C/C++中的未对齐现象、原因及解决办法
C/C++中的未对齐现象、原因及解决办法
原文:https://blog.quarkslab.com/unaligned-accesses-in-cc-what-why-and-solutions-to-do-it-properly.html
前言
当采用对齐方式访问内存时,即当指针值为对齐值的整数倍时,CPU会获得更好的性能。现在各种CPU中还存在这种区别,并且某些CPU仅包含执行对齐访问的指令。考虑到这个问题,C标准中纳入了对齐规则,因此编译器可以根据这些规则来尽可能地生成有效的代码。根据本文的分析,我们在转换(cast)指针时需要格外小心,确保不破坏这些规则。本文的目标是向大家描述这方面存在的问题,并且给出能够轻松克服该问题的一些方法,为大家提供参考。
如果大家想直接获取最终代码,可跳到下文的“C++辅助库”部分。
剧透:本文提供的解决方案没有任何特殊性,都是非常标准的处理方式。互联网上也有其他资料涉及到这方面内容(参考1以及2)。
问题描述
让我们来看一个哈希函数,该函数可以从缓冲区中计算出64位整数值:
#include <stdint.h>
#include <stdlib.h>
static uint64_t load64_le(uint8_t const* V)
{
#if !defined(__LITTLE_ENDIAN__)
#error This code only works with little endian systems
#endif
uint64_t Ret = *((uint64_t const*)V);
return Ret;
}
uint64_t hash(const uint8_t* Data, const size_t Len)
{
uint64_t Ret = 0;
const size_t NBlocks = Len/8;
for (size_t I = 0; I < NBlocks; ++I) {
const uint64_t V = load64_le(&Data[I*sizeof(uint64_t)]);
Ret = (Ret ^ V)*CST;
}
uint64_t LastV = 0;
for (size_t I = 0; I < (Len-NBlocks*8); ++I) {
LastV |= ((uint64_t)Data[NBlocks*8+I]) << (I*8);
}
Ret = (Ret^LastV)*CST;
return Ret;
}
大家可以访问此处下载包含main函数的完整源代码。
函数的主要功能是将输入数据当成若干块64位低字节序(little endian)整数来处理,与当前的哈希值执行XOR操作以及乘法操作。对于剩下的字节,函数会使用余下的字节来填充64位数。
如果我们希望这个哈希函数能够跨架构可移植(这里可移植的意思是能够在每一个CPU/OS上生成相同的值),我们需要小心处理目标的字节序,在本文末尾我们会提到这个话题。
接下来,让我们在典型的Linux x64计算机上编译并运行该程序:
$ clang -O2 hash.c -o hash && ./hash 'hello world'
527F7DD02E1C1350
一切顺利。现在,让我们交叉编译这段代码,目标为Android手机,搭载处于Thumb模式的ARMv5 CPU。假设ANDROID_NDK为指向Android NDK安装位置的环境变量,我们可以执行如下命令:
$ $ANDROID_NDK/build/tools/make_standalone_toolchain.py --arch arm --install-dir arm
$ ./arm/bin/clang -fPIC -pie -O2 hash.c -o hash_arm -march=thumbv5 -mthumb
$ adb push hash_arm /data/local/tmp && adb shell "/data/local/tmp/hash_arm 'hello world'"
hash_arm: 1 file pushed. 4.7 MB/s (42316 bytes in 0.009s)
Bus error
出现了一些问题。让我们尝试另一个字符串:
$ adb push hash_arm && adb shell "/data/local/tmp/hash_arm 'dragons'"
hash_arm: 1 file pushed. 4.7 MB/s (42316 bytes in 0.009s)
39BF423B8562D6A0
调试过程
我们可以对内核日志执行grep操作,得到如下结果:
$ dmesg |grep hash_arm
[13598.809744] [2: hash_arm:22351] Unhandled fault: alignment fault (0x92000021) at 0x00000000ffdc8977
貌似我们碰到了对齐问题。来看一下编译器生成的汇编代码:
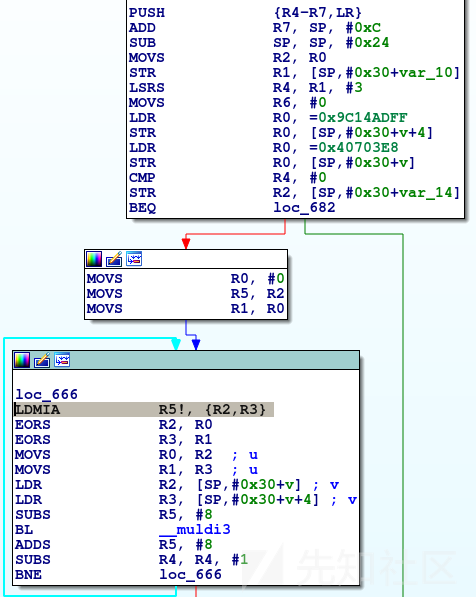
LDMIA指令会将数据从内存中加载到多个寄存器中。对于我们这个例子,该指令会将我们的64位整数加载到2个32位寄存器中。根据ARM的文档对该指令的说明,内存指针必须word对齐(word-aligned,这里1个word对应2字节)。问题之所以出现,是因为我们的main函数使用了由libc加载器传递给argv的一个缓冲区,而这里并不能保证满足对齐条件。
原因解释
这里我们自然会问一个问题:为何编译器会采用这样一条指令?为何编译器会认为Data指向的内存是word对齐的?
问题在于load64_le函数中,其中存在这样一条转换语句:
uint64_t Ret = *((uint64_t const*)V);
根据C标准中的说明:“完整的对象类型需要满足对齐要求,这会限制该类型的对象可能分配的地址。对齐值是由具体实现所定义的一个整数值,表示给定对象所能分配的连续地址之间对应的字节数”。换句话说,这意味着我们必须满足如下条件:
V % (alignof(uint64_t)) == 0
同样根据C标准,将指针从某种类型转化为另一种类型,而不遵守这个对齐规则时属于未定义的行为。
在我们的例子中,uint64_t大小为8字节(我们可以使用这个测试网页来验证这一点),因此我们遇到了这种未定义行为。更具体一点,前面那条转换语句会告诉编译器这样一个事实:“Ret大小是8的倍数,因此是2的倍数,因此你可以安全地使用LDMIA”。
x86-64架构上不会出现这个问题,因为Intel的mov指令支持未对齐的加载方式(如果未启用对齐检测功能,而只有操作系统才能启用该功能。另外据我所知,没有一个x86系统会激活该功能,如果对该功能不了解,启用该功能可能导致编译器生成错误的代码)。这也是为什么“老代码”中会存在这样一个隐蔽bug,因为该bug永远不会出现在x86计算机上(而这些计算机正是开发代码的节点)。ARM Debian内核可以捕获并正确处理未对齐访问行为,这实际上真的非常糟糕。
解决方案
多次加载
一种经典的解决方案就是通过从内存中逐字节加载的方式来“手动”生成64位整数,这里采用低字节序方式,如下所示:
uint64_t load64_le(uint8_t const* V)
{
uint64_t Ret = 0;
Ret |= (uint64_t) V[0];
Ret |= ((uint64_t) V[1]) << 8;
Ret |= ((uint64_t) V[2]) << 16;
Ret |= ((uint64_t) V[3]) << 24;
Ret |= ((uint64_t) V[4]) << 32;
Ret |= ((uint64_t) V[5]) << 40;
Ret |= ((uint64_t) V[6]) << 48;
Ret |= ((uint64_t) V[7]) << 56;
return Ret;
}
如上代码具有多个优点:这是从内存中加载低字节序64位整数的可移植方法,并不会打破前面的对齐规则。当然也有缺点:如果我们想使用CPU对整数的自然字节序,我们需要编写两个版本的代码,然后使用ifdef方法来编译正确的版本。另外,这种代码编写起来有点乏味,容易出错。
无论如何,我们来看一下clang 6.0在-O2模式下的处理结果,不同架构的处理结果如下所示:
- x86-64:
mov rax, [rdi](参考此处结果)。这是我们可以预期的结果,因为x86上的mov指令支持未对齐访问。 - ARM64:
ldr x0, [x0](参考此处结果)。ldrARM64指令的确没有任何对齐限制。 - Thumb模式下的ARMv5:参考此处结果。编译结果基本上就是我们编写的代码,会逐字节加载整数进行构造。与之前的代码相比,我们可以注意到有一些显著的变化。
因此只要激活优化选项(注意上面各种测试结果中的-O1标志),Clang可以检测到这种方式,尽可能生成有效的代码。
memcpy
另一种方案就是使用memcpy:
uint64_t load64_le(uint8_t const* V) {
uint64_t Ret;
memcpy(&Ret, V, sizeof(uint64_t));
#ifdef __BIG_ENDIAN__
Ret = __builtin_bswap64(Ret);
#endif
return Ret;
}
这种方法的优点是我们仍然不会破坏任何对齐规则,可以使用自然的CPU字节序来加载整数(删除__builtin_bswap64语句),并且编写起来不大可能出错。一个缺点是需要依赖非标准的内置实现(即__builtin_bswap64)。GCC和Clang支持这种方式,MSVC有等效的解决方案。
来看一下Clang 6.0在-02模式下的处理结果,不同架构的处理结果如下所示:
- x86-64:
mov rax, [rdi](参考此处结果)。这是我们可以预期的结果(前面已经解释过)。 - ARM64:
ldr x0, [x0](参考此处结果)。 - Thumb模式下的ARMv5:参考此处结果(与之前结果一致)。
我们可以看到编译器能够理解memcpy的含义,并正确优化代码(因为对齐规则仍然有效)。生成的代码基本上与上一种方案相同。
C++辅助库
经过数十次编写这种代码后,我决定编写一个只包含头文件的小型C++辅助库,可以帮我们以自然序/小字节序/大字节序方式加载/存储任意类型的整数。大家可以访问Github下载源码。代码并没有特别花哨,但的确可以帮助我们节省时间。
我已经在Linux(x86 32/64、ARM和mips)上使用Clang和GCC测试过代码,Windows(x86 32/64)上使用MSVC 2015进行测试。
总结
令人遗憾的是,我们仍然需要使用这种“黑科技”来编写可移植代码,从内存中加载整数。目前的状况非常糟糕,我们需要依赖编译器的优化来生成高效且有效的代码。
事实上,编译器方面的人们喜欢说“你应该信任让编译器来优化代码”。虽然我们通常可以遵循这个建议,但本文描述的解决方案有个大问题,在于这种方案并没有依赖C标准,而是依赖C编译器的优化。因此,编译器无法优化我们的memcpy调用或者多次加载方案中的一系列OR及位移操作,并且这些操作一旦更改或者出现bug,就可能导致我们的代码效率低下(大家可以观察使用-O0之后生成的结果)。
最后,为了保证编译后的结果符合我们的预期,我们只能查看最终生成的汇编代码,而这在实际环境中并不是特别可行。如果有自动化方法能够检查这种优化结果会更好,比如使用pragma语法,或者由C标准定义的、能够按需激活的一小部分优化子集(但问题在于现在并没有这些子集,也不知道如何定义)。或者我们还可以为C语言添加标准的可移植的内置功能来解决这个问题,但这又是另一个话题了。
此外,如果大家有富余精力,建议阅读一下David Chisnall写的一篇文章,解释为何C并不是一门低级语言。