用机器学习进行恶意软件检测——以阿里云恶意软件检测比赛为例
用机器学习进行恶意软件检测——以阿里云恶意软件检测比赛为例
前言
本文以天池阿里云恶意软件检测比赛为例,介绍了如何利用机器学习进行恶意软件检测。
由于本人代码水平有限,代码风格可能会比较丑陋,请各位海涵。前面两段介绍了一些机器学习的知识,各位如果已经了解可以直接跳过。
背景
随着机器学习和人工智能的火热发展,在许多领域,都有着人工智能带来的巨大进步,比如图像识别,文本情感分析。在安全领域也产生了许多利用人工智能进行安全防护和攻击的应用。比如利用GAN网络攻击图像识别系统,利用机器学习进行代码的漏洞寻找,利用深度学习进行代码的错误修复。
同时由于TensorFlow、keras等框架的诞生,使得搭建一个属于自己的机器学习网络并不再是一个繁琐的事情。本文讲以天池阿里云恶意软件检测比赛为例,介绍了如何利用机器学习进行恶意软件检测。
机器学习
特征提取
传统的机器学习中特征提取是一件十分重要的工作,基于一些先验知识对数据进行提取可以有效的增加最后结果的准确性。
- TF-IDF特征:词频-逆文档频率,用以评估词对于一个文档集或一个语料库中的其中一个文档的重要程度,计算出来是一个DxN维的矩阵,其中D为文档的数量,N为词的个数,通常会加入N-gram,也就是计算文档中N个相连词的的TF-IDF。

我们可以用sklearn快速提取TF-IDF特征:
vectorizer = TfidfVectorizer(ngram_range=(1, 5), min_df=3, max_df=0.9, ) # tf-idf特征抽取ngram_range=(1,5)
train_features = vectorizer.fit_transform(files)
out_features = vectorizer.transform(outfiles)
LDA(文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
LSI(文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
LDA(文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
LSI(文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
n-gram:N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
深度学习模型介绍
文本的表示
在日常中我们的文本是以文字形式进行显示的,然而机器是不能直接处理这种文字的,于是我们要把其转换成数字的形式。这里介绍one-hot编码和word embedding两种形式。
One-hot 编码
one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。程序中编码单词的一个方法是one hot encoding。
实例:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,...],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
a abbreviations zoology zoom这样一句子就可以由下图表示

也就是说,
在one hot representation编码的每个单词都是一个维度,彼此independent。
我们可以用keras_preprocessing.text import Tokenizer来快速把文字转换成one hot
tokenizer = Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~',
split=' ',
char_level=False,
oov_token=None)//分词器,把序列以空格分开成每一个词,在本比赛中为API CALL
tokenizer.fit_on_texts(files)
tokenizer.fit_on_texts(outfiles)
# with open("wordsdic.pkl", 'wb') as f:
# pickle.dump(tokenizer, f)
vocab = tokenizer.word_index
print(tokenizer.word_index)
print(len(vocab))
x_train_word_ids = tokenizer.texts_to_sequences(files)
x_out_word_ids = tokenizer.texts_to_sequences(outfiles)
x_train_padded_seqs = pad_sequences(x_train_word_ids, maxlen=maxlen)
x_out_padded_seqs = pad_sequences(x_out_word_ids, maxlen=maxlen)
Word embedding 词嵌入
one-hot编码在遇到特征种类和数量特别多的时候会非常不好。因为每个feature都要用一个M维的向量来表示,M是特征的种类数,这样一个样本就要用N*M维的矩阵来表示,N是总的feature数。这样一个样本会变得非常稀疏。所以有的时候我们用word embedding来对一个单词进行表示。
简单来说word embedding就是用一个词的上下文来表示这一个词,经过一系列的复杂运算,每个词都可以由一个n维向量表示,这个n不再是特征的总数,而可以理解为上下文的范围。
比如单词:baby 可能经过训练后可由[-0.2,0.1,0.15,0.24,0.45]这样一个向量表示,虽然每个位置单独没有意义,但是这样构成的向量的确是可以表示这一个单词的。
下图右边就是我们嵌入之后的矩阵,大小是N*M,N是所有的特征种类,M是我们定义的上下文表示的范围。
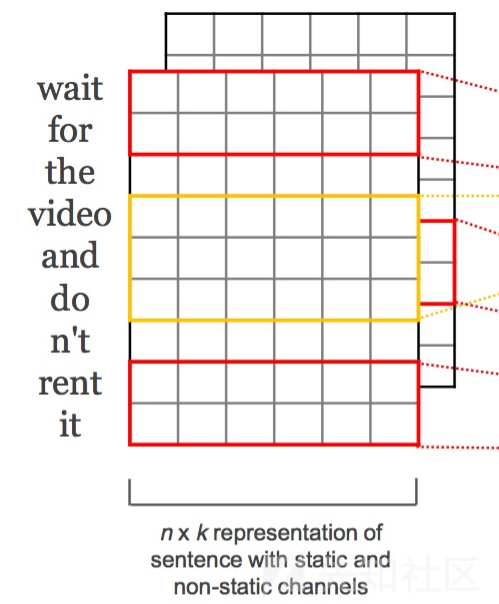
在keras中我们通常用embedding层来表示词嵌入。
main_input = Input(shape=(maxlen,))
emb = Embedding(len(vocab)+1, 256, input_length=maxlen)(main_input)//这里我们的m是256,
CNN卷积神经网络
卷积神经网络的名字来源于“卷积”运算。在卷积神经网络中,卷积的主要目的是从输入图像中提取特征。通过使用输入数据中的小方块来学习图像特征,卷积保留了像素间的空间关系。我们在这里不会介绍卷积的数学推导,但会尝试理解它是如何处理图像的。
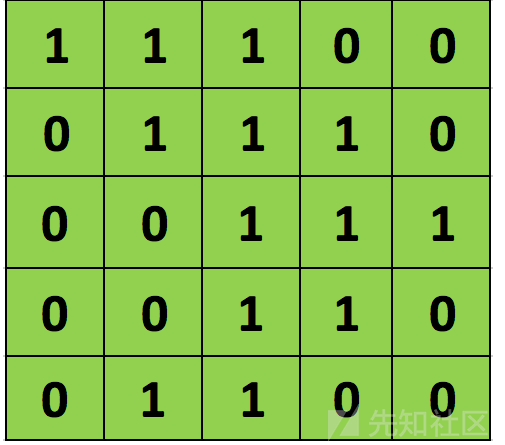
正如前文所说,每个图像可以被看做像素值矩阵。考虑一个像素值仅为0和1的5 × 5大小的图像(注意,对于灰度图像,像素值范围从0到255,下面的绿色矩阵是像素值仅为0和1的特殊情况):
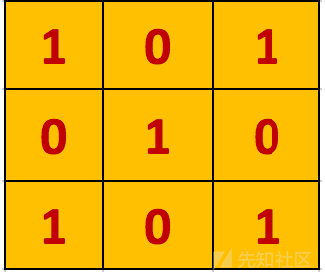
另外,考虑另一个 3×3 矩阵,如下图所示:
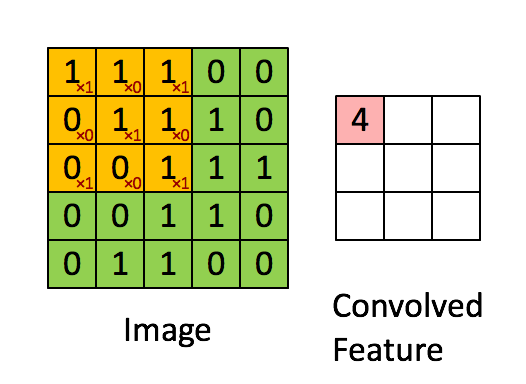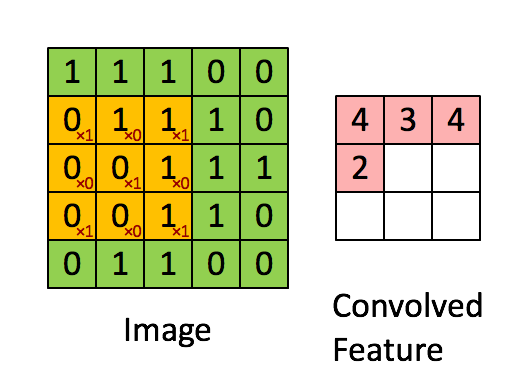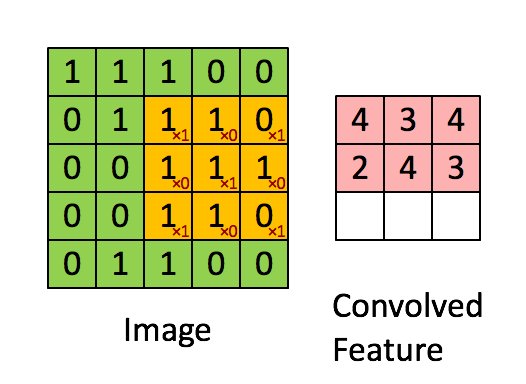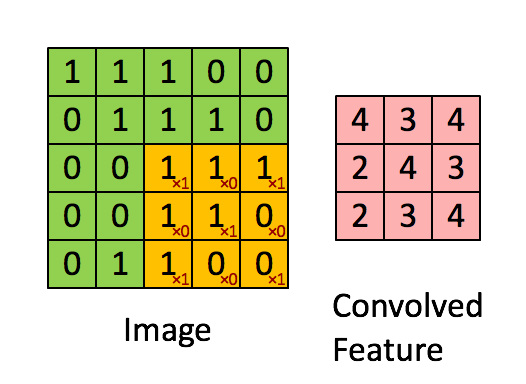
上述5 x 5图像和3 x 3矩阵的卷积计算过程如图中的动画所示:
我们来花点时间理解一下上述计算是如何完成的。将橙色矩阵在原始图像(绿色)上以每次1个像素的速率(也称为“步幅”)移动,对于每个位置,计算两个矩阵相对元素的乘积并相加,输出一个整数并作为最终输出矩阵(粉色)的一个元素。注意,3 × 3矩阵每个步幅仅能“看到”输入图像的一部分。
在卷积神经网路的术语中,这个3 × 3矩阵被称为“过滤器”或“核”或“特征探测器”,通过在图像上移动过滤器并计算点积得到的矩阵被称为“卷积特征”或“激活映射”或“特征映射”。重要的是要注意,过滤器的作用就是原始输入图像的特征检测器。
Text CNN
我们可以看到卷积是在对图像进行操作,那么对一个文本能不能也进行卷积呢,其实也是可以的。
CNN原核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
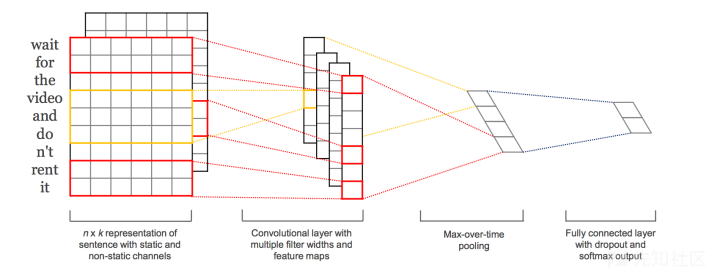
RNN
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 the clouds are in the sky最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
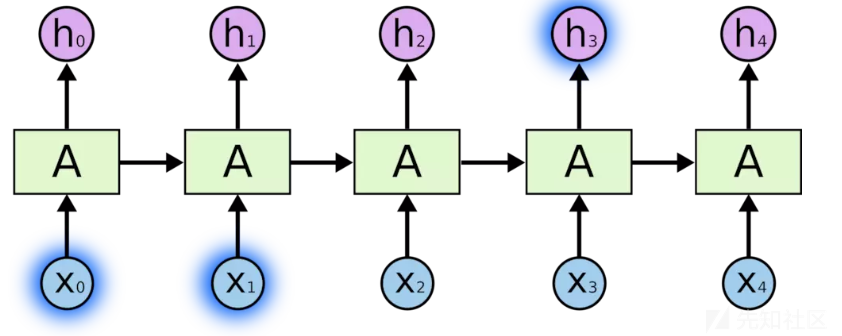
也就是说RNN在获取长序列上下文关系的时候效果很好。
LSTM
LSTM是RNN的一个变种,LSTM 通过刻意的设计来避免长期依赖问题,记住长期的信息。
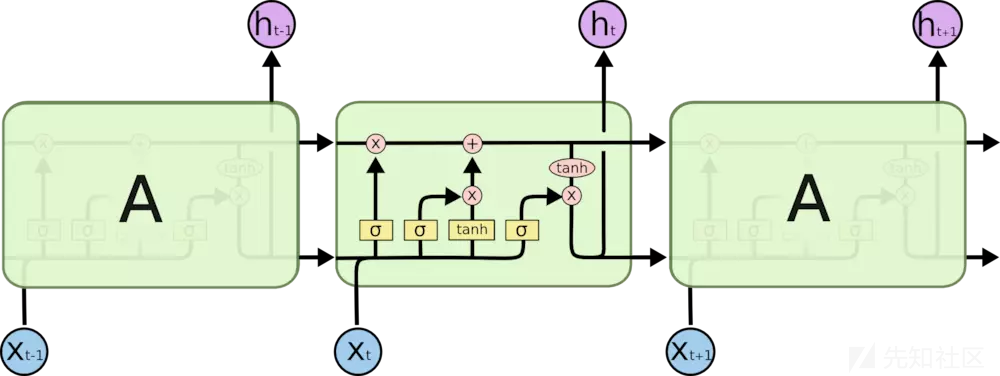
阿里云恶意软件检测
本题目提供的数据来自文件(windows 可执行程序)经过沙箱程序模拟运行后的API指令序列,全为windows二进制可执行程序,经过脱敏处理。
本题目提供的样本数据均来自于从互联网。其中恶意文件的类型有感染型病毒、木马程序、挖矿程序、DDOS木马、勒索病毒等,数据总计6亿条。
数据说明
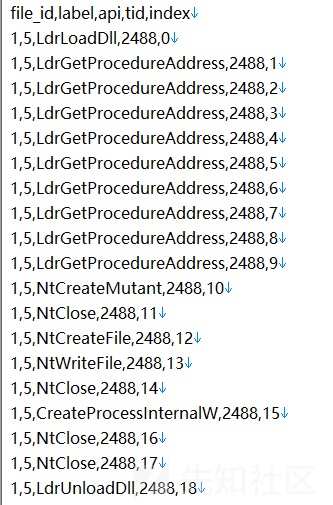
- 训练数据(train.zip):调用记录近9000万次,文件1万多个(以文件编号汇总),字段描述如下:
| 字段 | 类型 | 解释 |
|---|---|---|
| file_id | bigint | 文件编号 |
| label | bigint | 文件标签,0-正常/1-勒索病毒/2-挖矿程序/3-DDoS木马/4-蠕虫病毒/5-感染型病毒/6-后门程序/7-木马程序 |
| api | string | 文件调用的API名称 |
| tid | bigint | 调用API的线程编号 |
| index | string | 线程中API调用的顺序编号 |
注1:一个文件调用的api数量有可能很多,对于一个tid中调用超过5000个api的文件,我们进行了截断,按照顺序保留了每个tid前5000个api的记录。
注2:不同线程tid之间没有顺序关系,同一个tid里的index由小到大代表调用的先后顺序关系。
注3:index是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,所以会出现一个index上出现同线程或者不同线程都在执行多次api的情况,可以保证同tid内部的顺序,但不保证连续。
- 测试数据(test.zip):调用记录近8000万次,文件1万多个。
说明:格式除了没有label字段,其他数据规格与训练数据一致。
评测指标
1.选手的结果文件包含9个字段:file_id(bigint)、和八个分类的预测概率prob0, prob1, prob2, prob3, prob4, prob5 ,prob6,prob7 (类型double,范围在[0,1]之间,精度保留小数点后5位,prob<=0.0我们会替换为1e-6,prob>=1.0我们会替换为1.0-1e-6)。选手必须保证每一行的|prob0+prob1+prob2+prob3+prob4+prob5+prob6+prob7-1.0|<1e-6,且将列名按如下顺序写入提交结果文件的第一行,作为表头:file_id,prob0,prob1,prob2,prob3,prob4,prob5,prob6,prob7。
2.分数采用logloss计算公式如下:
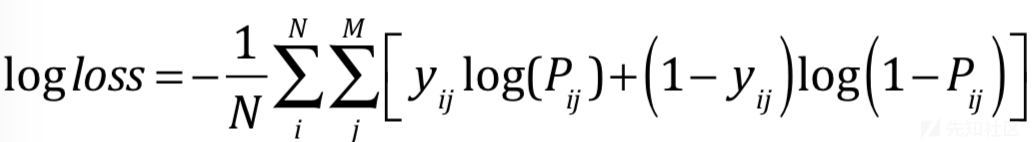
M代表分类数,N代表测试集样本数,yij代表第i个样本是否为类别j(是~1,否~0),Pij代表选手提交的第i个样本被预测为类别j的概率(prob),最终公布的logloss保留小数点后6位。
分析:可以看出,其实这就是一个序列分类的问题,如何从一串超长的文本序列中提取出信息并进行分类的问题。
文件预处理
我首先把每个样本根据file_id进行分组,对每个分组把多个线程内部的API CALL调用序列排好,再把每个线程排好后的序列拼接成一个超长的字符串。
def read_train_file(path):
labels = []
files = []
data = pd.read_csv(path)
# for data in data1:
goup_fileid = data.groupby('file_id')//不同的文件
for file_name, file_group in goup_fileid:
print(file_name)
file_labels = file_group['label'].values[0]//获取label
result = file_group.sort_values(['tid', 'index'], ascending=True)//根据线程和顺序排列
api_sequence = ' '.join(result['api'])
labels.append(file_labels)
files.append(api_sequence)
print(len(labels))
print(len(files))
with open(path.split('/')[-1] + ".txt", 'w') as f:
for i in range(len(labels)):
f.write(str(labels[i]) + ' ' + files[i] + '\n')
Sample
LdrLoadDll LdrGetProcedureAddress LdrGetProcedureAddress LdrGetProcedureAddress LdrGetProcedureAddress.......
label 5可以看出,这样其实是不严谨的,因为题中说到不同的线程之间是没有顺序关系的,但是我这里还是这么做了,结果发现还是不错的,如果各位有更好的思路可以告诉我。
模型
本次比赛中,我采用了5个模型,然后进行了模型融合,得到了最后的结果
TF-idf 模型:
为了获取长序列的整体信息,我用了基于n-gram的TF-IDF模型,我提取了连续1-5的TF-idf特征,然后组成了样本的特征,并用xgboost进行了分类。
此模型可以方便的获取样本整体各个API调用序列的分布情况。
vectorizer = TfidfVectorizer(ngram_range=(1, 5), min_df=3, max_df=0.9, ) # tf-idf特征抽取ngram_range=(1,5)
用XGBOOST模型进行简单分类
dtrain = xgb.DMatrix(X_train, label=X_train_label)
dtest = xgb.DMatrix(X_val, X_val_label)
dout = xgb.DMatrix(out_features)
param = {'max_depth': 6, 'eta': 0.1, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.8,
'colsample_bytree': 0.85} # 参数
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 300 # 循环次数
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=50)
Text cnn模型
本模型,我用了text cnn进行特征提取并分。首先由于GPU显存的原因,我只能把样本序列的长度定到6000,然后使用了2,3,4,5 四个不同的卷积核提取不同视野的信息,然后将其结果拼接在一起,输入一个全连接层进行判断
main_input = Input(shape=(maxlen,), dtype='float64')
_embed = Embedding(304, 256, input_length=maxlen)(main_input)//词嵌入
_embed = SpatialDropout1D(0.25)(_embed)
warppers = []
num_filters = 64
kernel_size = [2, 3, 4, 5]
conv_action = 'relu'
for _kernel_size in kernel_size:
for dilated_rate in [1, 2, 3, 4]:
conv1d = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation=conv_action,
dilation_rate=dilated_rate)(_embed)
warppers.append(GlobalMaxPooling1D()(conv1d))//卷积层
fc = concatenate(warppers)
fc = Dropout(0.5)(fc)
fc = Dense(256, activation='relu')(fc)//全连接层
fc = Dropout(0.25)(fc)
preds = Dense(8, activation='softmax')(fc)
model = Model(inputs=main_input, outputs=preds)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model

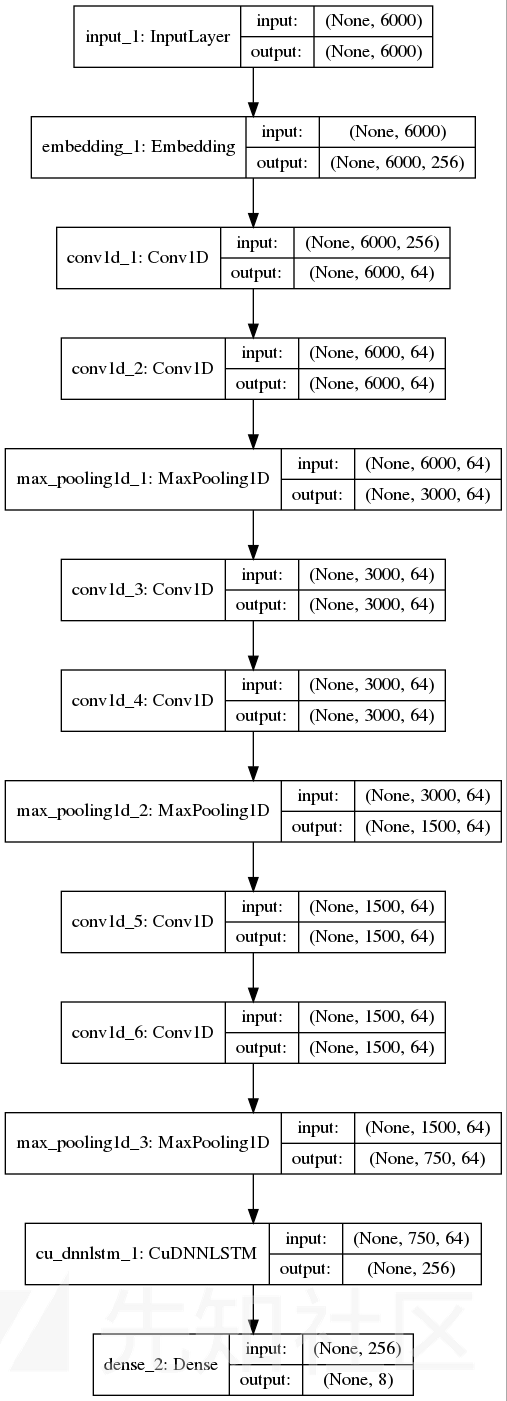
CNN_LSTM model
为了获取序列的上下文信息,我们这里用了CNN+LSTM的组合形式,首先先用CNN对文本进行一定的特征提取,降低序列的长度,然后再输入LSTM进行判断。这样比直接使用LSTM的训练速度会有大量的提高
main_input = Input(shape=(maxlen,), dtype='float64')
embedder = Embedding(304, 256, input_length=maxlen)
embed = embedder(main_input)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(embed)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(cnn1)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(cnn1)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
rl = CuDNNLSTM(256)(cnn1)
# flat = Flatten()(cnn3)
# drop = Dropout(0.5)(flat)
fc = Dense(256)(rl)
main_output = Dense(8, activation='softmax')(rl)
model = Model(inputs=main_input, outputs=main_output)
return model
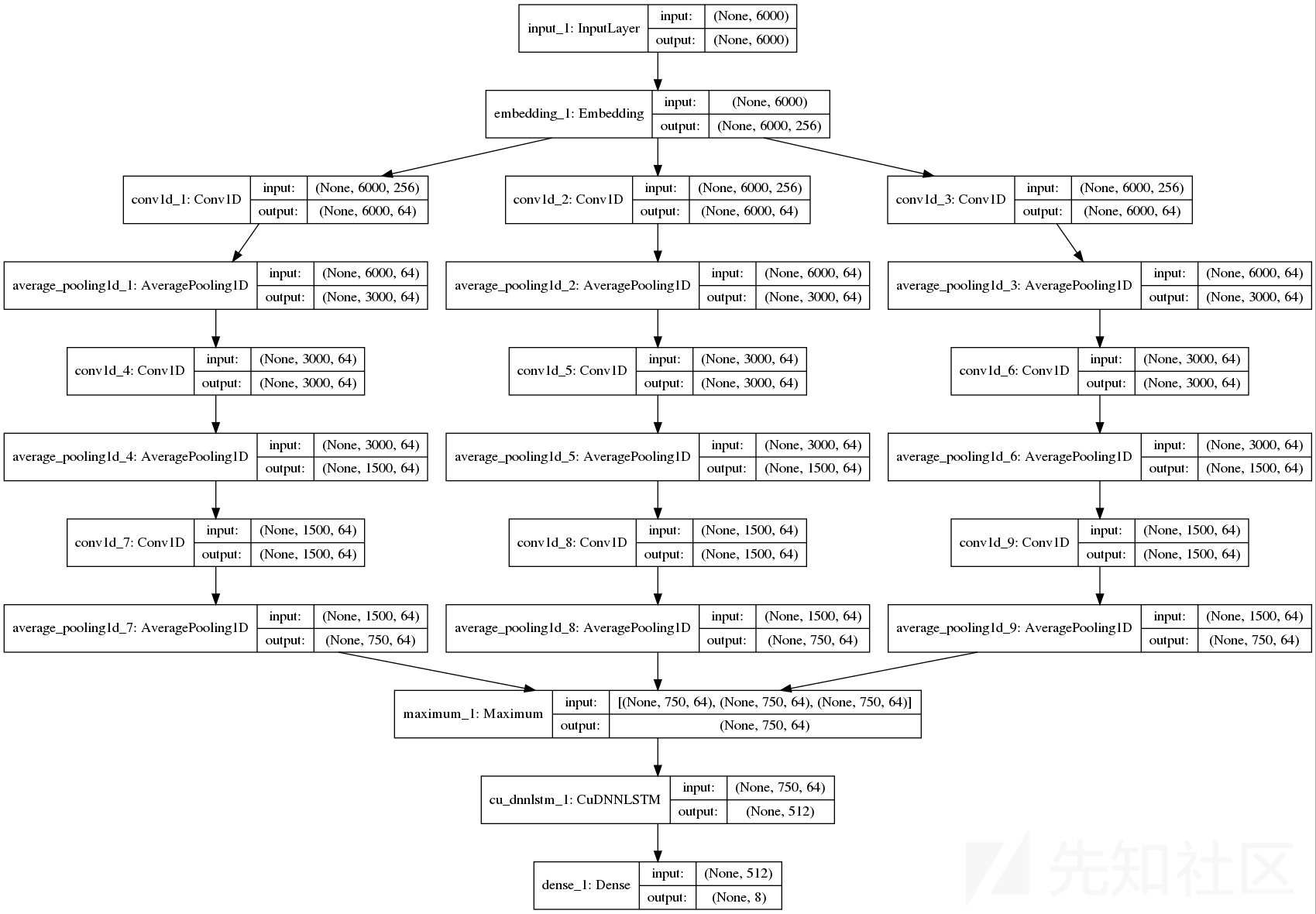
Mulit version LSTM
收到多卷积核的Text CNN 的启发,我想是否能用多视野的LSTM来进行学习,我首先参考TEXT CNN 采用了3,5,7 三种卷积核对词嵌入向量进行特征提取,获取不同视野的情况,并且每层提取完之后使用了平均池化,而不是最大池化,因为我更想获取连续序列的信息而不是单个的API CALL的特征。完成之后我获得了三个相同大小的特征向量v1 v2 v3,我对这三个特征向量的每一个元素进行了如下操作,转换成一个向量
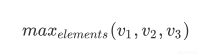
对每个位置的元素,在三个向量里取最大值作为新的向量,最后三个向量又重新构成了一个新的向量,我把这个向量再次丢入LSTM中进行学习。
embed_size = 256
num_filters = 64
kernel_size = [3, 5, 7]
main_input = Input(shape=(maxlen,))
emb = Embedding(304, 256, input_length=maxlen)(main_input)
# _embed = SpatialDropout1D(0.15)(emb)
warppers = []
warppers2 = []
warppers3 = []
for _kernel_size in kernel_size:
conv1d = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(emb)
warppers.append(AveragePooling1D(2)(conv1d))
for (_kernel_size, cnn) in zip(kernel_size, warppers):
conv1d_2 = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(cnn)
warppers2.append(AveragePooling1D(2)(conv1d_2))
for (_kernel_size, cnn) in zip(kernel_size, warppers2):
conv1d_2 = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(cnn)
warppers3.append(AveragePooling1D(2)(conv1d_2))
fc = Maximum()(warppers3)
rl = CuDNNLSTM(512)(fc)
main_output = Dense(8, activation='softmax')(rl)
model = Model(inputs=main_input, outputs=main_output)
return model
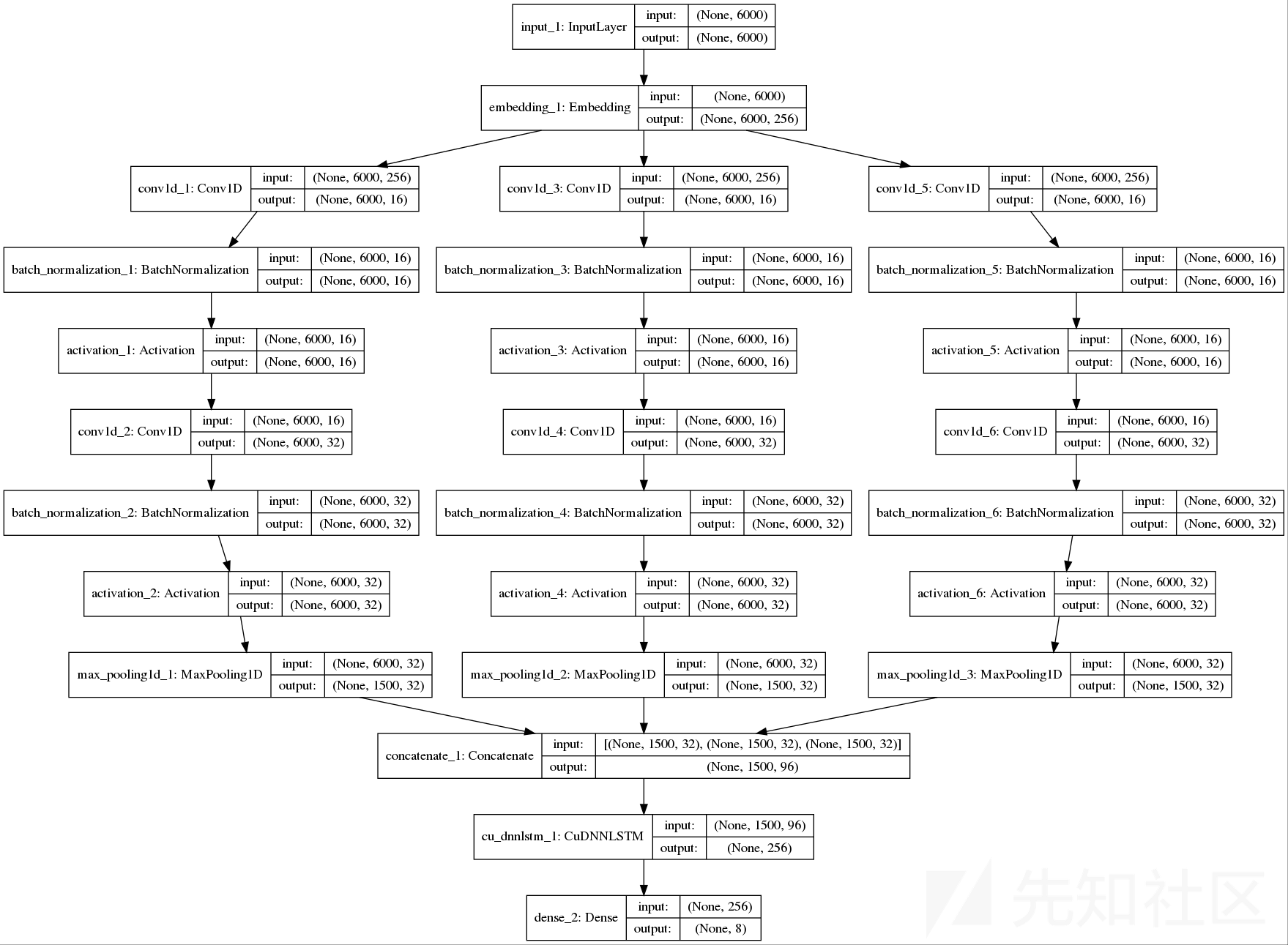
Text cnn lstm
这个和上面的多视野LSTM类似,只不过这里对最后的三个向量我没有使用MAX的方式,而是把它们三个拼接成一个长序列,我认为这样的方式并不会改变每个特征向量内部提取的API 调用的关系,只是把三个块线性的连接在一起了。同样也能获得比较好的效果。
main_input = Input(shape=(maxlen,), dtype='float64')
embedder = Embedding(304, 256, input_length=maxlen)
embed = embedder(main_input)
# cnn1模块,kernel_size = 3
conv1_1 = Conv1D(16, 3, padding='same')(embed)
bn1_1 = BatchNormalization()(conv1_1)
relu1_1 = Activation('relu')(bn1_1)
conv1_2 = Conv1D(32, 3, padding='same')(relu1_1)
bn1_2 = BatchNormalization()(conv1_2)
relu1_2 = Activation('relu')(bn1_2)
cnn1 = MaxPool1D(pool_size=4)(relu1_2)
# cnn2模块,kernel_size = 4
conv2_1 = Conv1D(16, 4, padding='same')(embed)
bn2_1 = BatchNormalization()(conv2_1)
relu2_1 = Activation('relu')(bn2_1)
conv2_2 = Conv1D(32, 4, padding='same')(relu2_1)
bn2_2 = BatchNormalization()(conv2_2)
relu2_2 = Activation('relu')(bn2_2)
cnn2 = MaxPool1D(pool_size=4)(relu2_2)
# cnn3模块,kernel_size = 5
conv3_1 = Conv1D(16, 5, padding='same')(embed)
bn3_1 = BatchNormalization()(conv3_1)
relu3_1 = Activation('relu')(bn3_1)
conv3_2 = Conv1D(32, 5, padding='same')(relu3_1)
bn3_2 = BatchNormalization()(conv3_2)
relu3_2 = Activation('relu')(bn3_2)
cnn3 = MaxPool1D(pool_size=4)(relu3_2)
# 拼接三个模块
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
lstm = CuDNNLSTM(256)(cnn)
f = Flatten()(cnn1)
fc = Dense(256, activation='relu')(f)
D = Dropout(0.5)(fc)
main_output = Dense(8, activation='softmax')(lstm)
model = Model(inputs=main_input, outputs=main_output)
return model
Stack result
最后我把上面5个模型的结果结合起来,再用一个XGBOOST进行判断,获得了我最后的结果。
train = np.hstack([tfidf_train_result, textcnn_train_result, mulitl_version_lstm_train_result, cnn_train_result,
textcnn_lstm_train_result])
test = np.hstack(
[tfidf_out_result, textcnn_out_result, mulitl_version_lstm_test_result, cnn_out_result, textcnn_lstm_test_result])
meta_test = np.zeros(shape=(len(outfiles), 8))
skf = StratifiedKFold(n_splits=5, random_state=4, shuffle=True)
dout = xgb.DMatrix(test)
for i, (tr_ind, te_ind) in enumerate(skf.split(train, labels)):
print('FOLD: {}'.format(str(i)))
X_train, X_train_label = train[tr_ind], labels[tr_ind]
X_val, X_val_label = train[te_ind], labels[te_ind]
dtrain = xgb.DMatrix(X_train, label=X_train_label)
dtest = xgb.DMatrix(X_val, X_val_label)
param = {'max_depth': 6, 'eta': 0.01, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.9,
'colsample_bytree': 0.85} # 参数
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 10000 # 循环次数
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=100)
preds = bst.predict(dout)
meta_test += preds
meta_test /= 5.0
result = meta_test
Result

绕过方法
本文提出的检测方法并不完善,有许多的绕过方法,现提出一些我想到,抛砖引玉。
- TF-IDF的方式获取的词语的整体信息,可以恶意病毒的调用API过程中随机插入调用一些其他的序列,破坏其API调用的特征和各个API调用序列的整体分布情况,达到绕过的效果。
- 基于深度学习的方法对序列的长度有着较大的限制,病毒制作者可以一开始先调用一些无关的API,等调用长度超出深度学习检测的限制的时候再开始调用恶意API