有效利用Btree索引提高查询效率
我们都知道,当数据量大时,在表的条件字段上创建索引,查询时能够快速定位数据,大大提高查询速度。
PG的Btree索引能够处理按顺序存储的数据的=,<,>,<=,>=,以及这些操作符的等效操作,如BETWEEN,IN以及IS NULL和以字符串开头的模糊查询。
如果查询中用到多个条件字段,就需要选择创建单个索引还是组合索引。在项目中做性能优化时,建立了索引,索引有时很有用,有时看起来没起作用,于是查了一些资料探明原因,总结了一下。
单索引
也就是通常的索引,不赘述。
组合索引
两个或更多个字段上的索引称为组合索引,例如
利用索引中的附加列可以缩小检索范围,但是使用联合索引不同于使用两个单独的索引,组合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按照姓氏排序,然后按照名字对相同姓氏的人排序,如果知道姓氏,电话簿非常有用,如果知道姓和名,电话簿则更有用。如果只知道名,则电话簿没有用处。
tbl_index_a_b_c相当于建立了3个索引(a,b,c)、(a,b)、(a,c),看起来确实高效,但它不支持(b,c)条件组合查询。
用事实说话
首先建立测试表(以PG 9.6.3为例)

插入测试数据
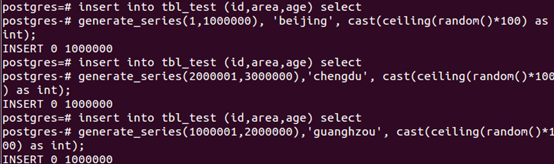
- 创建索引前查询
and组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' and age=18; |
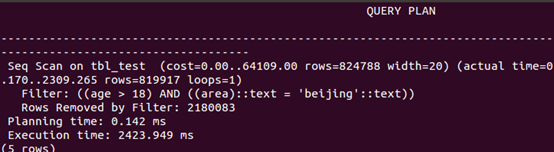
or组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' or age=18; |
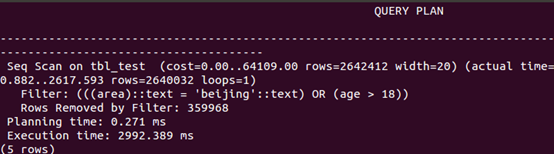
查询中排序
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' order by age; |
- 在area和age字段上分别创建索引

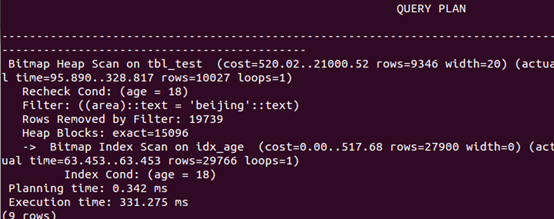
and组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' and age=18; |
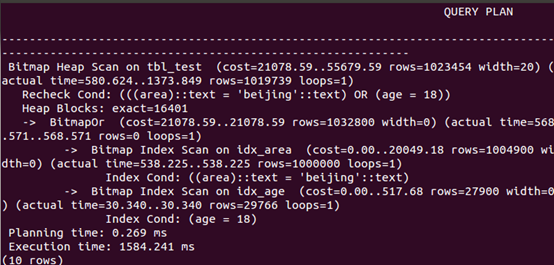
or组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' or age=18; |
查询中排序
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' order by age; |
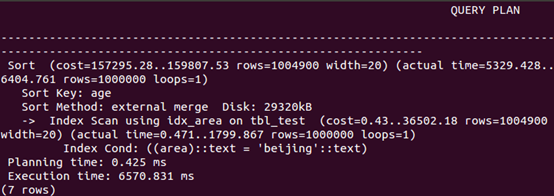
可以看出,分别在area和age字段上分别创建索引, and查询、or查询和查询中排序速度均有所提高。

- 删除单索引,在area和age字段上创建复合索引
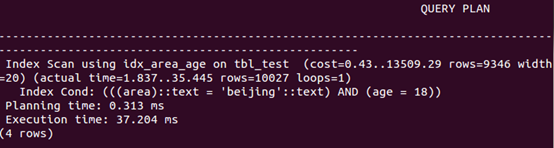
and组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' and age=18; |
or组合查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' or age=18; |
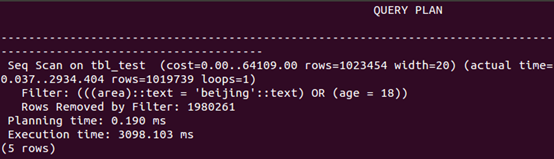
查询中排序
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing' order by age; |
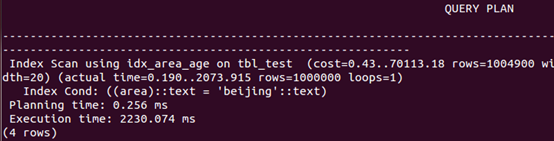
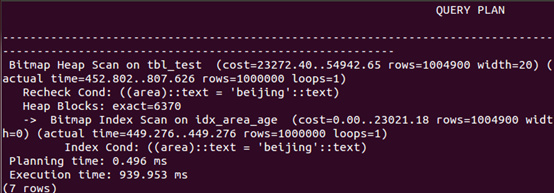
按area查询
|
1 2 3 |
explain analyze select * from tbl_test where area='beijing'; |
按age查询
|
1 2 3 |
explain analyze select * from tbl_test where age=18; |
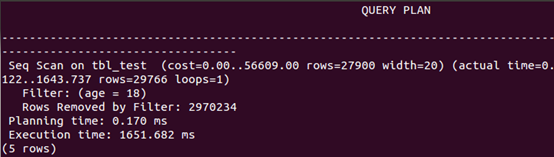
可以看出,创建组合索引,and查询和查询中排序的速度有更大幅度的提升,而or查询相比单索引,速度下降。如前述,只有where条件包含了组合索引第一个字段,才会进行索引扫描,否则进行全表扫描,如按age查询。or组合查询很特殊,where条件包含了组合索引第一个字段,依然进行全表扫描。
总结:
- 对于组合索引,一个查询可以只使用索引中的一列,但where条件中必须包含索引的第一列,即最左原则。对索引中的所有列进行搜索或前几列进行搜索时,索引非常有用。仅对后面几列进行搜索时,索引无用。
- 对于and 组合查询,在条件字段上创建组合索引与分别创建索引相比,能带来更高的效率。
- 对于or组合查询,创建组合索引与分别建立索引相比查询效率反而下降。
- 对于查询中排序的字段,分别创建索引,在where子句中使用了索引,order by子句就不会使用索引。这时创建组合索引,可以大大提高查询效率。
- 开发中,需要权衡考虑具体情况建立索引,如果创建组合索引,要仔细考虑列的顺序,将最常用做查询条件的列放在最左边,依次递减,称为最佳左前缀特性。
以上内容,欢迎指正。