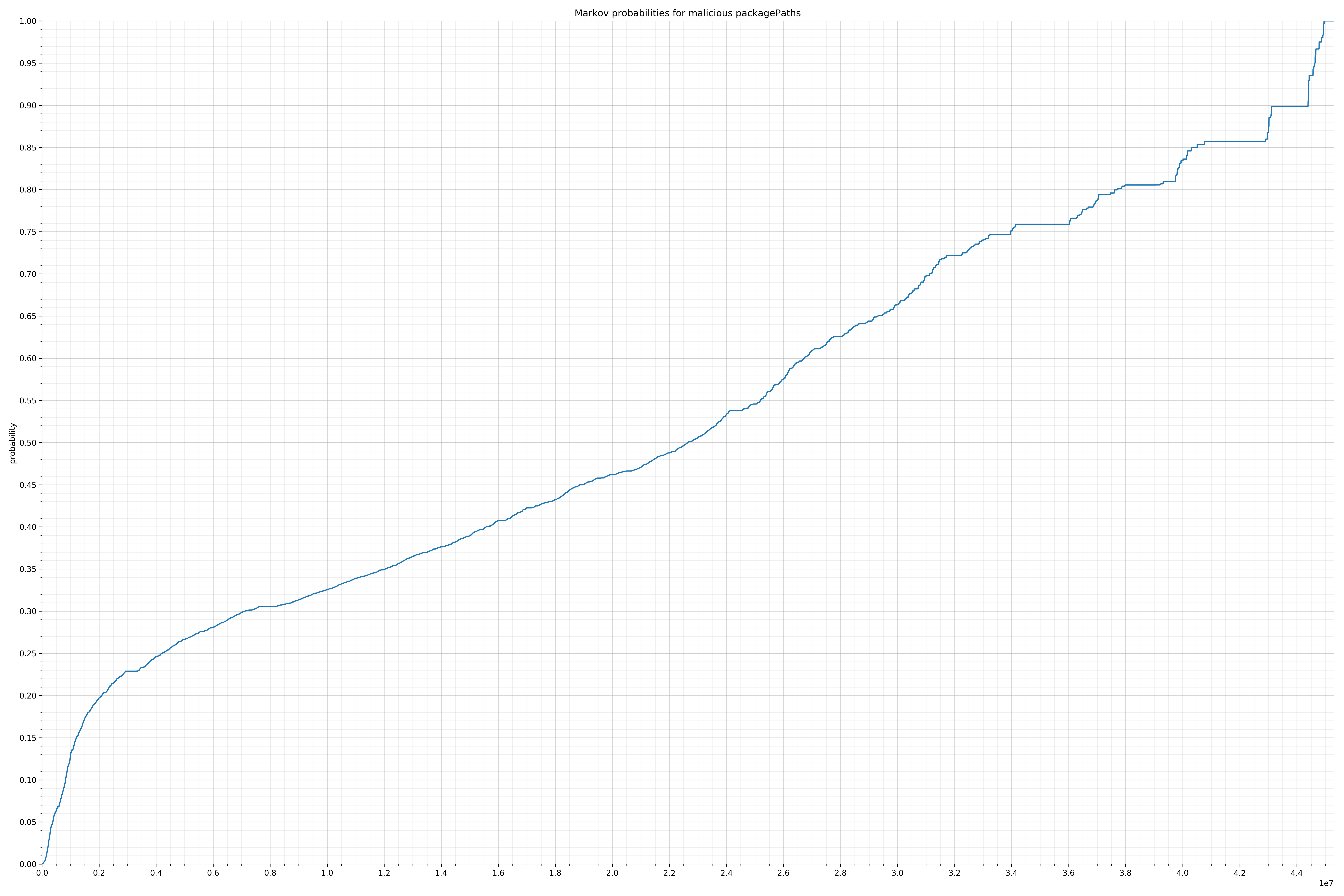
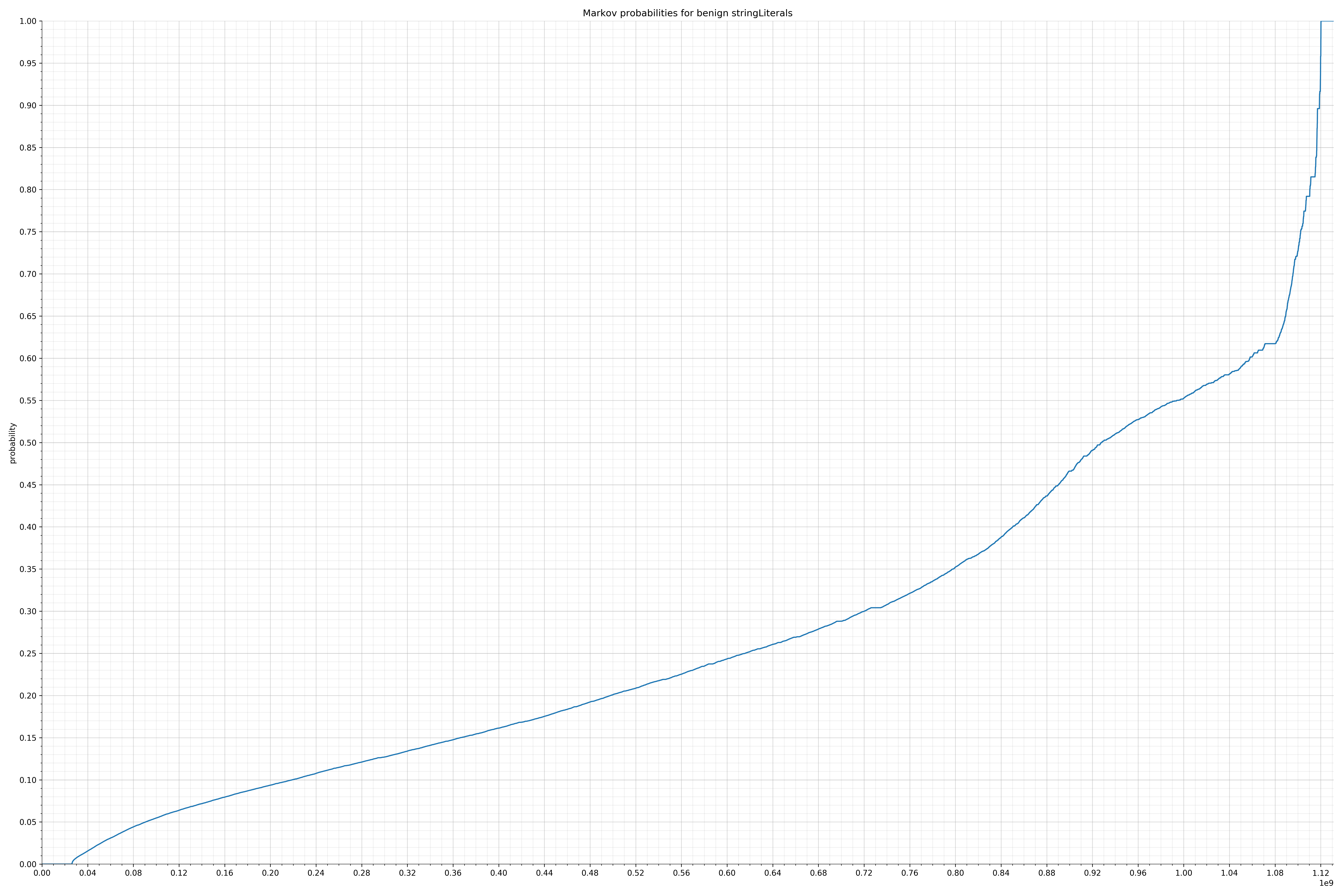
来自Dalvik可执行代码:
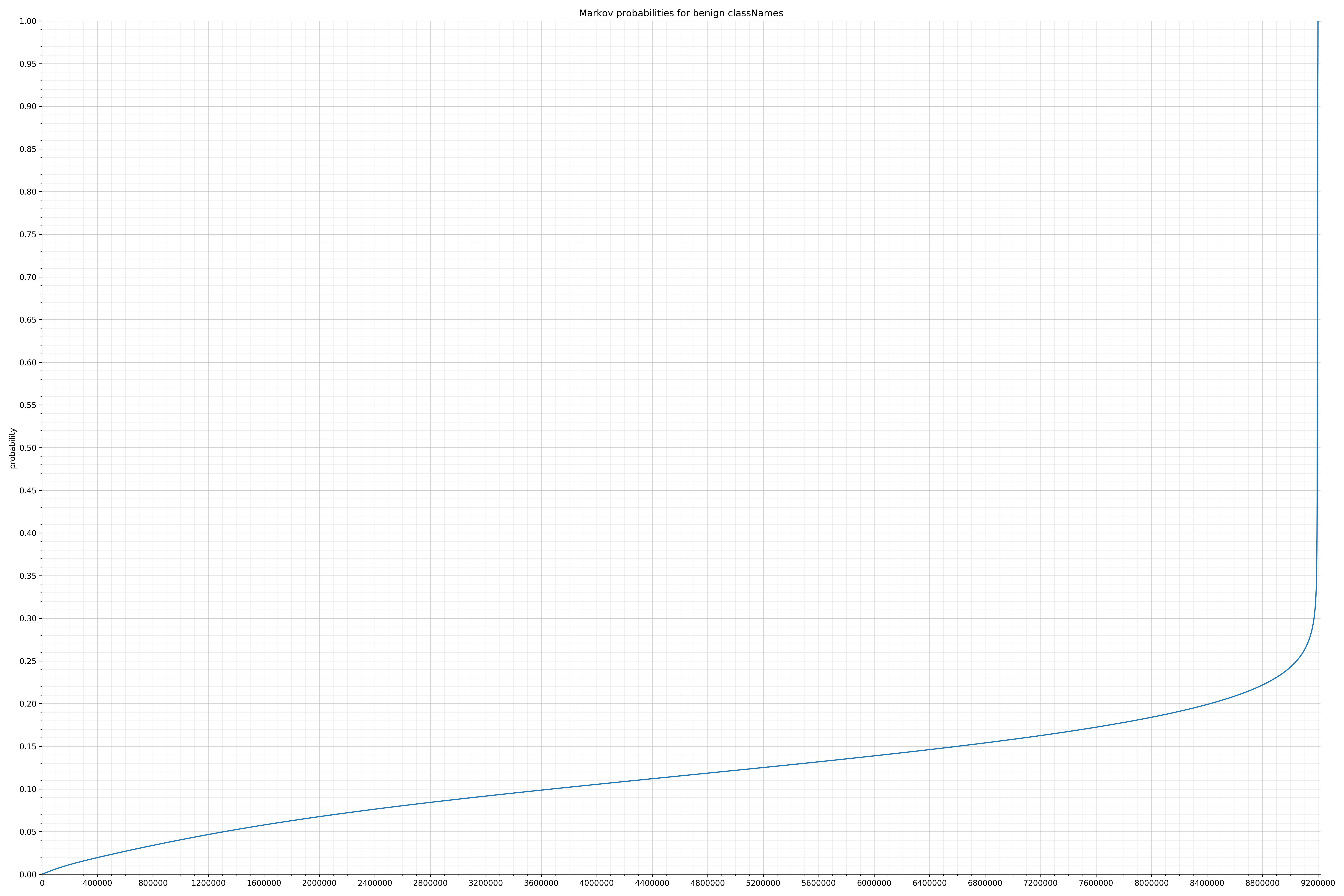{kind=link}
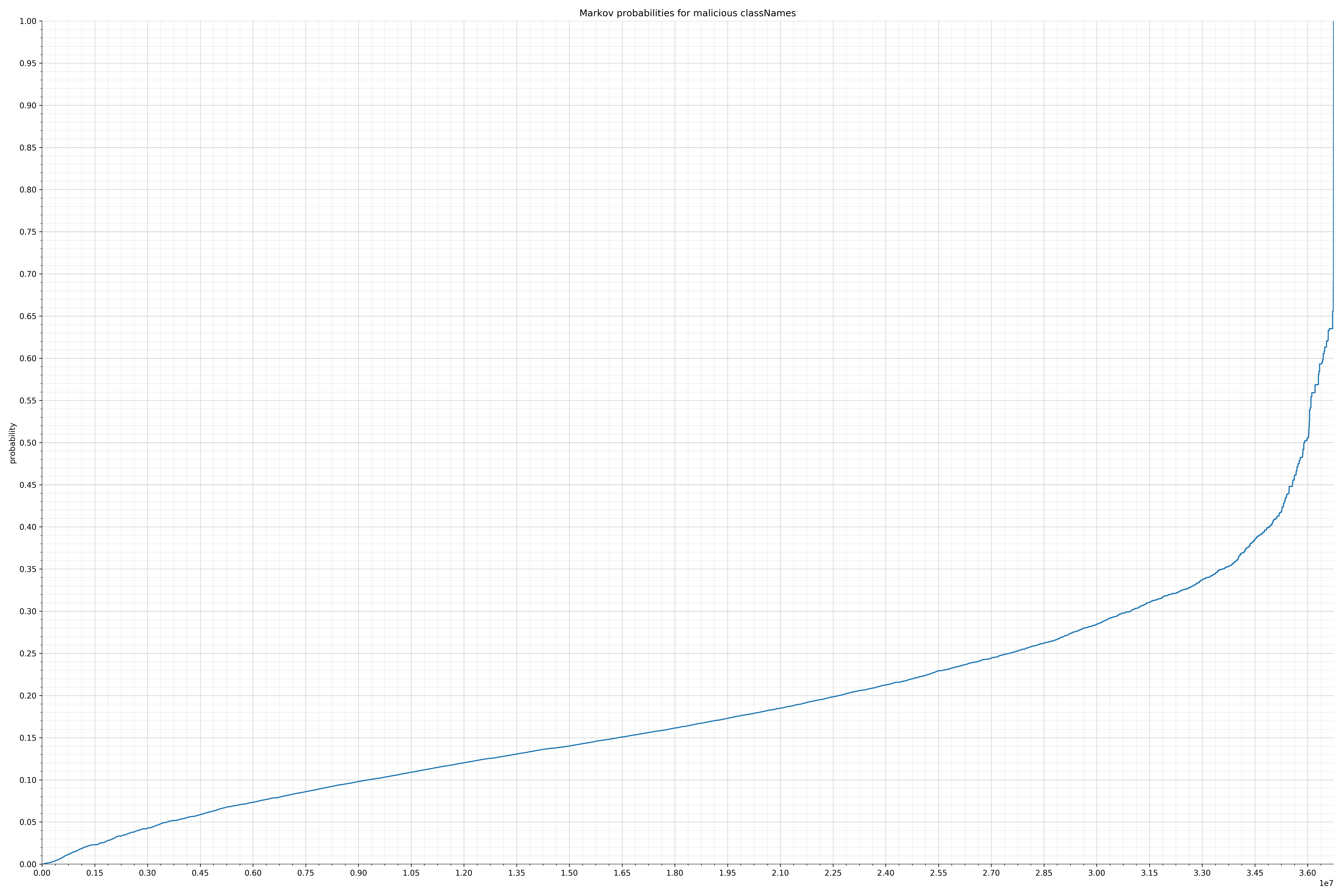{kind=link}
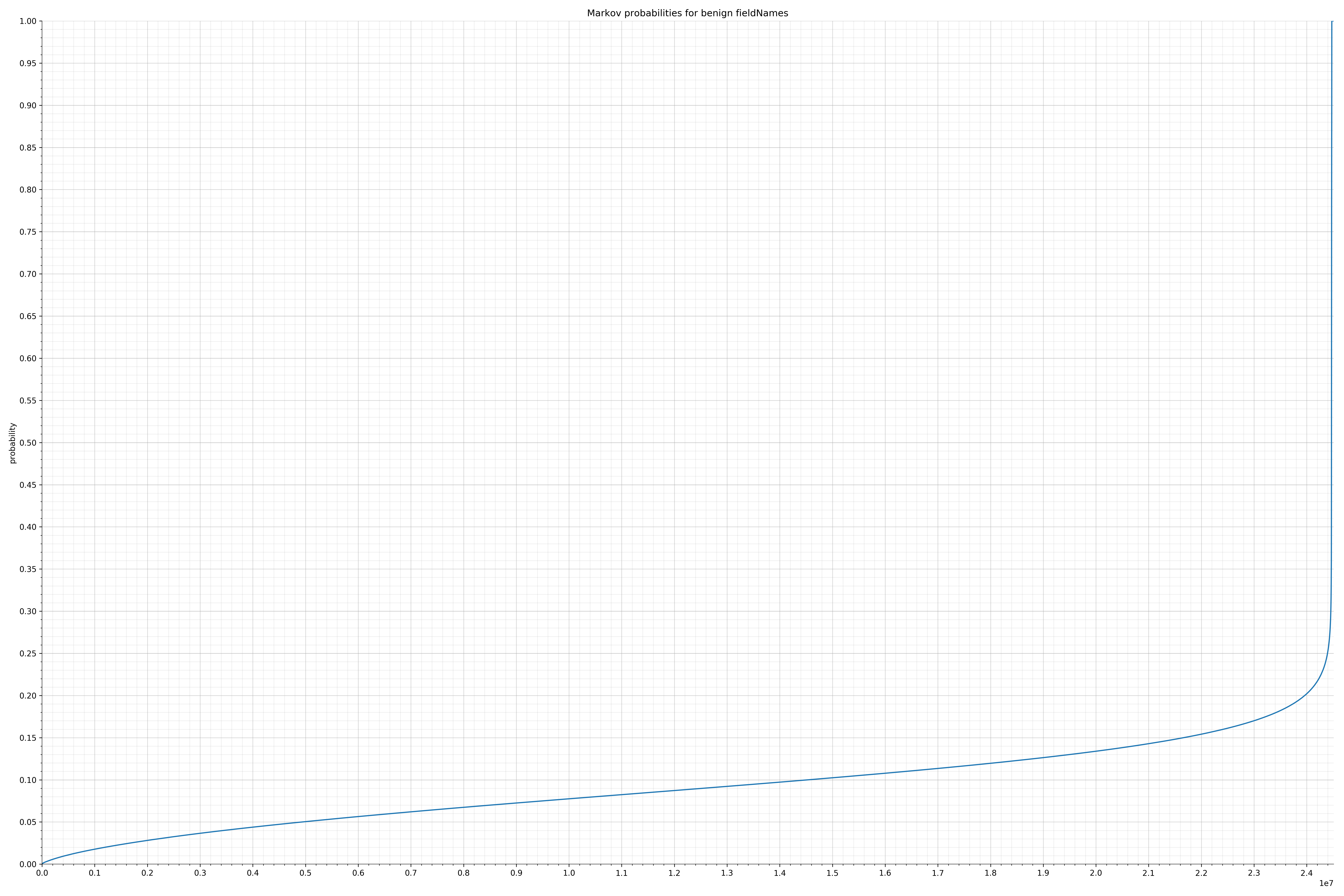{kind=link}
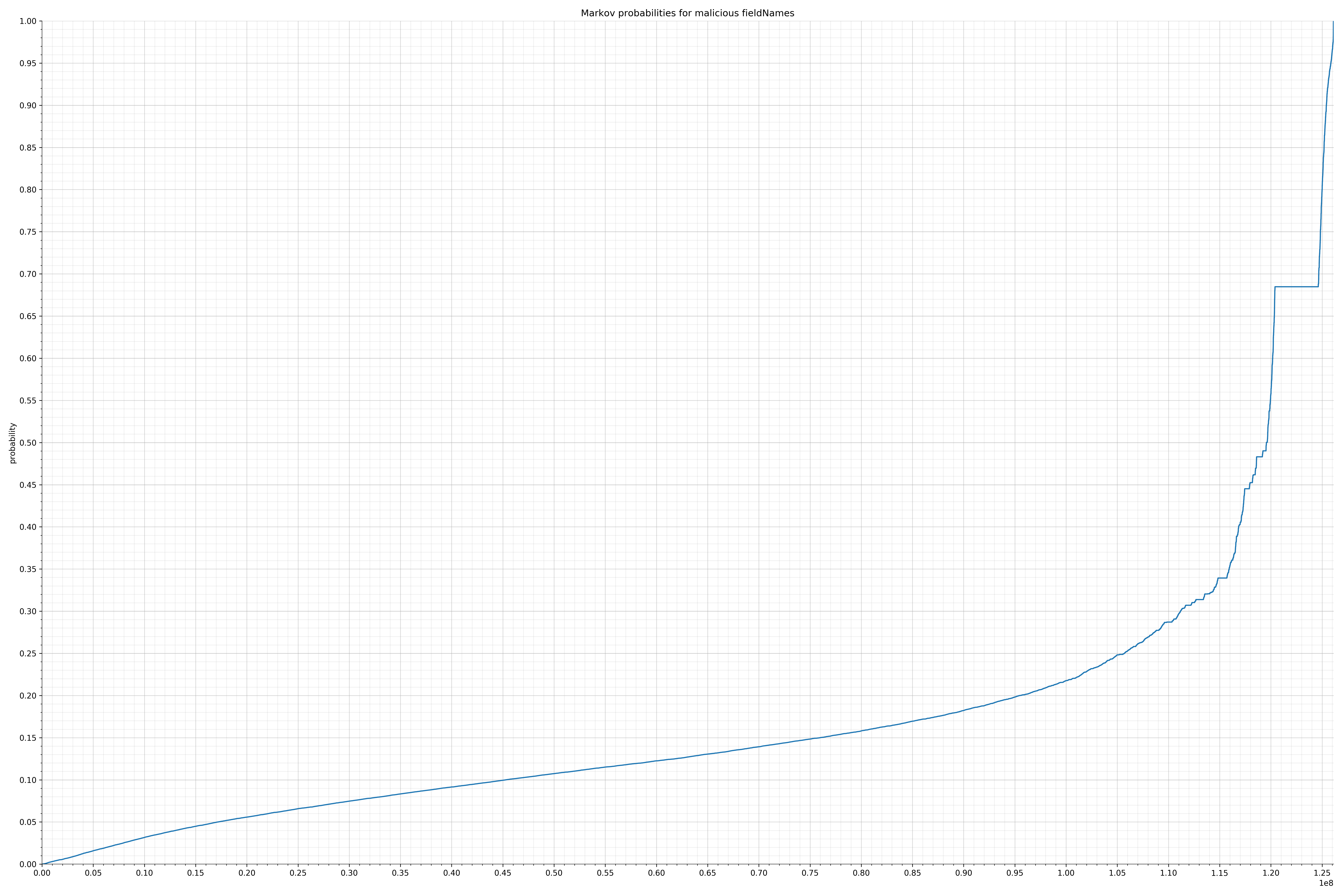{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
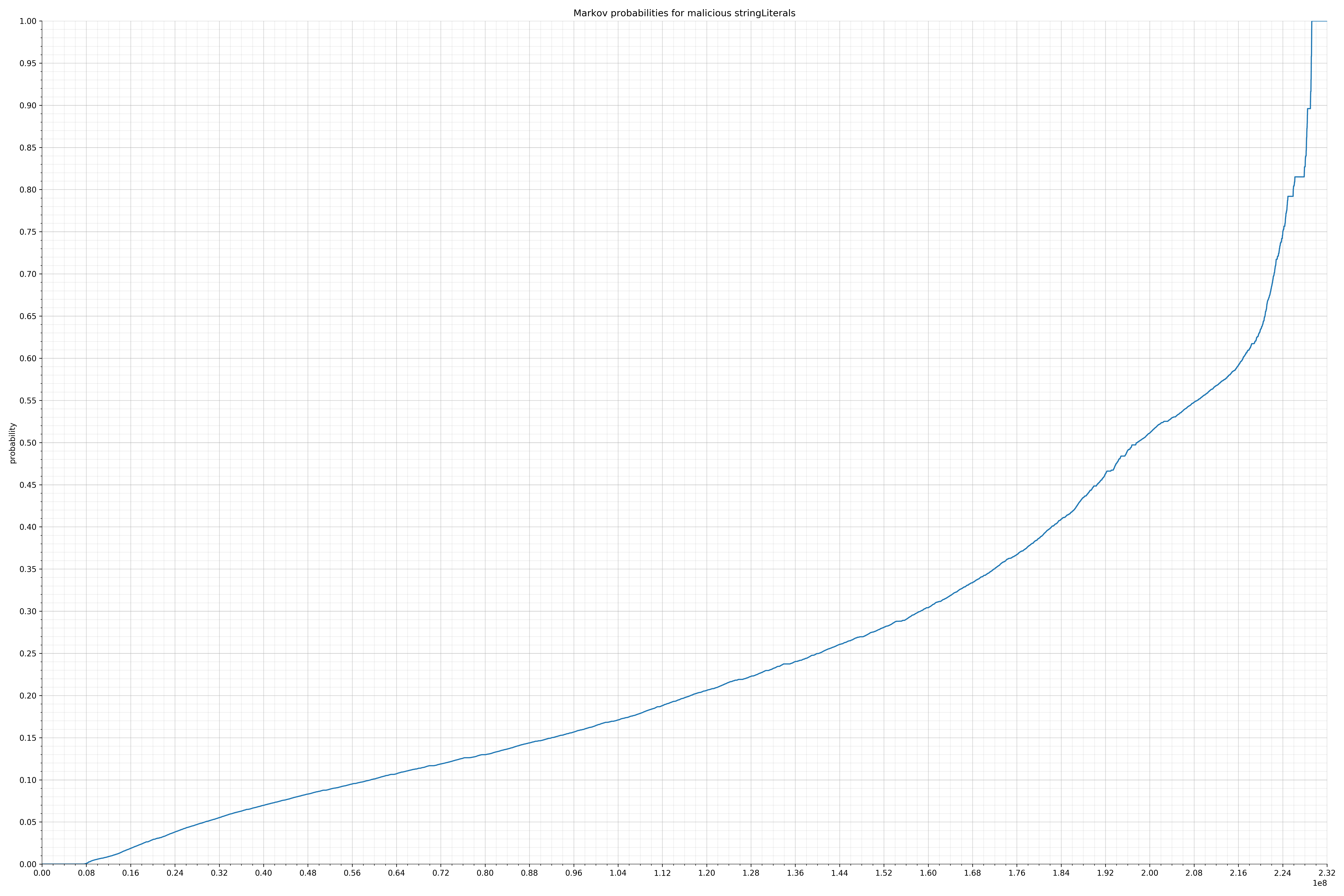{kind=link}
来自签名证书:
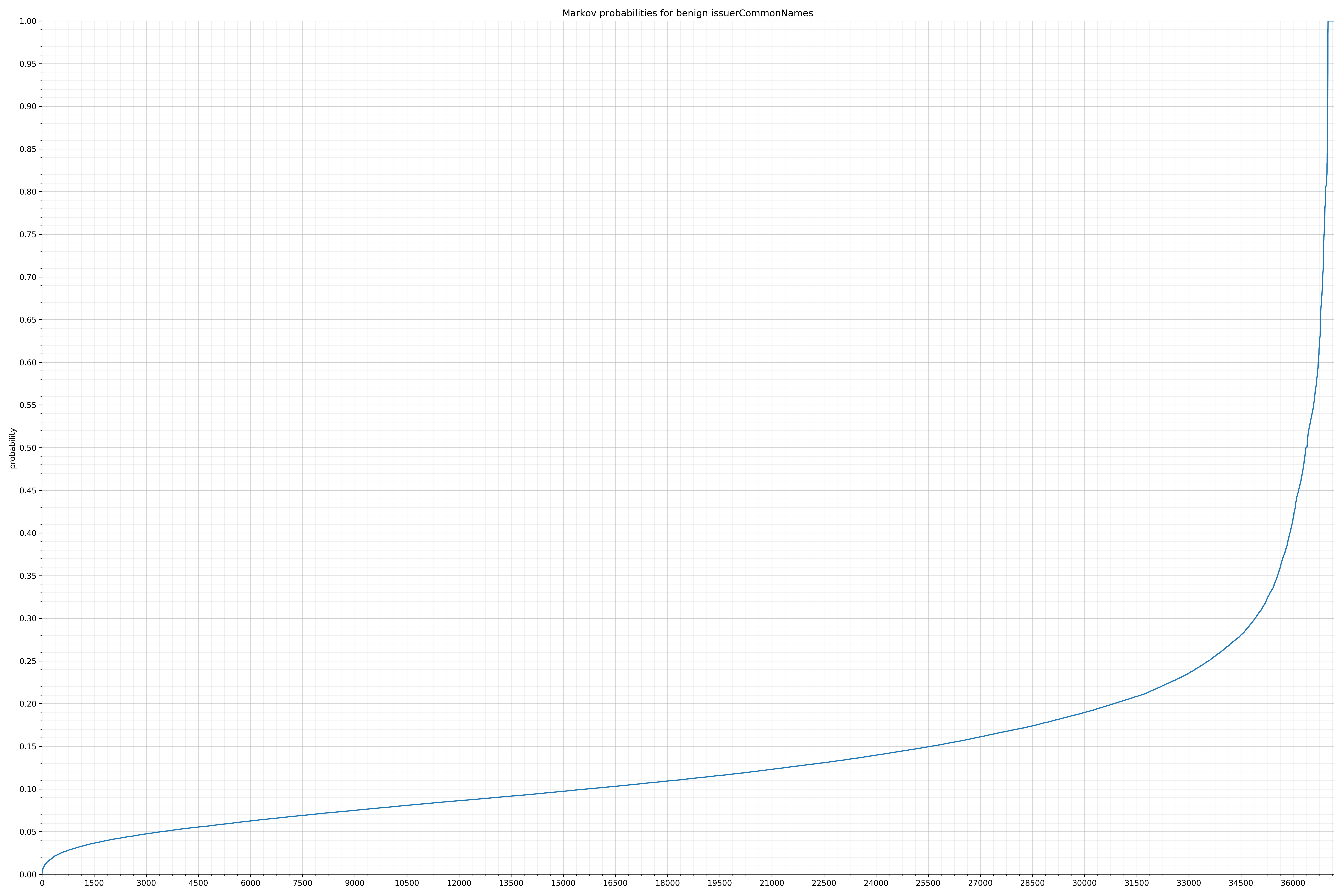{kind=link}
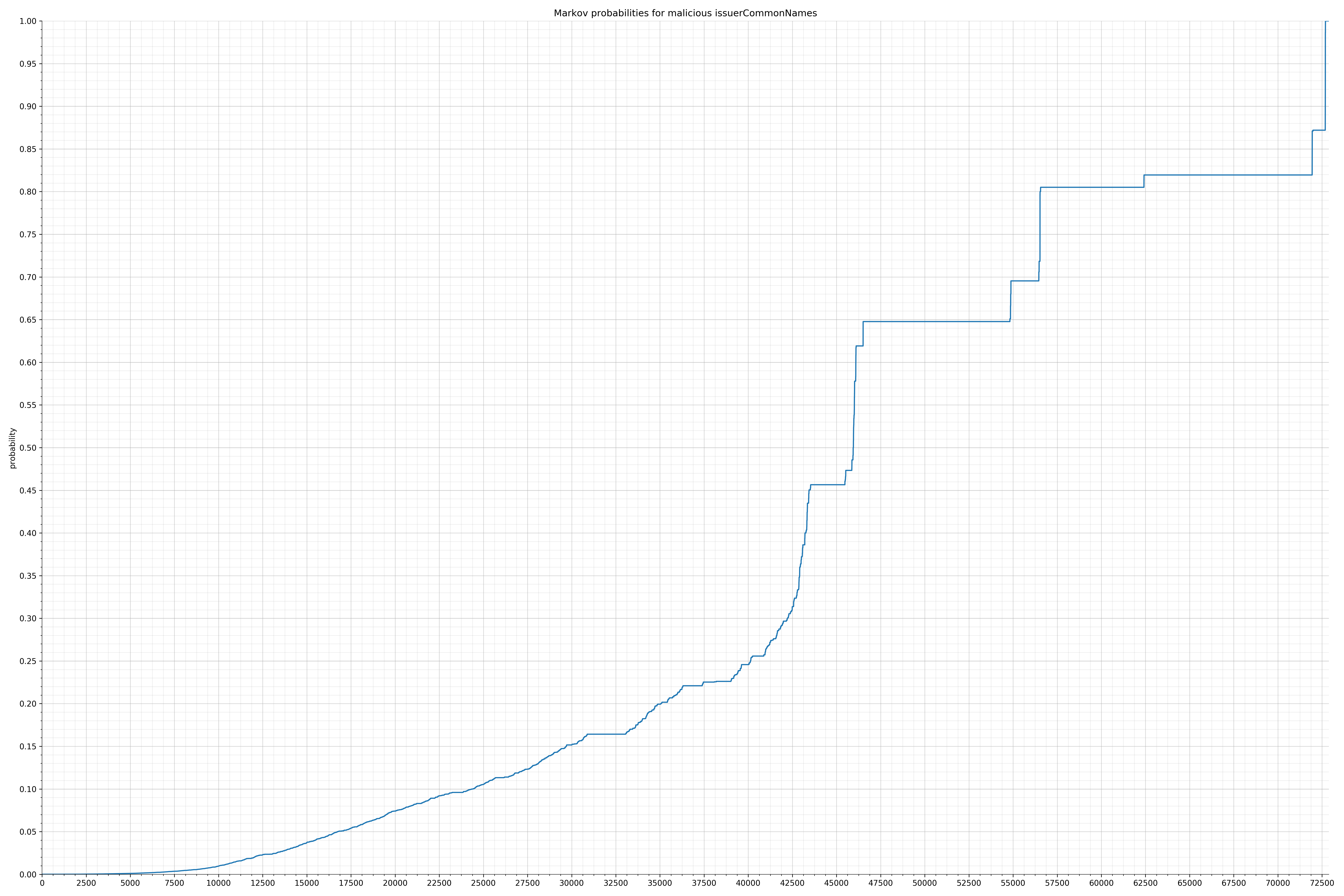{kind=link}
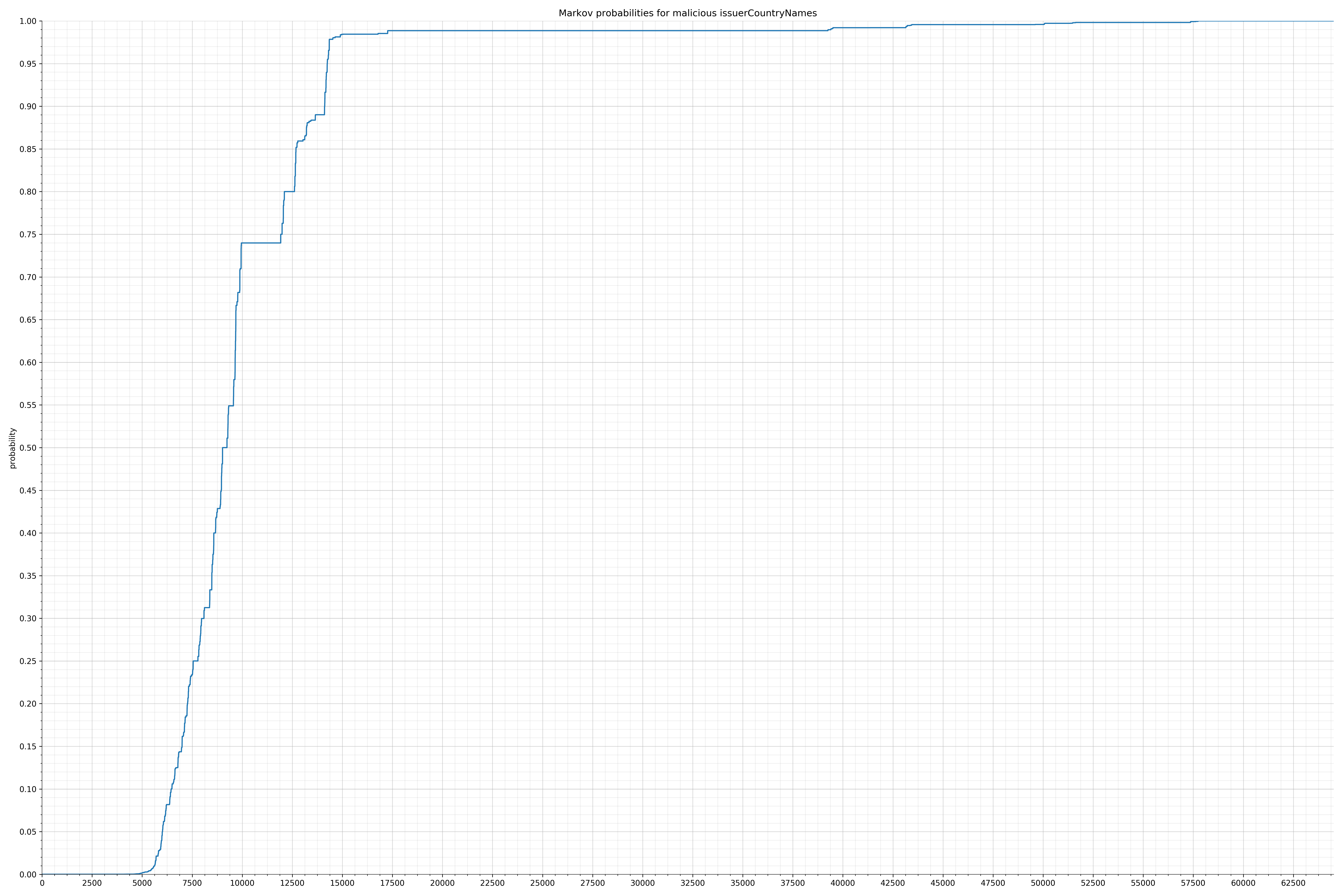
· issuerCountryNames – 良性 / 恶意
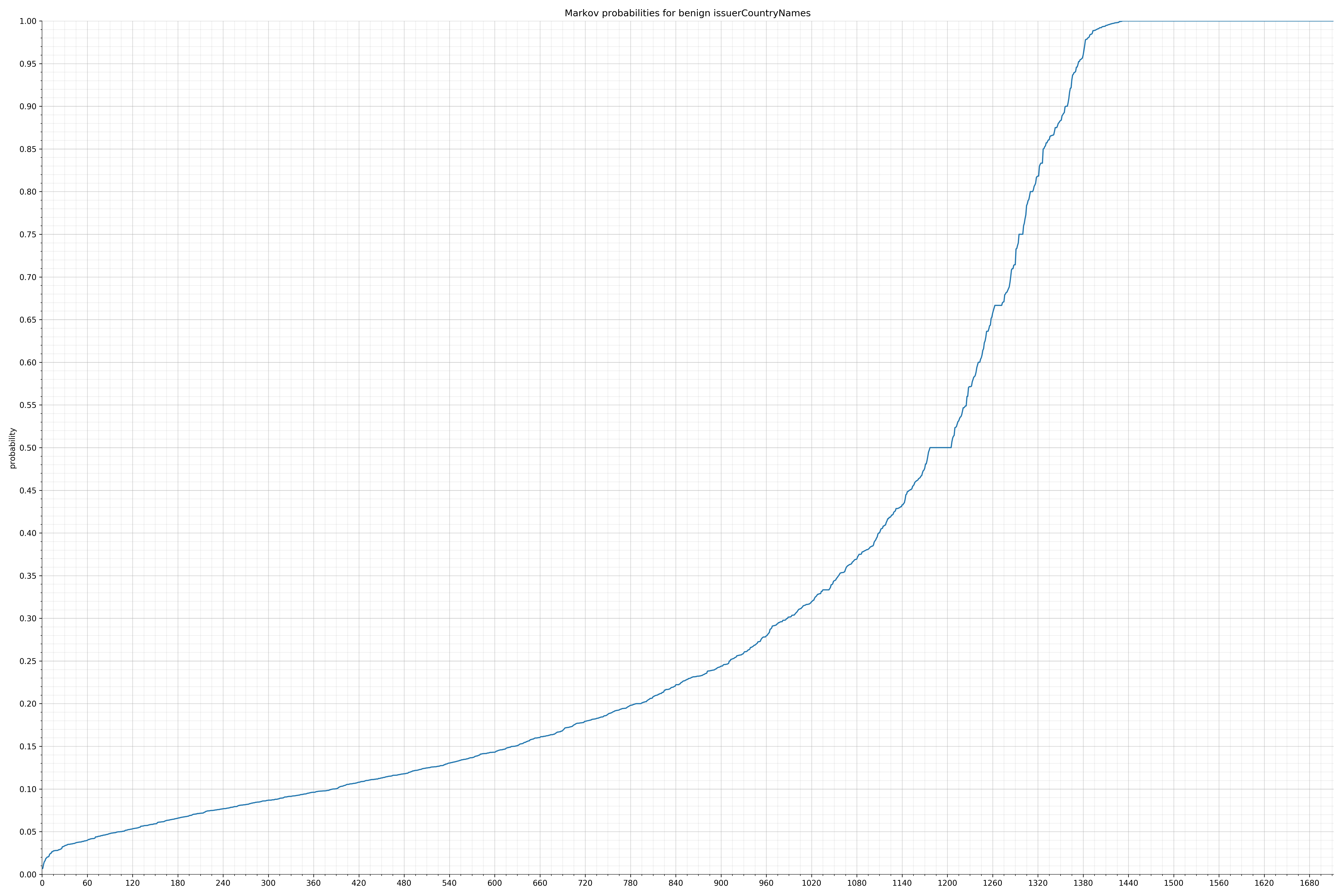{kind=link}
{kind=link}
{kind=link}
{kind=link}
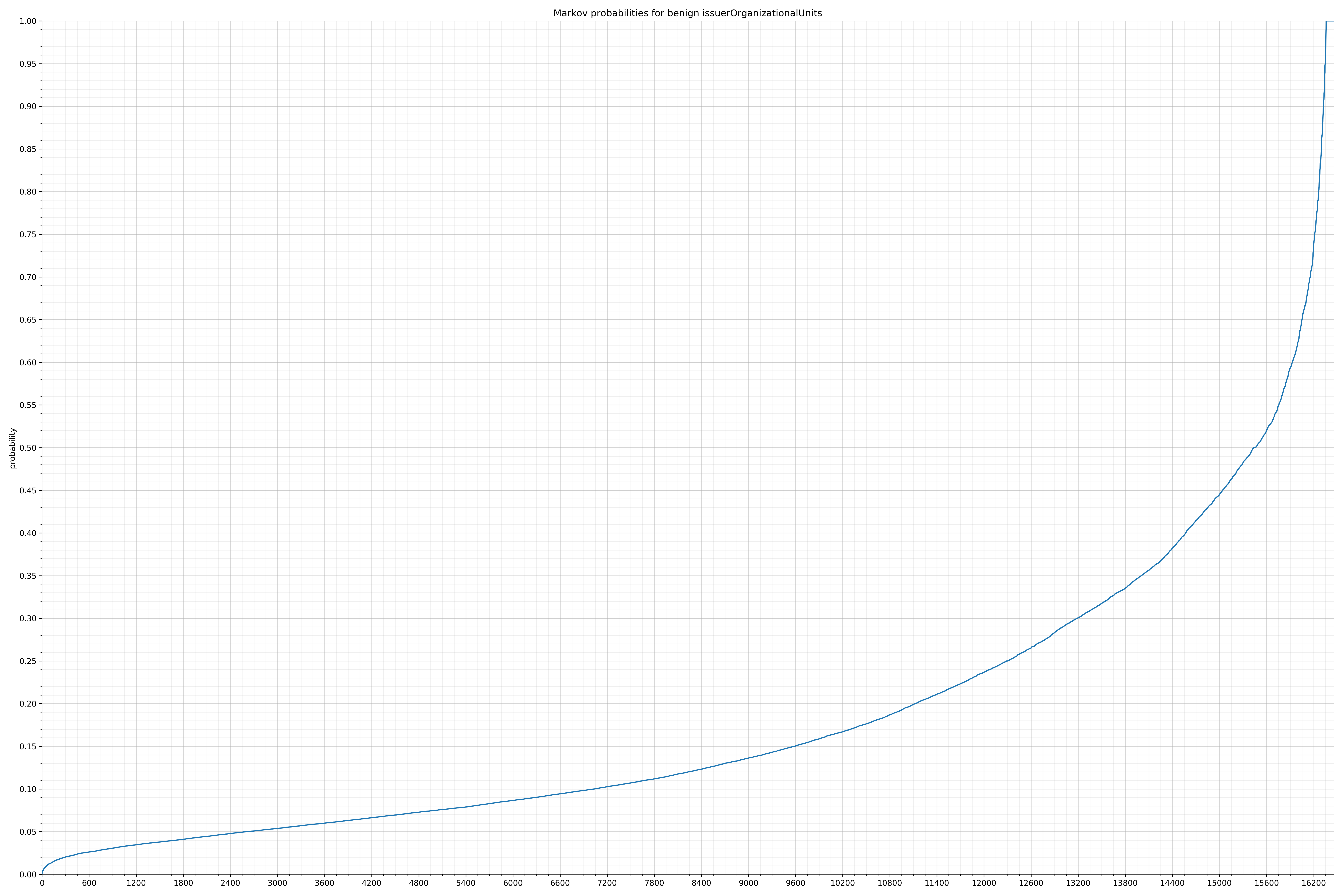
· issuerOrganizationalUnits – 良性 / 恶意
{kind=link}
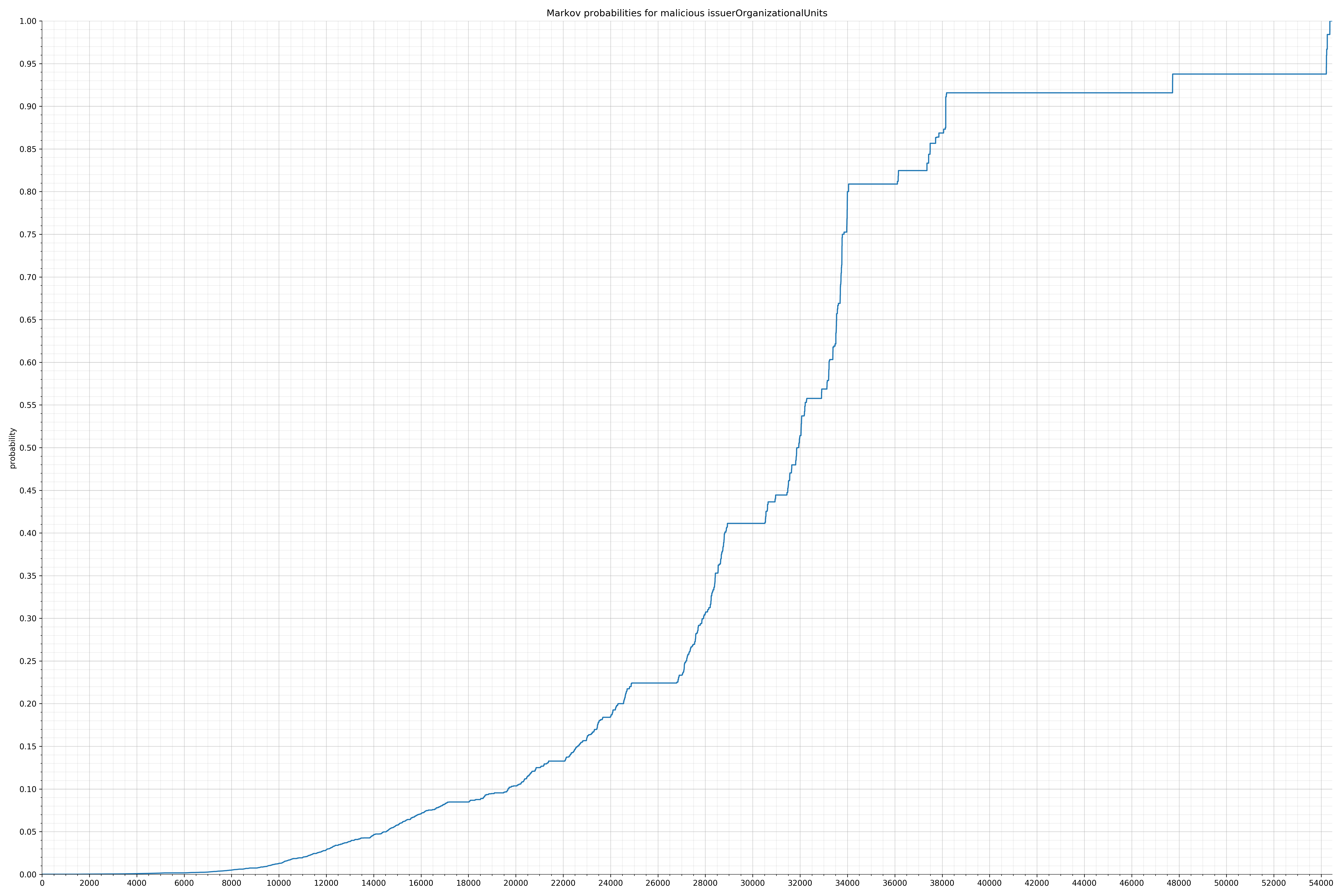{kind=link}
· issuerOrganizations – 良性 / 恶意
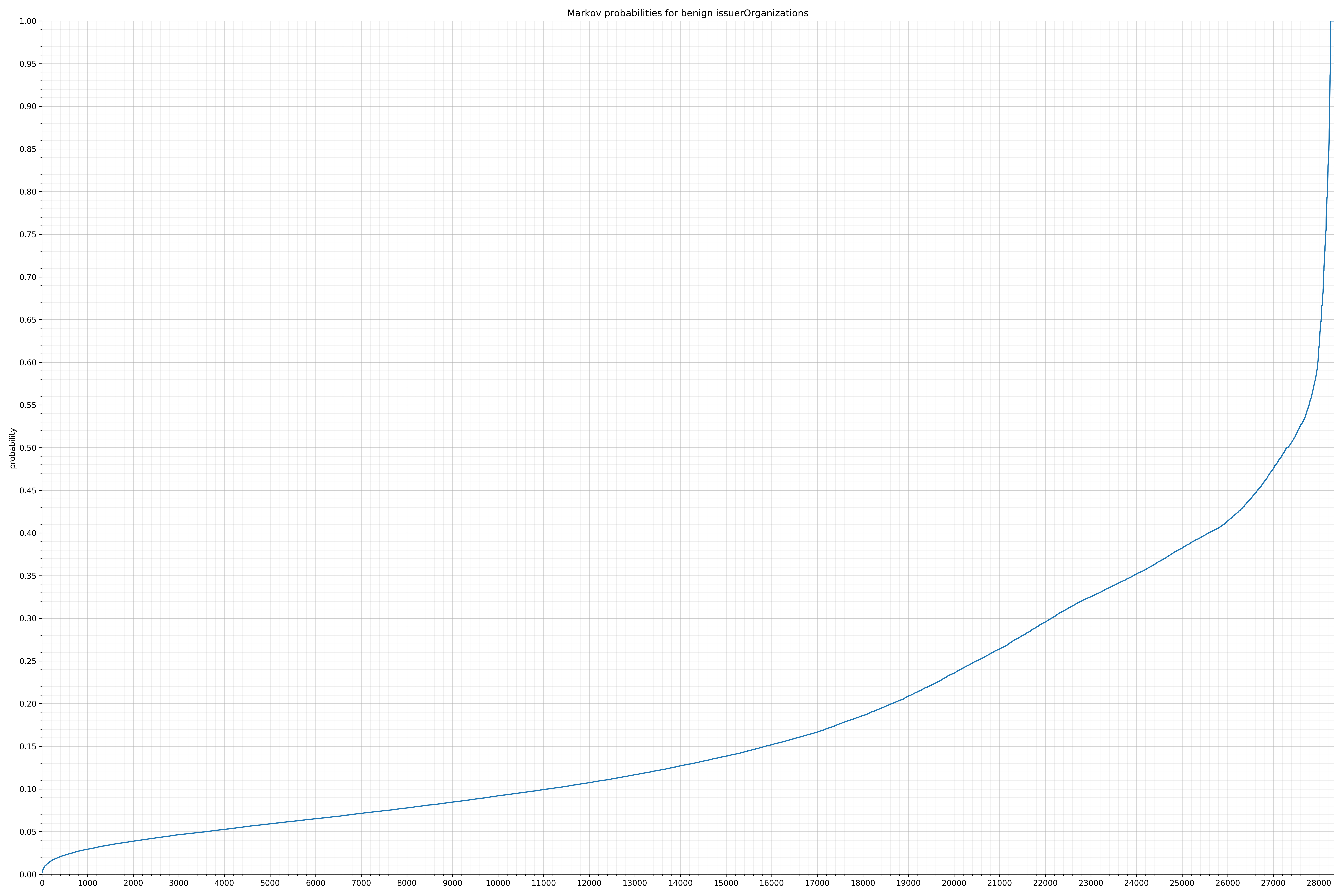{kind=link}
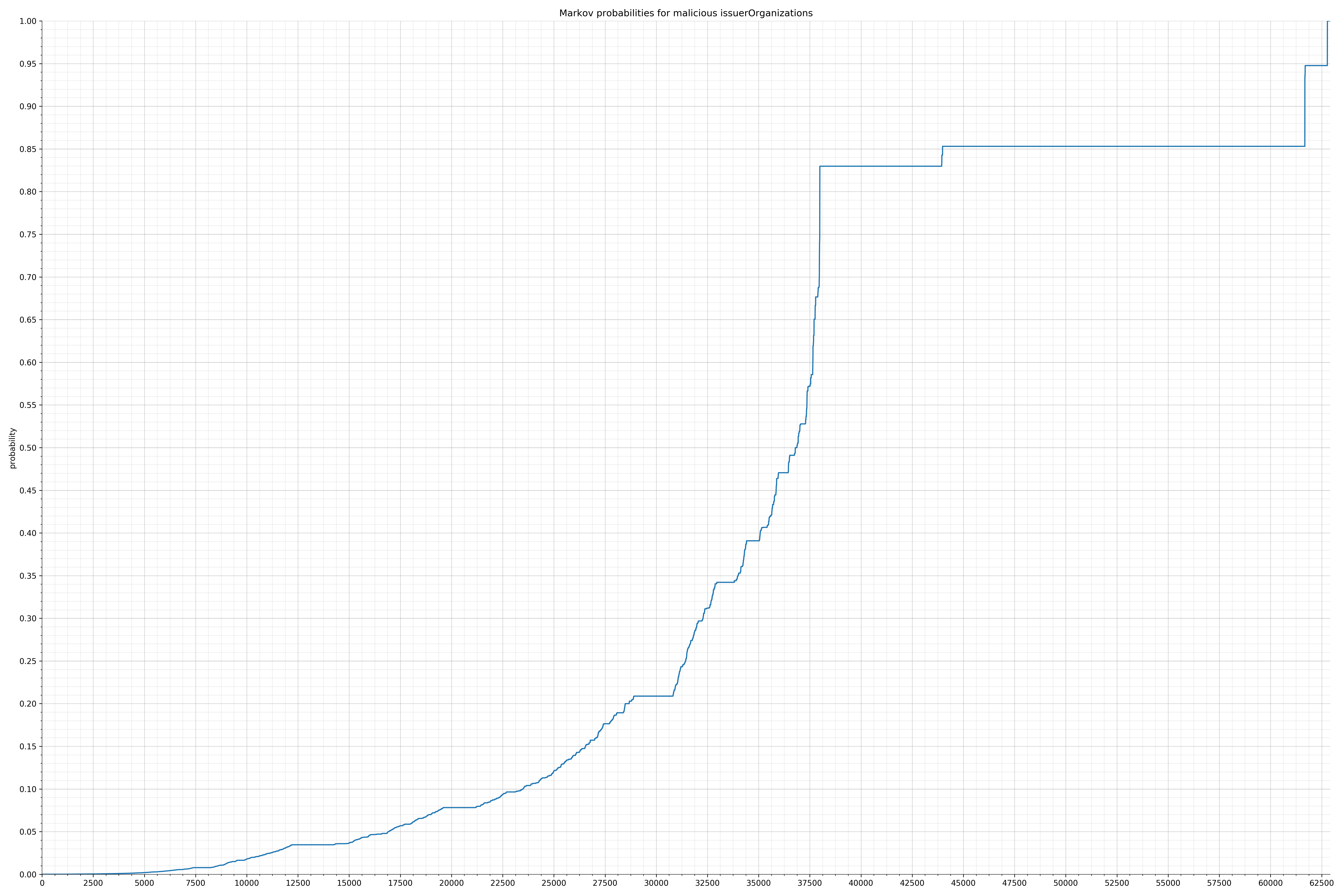{kind=link}
{kind=link}
{kind=link}
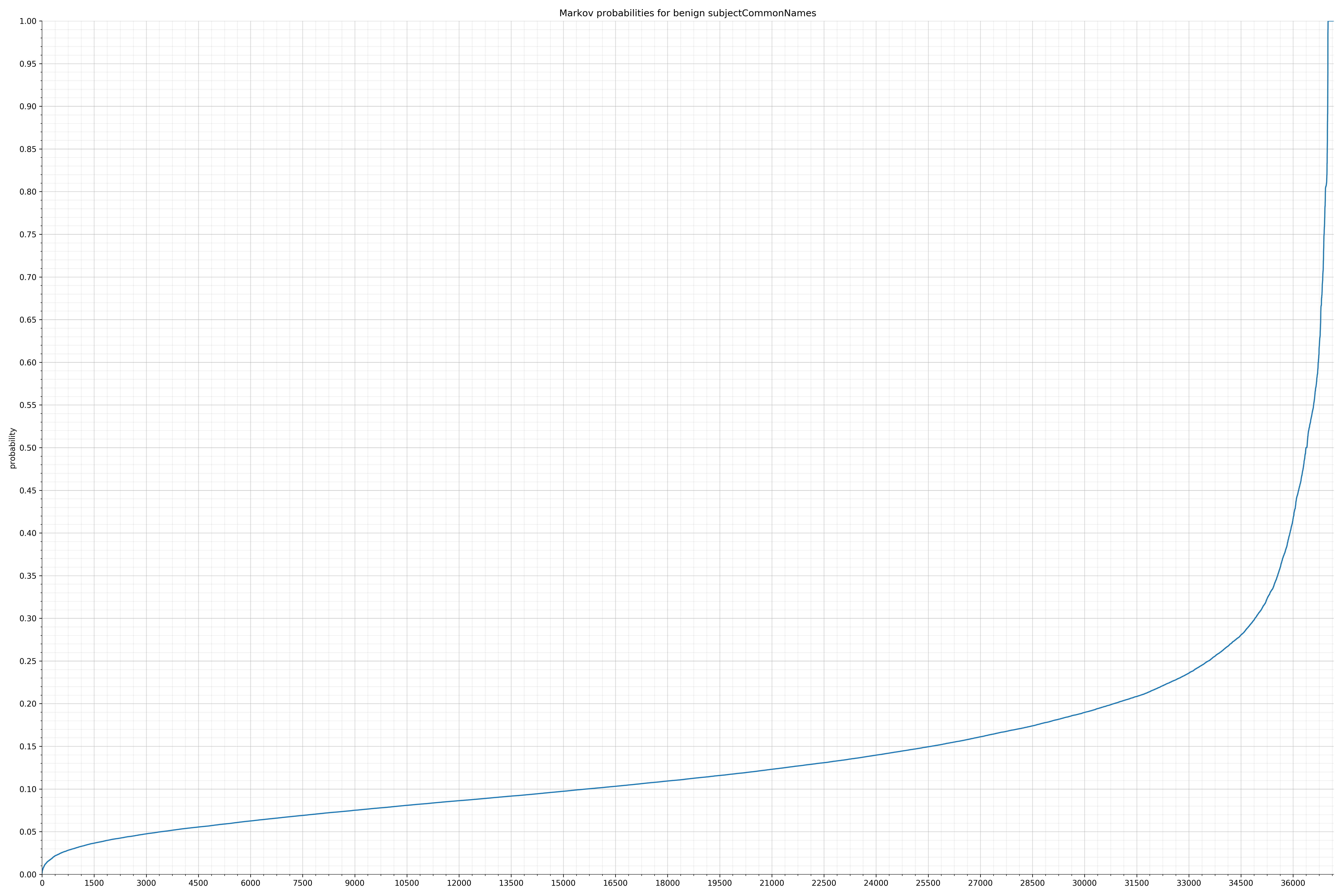
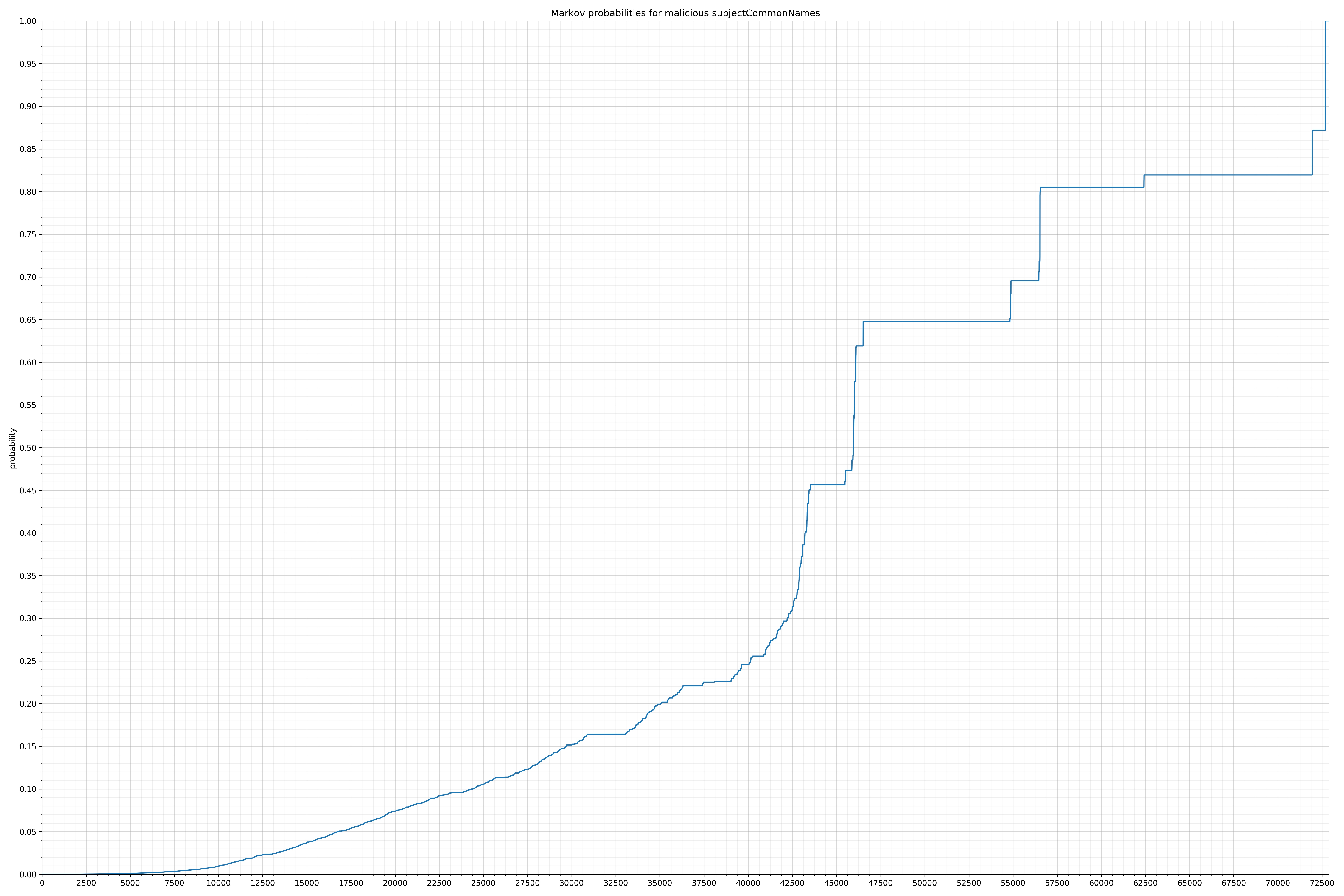
· subjectCommonNames – 良性 / 恶意
{kind=link}
{kind=link}
· subjectCountryNames – 良性 / 恶意
{kind=link}
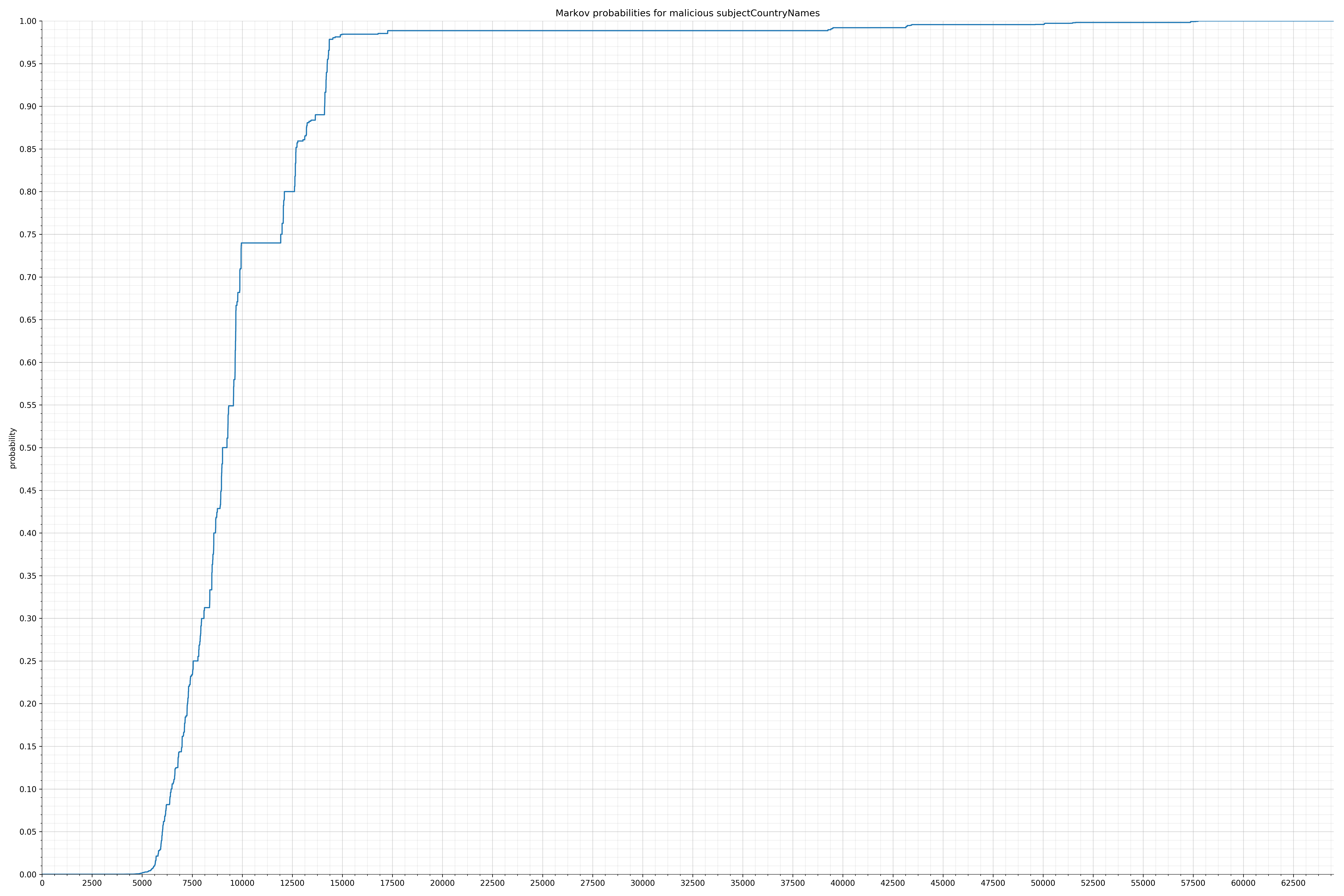{kind=link}
{kind=link}
{kind=link}
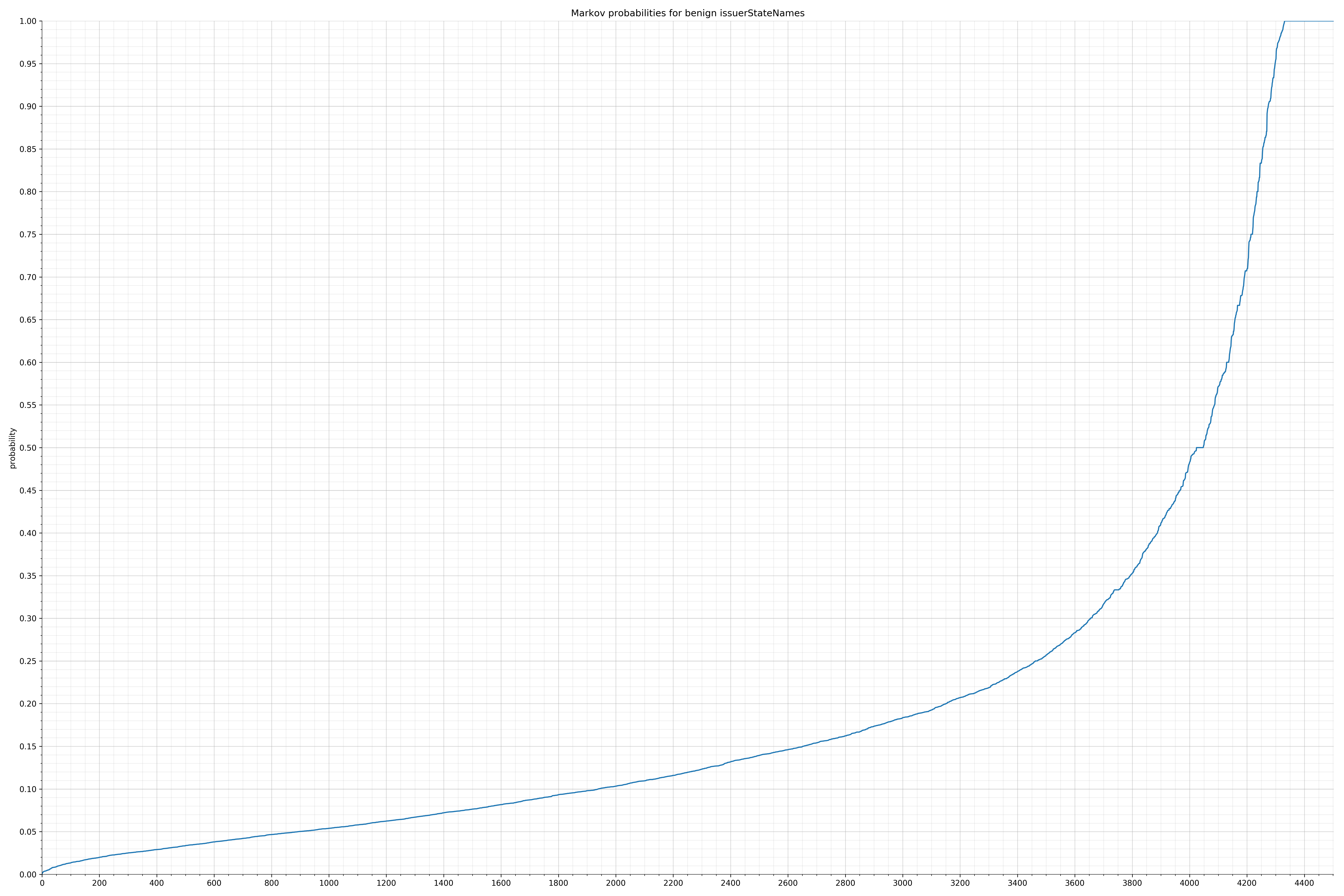
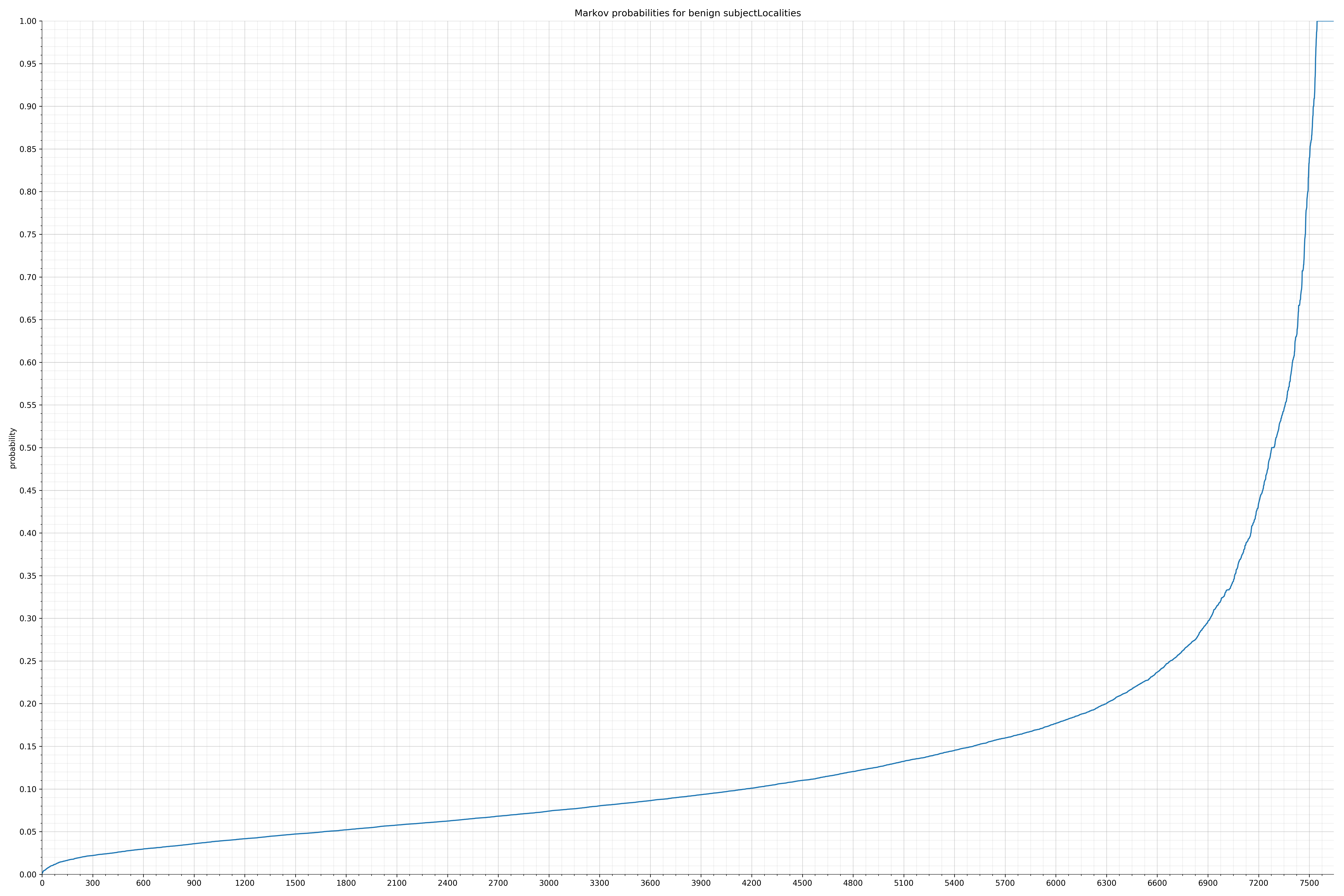
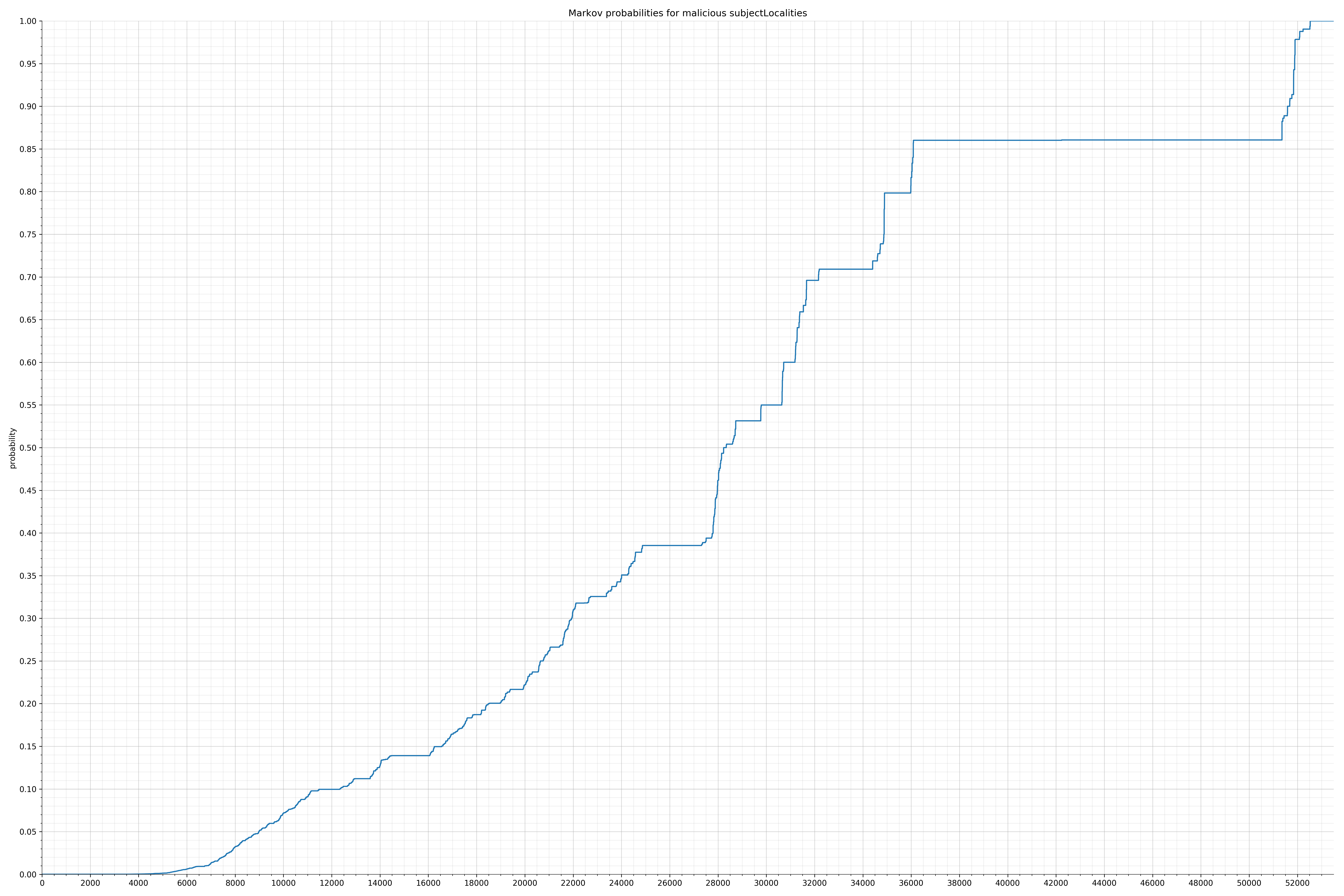
· subjectOrganizationalUnits – 良性 / 恶意
{kind=link}
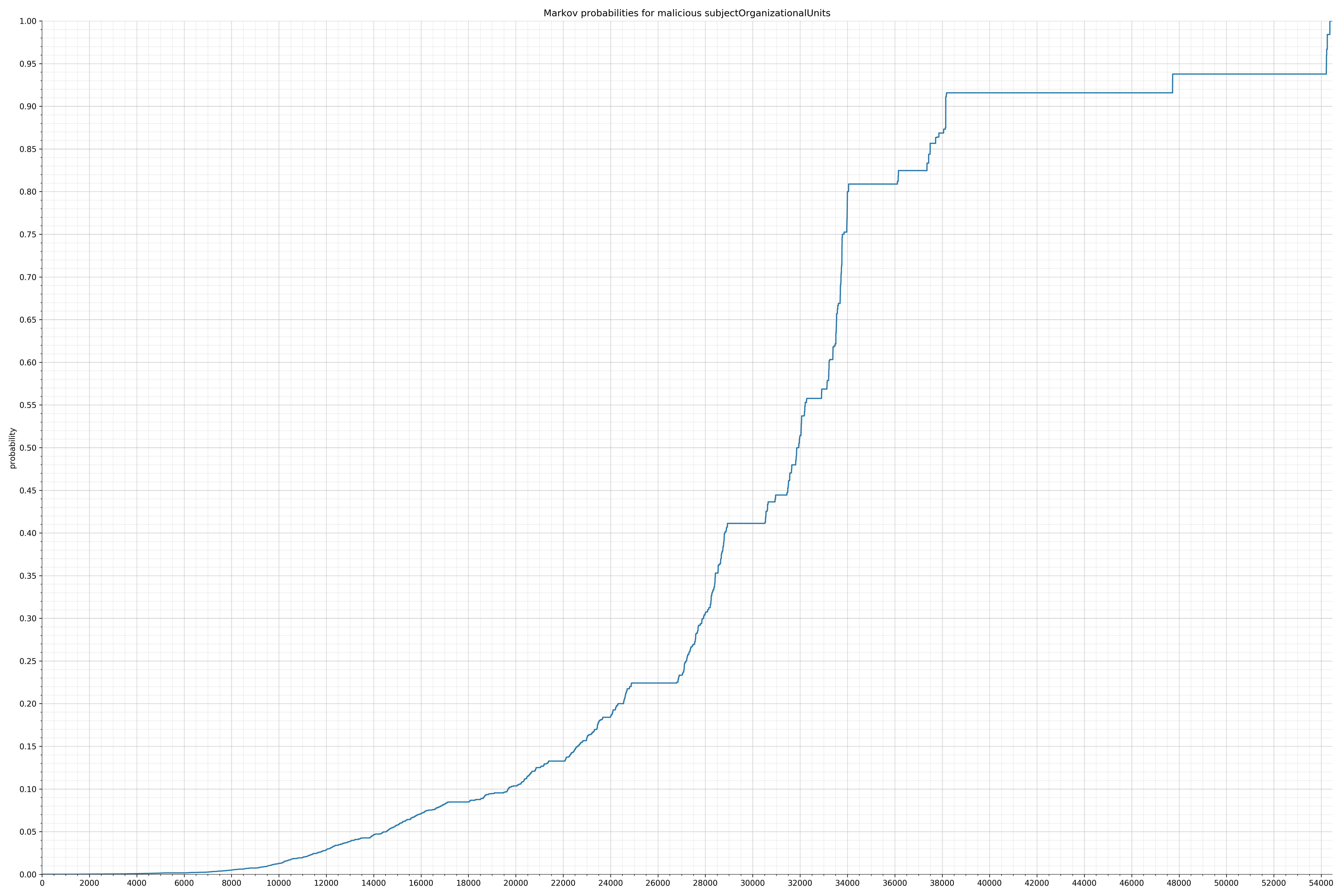{kind=link}
· subjectOrganizations – 良性 / 恶意
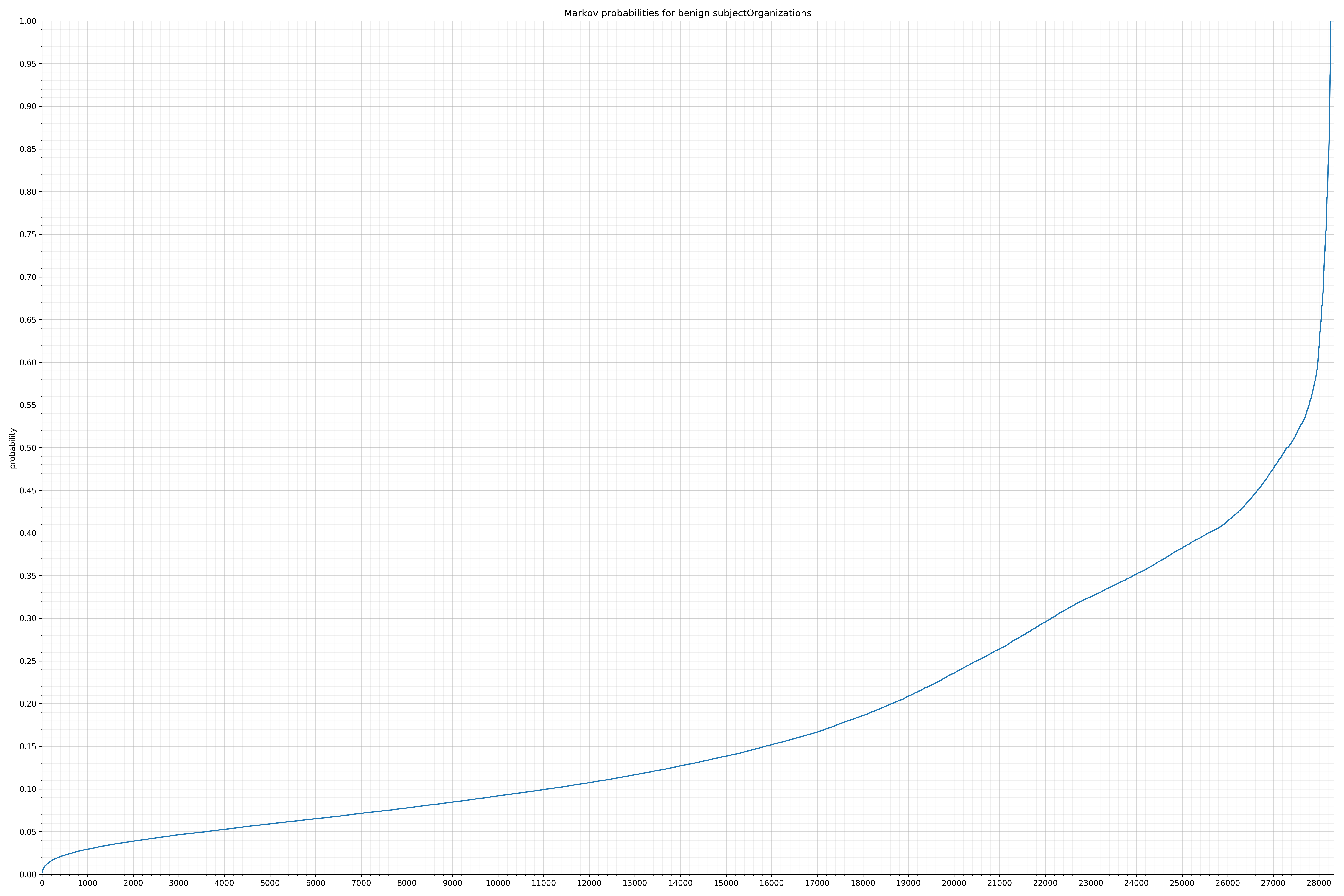{kind=link}
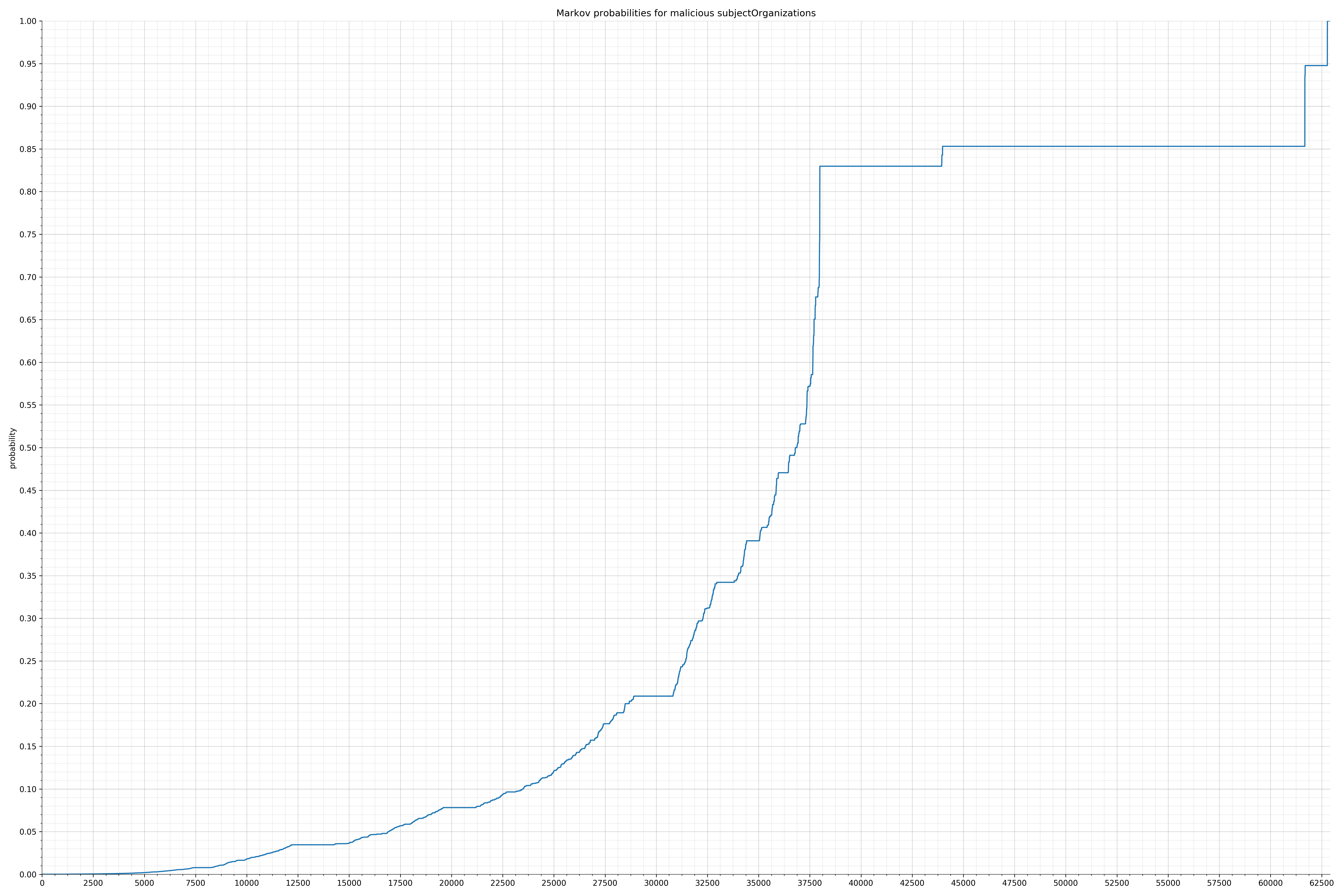{kind=link}
{kind=link}
{kind=link}
比较图表
我们来看一个具体的例子。最大的字符串集合之一是原始字符串。这些都是代码中会出现的字符串。例如String message = "hello,world!";的原始字符串就是hello,world!。
以下是白样本字符串的概率分布:

良性的白样本字符串分布
以下是黑样本中恶意字符串的概率分布:
恶意字符串分布
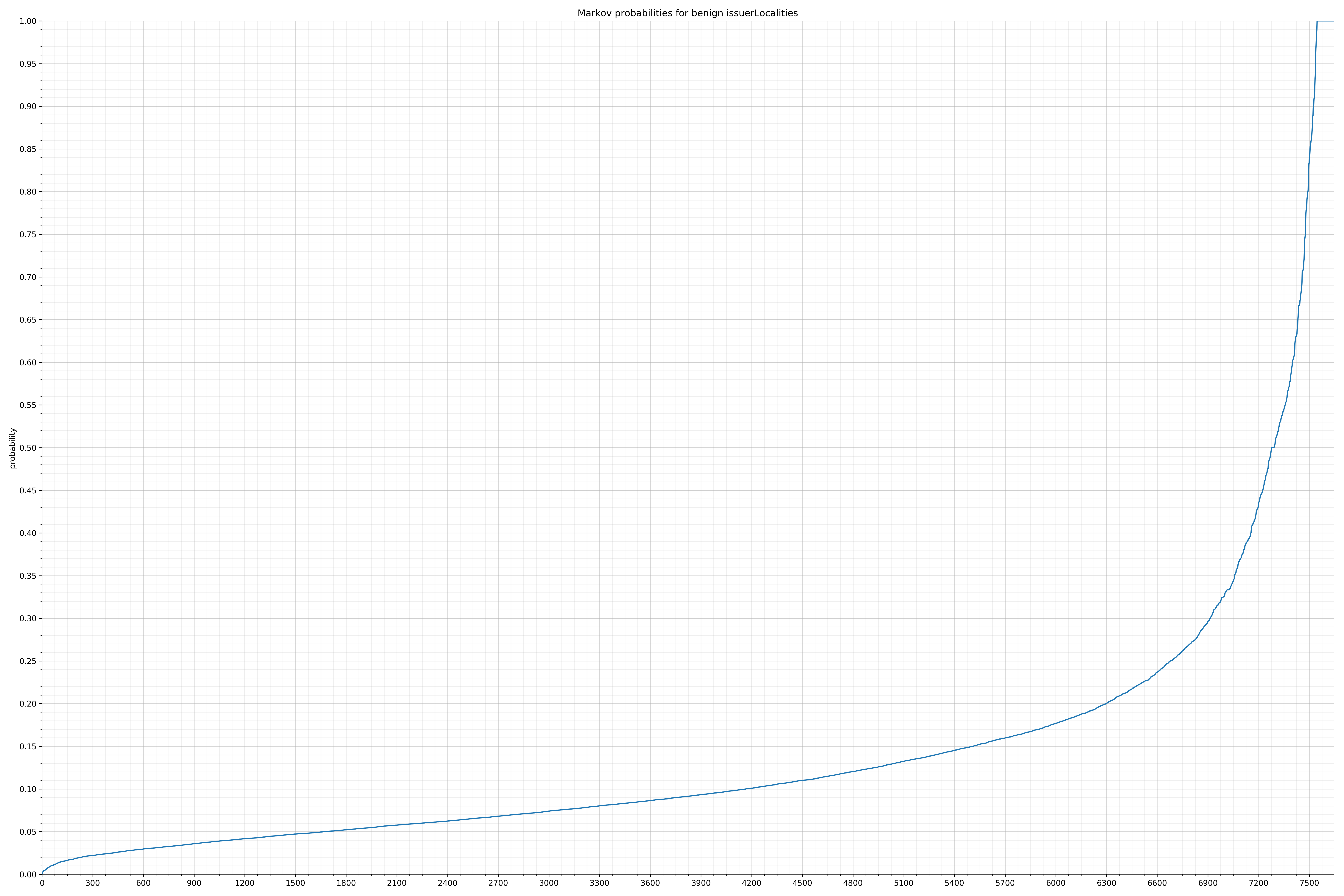
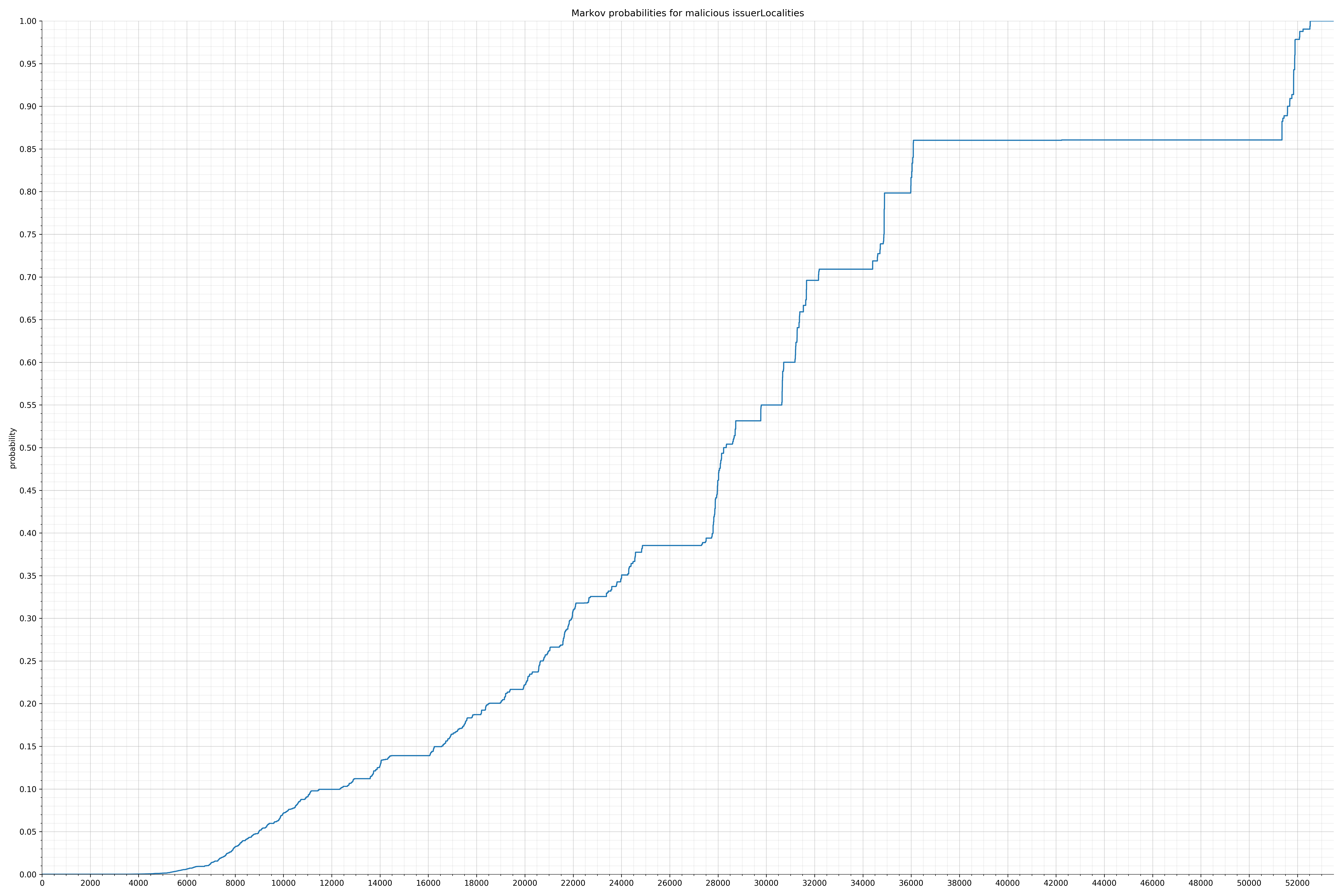
请注意,在两个图形之间沿着x轴的刻度是不同的,但是也请同时注意,图形的形状并不是很重要。
在良性白样本字符串图表中,字符串通常具有较高的概率,尤其是在较低的0.01和0.05概率之间。这表明将此信息添加到模型中可以提高模型性能。
为了将此信息添加为特征,我收集了每个字符串的概率并将它们放入不同的bin中。例如,对于概率小于等于0.01的每个字符串,我增加了“概率为0.01”对应的bin中的字符串计数。bin如下:
double [] bins = new double [] {
0.01,0.02,0.03,0.04,0.05,0.06,0.08,0.10,
0.20,0.30,0.40,0.50,1.0
};
请注意,在较低概率中,bin数量越多越能更好的捕捉两个类型(恶意/良性)之间观察到的分布差异。最好,可以对其他字符串类别进行了类似的bin分布。
结果和结论
通过结合马尔科夫的特性,模型性能得到了相当大的提升。下面是使用前10,000个特征的10倍交叉验证得到的“v1”模型的得分:
· 召回率:0.938063119746
· 精确率:0.979244936027
· 准确率:0.965148875727
以下是以相同方式得出的“v2”模型的分数:
· 召回率:0.958403081067
· 精确率:0.984061094076
· 准确率:0.97440419396
p.p1 {margin: 0.0px 0.0px 22.4px 0.0px; line-height: 22.4px; font: 14.0px 'PingFang SC'; color: #434343; -webkit-text-stroke: #434343; background-color: #ffffff}
p.p2 {margin: 0.0px 0.0px 22.4px 0.0px; line-height: 22.4px; font: 14.0px 'PingFang SC'; color: #434343; -webkit-text-stroke: #434343}
p.p3 {margin: 0.0px 0.0px 23.1px 0.0px; line-height: 23.1px; font: 21.0px 'PingFang SC Semibold'; color: #434343; -webkit-text-stroke: #434343; background-color: #ffffff}
li.li4 {margin: 0.0px 0.0px 0.0px 0.0px; line-height: 22.4px; font: 14.0px 'PingFang SC'; color: #207ca9; -webkit-text-stroke: #207ca9}
span.s1 {font-kerning: none}
span.s2 {font: 14.0px 'Helvetica Neue'; font-kerning: none}
span.s3 {font: 14.0px 'Helvetica Neue'; font-kerning: none; color: #207ca9; -webkit-text-stroke: 0px #207ca9}
span.s4 {font-kerning: none; color: #207ca9; -webkit-text-stroke: 0px #207ca9}
span.s5 {font-kerning: none; background-color: #ffffff}
span.s6 {font-kerning: none; color: #207ca9; background-color: #ffffff; -webkit-text-stroke: 0px #207ca9}
span.s7 {font: 14.0px 'Helvetica Neue'; font-kerning: none; background-color: #ffffff}
span.s8 {text-decoration: underline ; font-kerning: none; background-color: transparent}
span.s9 {font: 21.0px 'PingFang SC'; font-kerning: none}
span.s10 {font: 14.0px 'Helvetica Neue'; -webkit-text-stroke: 0px #434343}
span.s11 {font: 14.0px 'PingFang SC'; font-kerning: none; background-color: #ffffff; -webkit-text-stroke: 0px #207ca9}
ul.ul1 {list-style-type: disc}
我认为这个结果很不错,因为要让每个百分点都超过90%是一件很难的事情。另外请注意,这些模型性能分数没有使用最优算法。我只是将前10,000个特征放入ExtraTreesClassifier中,因为这种分类器运行很快而且相当不错。我对最佳分数并不感兴趣,只对相对改进的过程感兴趣。使用单一,调整良好的模型和更智能的特征选择,可以将模型的性能提高到99%。
但99%的反病毒模型的性能仍然较差,特别是对于精确度,因为误报是非常糟糕的事情。我认为性能不佳的原因是因为恶意测试集包含了广告软件和注入型恶意软件。广告软件应用程序难以通过静态手段区分,而且即使通过熟练的人工分析甚至也很难区分。对于这种情况,通常只能通过程序行为分析来做出区分,但是运行应用程序会导致显示许多“烦人”的广告。通过将特征更加明显的恶意应用程序的数据集(有点像采摘樱桃)进行训练,模型性能可能会好很多。
所谓的注入型恶意软件是一种本身正常的应用程序中被注入了恶意代码。这对于安卓恶意软件开发者来说非常容易就能实现,因为安卓程序易于拆卸和重新组装。不出所料,Judge模型中使用的特征中有APKiD,它可以在应用程序已注入代码的情况下指示编译器作为代理。此类恶意软件也很难被发现,因为通常来说,这种软件的大多数代码都是合法的,这意味着我们选取的特征得出的结果大多是合法的应用程序。
在任何情况下,都需要进行进一步的实验来确定那些最容易被忽略的恶意软件的检测。知道这一点后,在训练模型时就应添加更多的特征来专门针对这种类型的恶意软件进行模型训练。
使用马尔科夫模型需要考虑的另一个问题是,在任何一种反病毒解决方案中,通常都能够将某几种类型的应用程序列入白名单,来大大减少误报的影响。例如,一家反病毒公司可以记录最常见的签名并将所有这些签名列入到白名单。这将减小比较流行的软件或系统应用程序的被检测为恶意软件的可能性,从而降低误报率。
未来的工作
这个实验耗时了两天,大部分时间花在了提取特征上。或许应该可以使用较小的数据集来减少迭代时间,比如我可以尝试20-50万而不是18万个样本。
此外,还可以调整马尔可夫标记化和n-gram选择。现在还不清楚组合使用这两种方式得出的结果是否理想。Trigrams可能更好一些,或者可能1-grams也不错。最好通过空格而不是间距和标点符号来标记原始字符串,因为标点符号对于很多混淆的字符串来说很重要,通过这个技巧来捕获特征可能会很不错。
在马尔可夫的特征上完成模型训练可能对bin的定义方式非常敏感。在较高范围内添加更多bin可能更好一点,或者在较低范围内也会不错。利用一些性能指标,可以通过算法来确定容器大小并自动完成一些猜想。这将使持续迭代的模型的更新变的更容易。
此外,过滤掉常见的类也很有用。大多数应用程序的开发都会用到通用库,通过过滤这些通用库,提取的特征可以更准确的反映每个应用程序的独特之处。我已经得出了相关代码的特征,我将在后面的文章中进行介绍。我对此问题的关注点是,由于主要的程序库很多且经常发生变化,因此需要更多的工作来维护公共类的列表。
参考数据
我非常乐于分享数据,读者可以自己拿去玩一玩。以下是本文中用到的大部分数据的链接:
· 良性字符串计数
· 恶意字符串计数
这些是压缩过的JSON文件,易于查看和理解。注意,这里记录的是字符串计数而不是字符串,因为马尔科夫链是通过在每次计数时将每个字符串添加到链中来训练的。因此,如果一个字符串被找到100次,那么马尔可夫链将会添加100次。
最好一个链接是一些反序列化的马尔科夫模型的示例代码。它可以作为资源Jar的一部分进行加载。
InputStream is = MarkovLoader.class.getResourceAsStream("/markov_chains.obj");
if (is == null) {
throw new IOException("Markov chains resource not found");
}
ObjectInputStream ois = new ObjectInputStream(is);
Object obj = ois.readObject();
Map<String, MarkovChain> markovChains;
if (obj instanceof HashMap) {
markovChains = (HashMap) obj;
} else {
throw new IOException("Weird markov chain resource");
}