对付慢速爬虫的“艰难”探索
在我的定义里,爬虫在速度上一般有两种级别:在短时间内把你爬死的和鬼子进村悄悄滴慢慢爬你的。
前一种爬虫步子迈得太大,容易扯到蛋,被运维同学通过突发资源消耗或者简单频控就能识别出来。
后一种爬虫比较恶心,它爬取的速度很慢,隐藏在滚滚业务洪流中,隐蔽性极强,危害极高,识别难度也很高,就十分气人,我通常称呼它为慢速爬虫。
当然了,还有一些爬虫用了Headless的浏览器模拟人类请求,或者干脆就透过某些垃圾公司的客户端软件在屏幕(9999,9999)坐标处显示一个“不可见”的浏览器偷偷搞分布式“爬虫”。这种公司臭不要脸,迟早要倒闭,我们先鄙视它一下。
同志们,我每次要谈论的话题都很沉重,都涉及到程序员的相爱相杀(我觉得主要责任在于PM和运营)。虽说本是同根生,但是不搞你我就没饭吃了。下面就来说一下我在做慢速爬虫识别过程中遇到的曲折道路和艰难探索。
一、慢速爬虫的共性特征
慢速爬虫为什么恶心呢,就是因为它太慢了。
我们历史上通过一些人工的方式发现了几个慢速爬虫,当时我们对慢速爬虫做了一点简单的提炼,这里摘录一部分——
以我司全站为例(因数据保密需要,本文涉及到的所有运营数据都随机做了加减乘除,连标点符号都别信哈)平均每天有8亿个请求,发现的慢速爬虫每秒的平均请求数在0.1个左右,相差悬殊。
因为日志量比较多,我们的访问日志中有48小时左右的热数据在ELK上可供实时分析。所以我们把时间维度从分钟拉到24小时,试图从更久的时间上看看爬虫的访问情况:

(图片:在24小时时间维度内,某慢速爬虫的访问分布)
显然,在中短期时间维度内,爬虫访问较无规律,似乎有随机因子在干扰。不过在中长期的时间维度内,我们发现慢速爬虫的访问丰度较高。即,在一段时间的每个时间切片内,慢速爬虫活跃程度与一般用户有显著区别。
从此前的提炼上可以得知,慢速爬虫的访问分布和访问丰度和正常用户相比都不太科学,我们以此入手尝试分析看看。
很快我们上线测试了第一个带有明显A股特色(T+1天)的分析小程序,通过分析前一天的日志,建立5分钟级别的时间切片,然后筛选出可能的慢速爬虫以供运维大哥封IP。
一天后,结果出来,近1万个IP被程序归类到慢速爬虫中。顿时美滋滋的心情就不复存在,心里就咯噔一下——量级不对,完了,别是识别错了。
随后的抽样检查结果证实了这个判断。原因很简单,我们有一部分客户端程序可能会被切到后台中运行,后台运行的程序的确会定时发起请求,这样在访问日志上体现出来的结果就和慢速爬虫高度一致。
让PM改掉这个功能?不可能的,改功能是不可能改的,这辈子都不可能改了。那这样又不能用,只能靠加大数据量这个办法才能维持得了准确率这个样子。

(PM听到我妄图砍功能时候的表情)
欸……我刚刚是不是说了加大数据量?如果1天不行,那我就把时间放大到30天如何?总不至于有用户连续30天不关机不杀进程吧?
二、海量数据带来的可行方案讨论:滑动时间窗口计数
30天啊!240亿条请求啊!我要查找一个IP的访问情况我是不是得遍历这240亿条?我每隔5分钟是不是要重新在内存中淘汰掉前五分钟的数据是不是又要遍历一次?
我要是一天光遍历就要8亿次(假设每次请求都校验一下),这……太湖之光了解一下?
虽说数据是海量的,但在这个场景中,我们有效信息只有IP和IP访问分布情况。仔细想想,24小时内5分钟切片的话共有288块,那扩展到30天之后是不是还需要5分钟切一次呢?一小时切一次可不可以?
这时候我想到一个非常“绝妙”的方法,如果以小时为单位进行切片,可以将时间戳降为一个不超过720(30天*24小时)的索引。计算方法为:
(int)({Timestamp} / 3600) % 721
我们可以为每一个IP建立一个长度是721的无符号整形数组,这个数组内每一个元素代表这个IP在对应小时索引内的访问次数。我这里画一下图——

如图所示,我们通过建立这个滑动计数窗口,使得整个计数过程变得如丝般顺滑,非常优美。
(思考题:为什么这里是取余数用的是721而不是720?)
而且这样一来,我们需要维护的信息被降维了,省去了原先记录每个访问时间戳时不可避免的排序过程。而且对于任意一个IP,我们需要维护的核心数据长度变为 721 * 4字节 = 2884字节,1亿条独立IP所消耗的内存空间约为270G。
等等,我们最早不是说目标的数据集合预估会有240亿条,怎么这里按照1亿条独立IP计算?
大哥,IPv4的地址空间只有2^32,除去保留地址之后全世界能用的不到37亿条,还有不少IP被机构、学校、政府、ISP搞走了。根据16年末某国内互联网发展报告显示,全国网民独立IP数为2.2亿个……1亿个已经占了50%好不好,我们是小厂啊大哥。
(P.S: 事实上,我们对240亿条IP去重后,发现独立IP数在千万这个级别)
三、算法与数据结构的比拼:哈希表拯救世界
那有了上面这么优美的数据结构,我们赶紧去实现呗~
于是我们定义一个数据结构:
struct ip_tree {
uint8_t ip_addr[4];
uint32_t timeline[721];
};
然后做个链表链一下,感觉依然十分优美……吧。
再于是我们就喂了下数据……刚开始还好,但是随着时间的增加程序变得越来越慢。艾玛卧槽,我咋写了个时间复杂度是O(n)的玩意儿?
那就些不太优美了,得优化一下,O(n)复杂度接受不了啊。回想一下,IP地址本身即是一个高度为4的256叉树,点分位已经替我们完成了层级的分割。
因为固定高度的256叉树的存在,我们把IP查找问题就转换成了一个“哈希表查找”,时间复杂度变成了O(1),十分优美。
经过改造后的数据结构变成这样:
struct last_node {
unsigned char ip_addr;
uint16_t timeline[721];
struct last_node *next;
};
struct tree_node {
unsigned char ip_addr;
void *child; //这里弄成一个void指针,其可能是last_node类型,也可能是tree_node类型
struct tree_node *next;
};
其中,last_node结构体用于具体描述IP的访问分布,tree_node结构体更多的是用作索引,用来快速的检索真正需要的last_node元素。
在我们自己的实现中,最终tree_node / last_node都采用了链表的方式实现。但实际上,对于独立IP数很高的大厂,tree_node可以用数组的方式进行更加快速的查找,也会更加的优美。(链表查找需要遍历,数组查找仅需计算地址)
一番调整后,整个思路终于得以被完整实现。这下可以美滋滋了?显然不是。
四、拒绝逐个比特遍历:亿级IP访问密度高速计算优化
数据已经是收集起来了,但很快我们又遇到一个问题。
因为方案采取的是T+1输出慢速爬虫可疑IP列表,所以我们会发现,系统负载每到整小时的时候(起了另一个线程去计算)就出现大量的增加,甚至于影响了整体的性能。
就很气,就不太优美。
仔细检查了下原先的逻辑:
遍历整棵树 -> 遍历每个last_node中的timeline数组 -> 根据遍历结果计算可疑IP
很显然在这个过程中我们几乎遍历了整个内存空间,这个空间有多大呢——109GB:
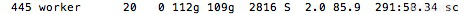
但是我们真的需要这么做么?其实我只关心的是,这个IP地址在这个小时内“有没有”发生过访问,实质上是一个布尔值。为了一个布尔值去遍历整个字节,是不是有些不太值得,更重要的是不太优美?
好的,那再来优化性能,这回用的是位图。
咳咳咳,解释一下这里的位图。这货不是“苍老师.BMP”这个玩意儿,而是一个特殊的数据结构,它是一大堆连续布尔值的集合,对于其中一个布尔值用特定位置的一个比特表示。
即,如果一个1字节的位图,它可以表示成连续8个布尔值。比如,0xBF = 10111111
我们将上面提到的timeline用位图表示,就可以变成char bitmap[91],遍历的内存范围缩小为原来的约6%。
紧接而来的是另一个问题:如何快速的对给定的一串字节,从中获取为1的位的个数?
马上能想到的方案有两种:
遍历每个位,计算1的个数,或者,创建一个固定长度的位图表,查表得出1的个数。
显然第二种做法是用空间换时间,位图表越长,检索的次数就越少,相应的占用的空间会越多。比如一个32位的位图表,它就将占用 (2^32) * (16+8) = 12GB的空间。这丝毫不能缓解我们的担忧嘛……不行,不优美,不要这个方案。
有没有一种方案就像编译器优化乘法一样,用一些类似魔数+移位的方式来获得1的个数呢?
嘿嘿嘿,当然有。
MIT曾经在一份备忘录中提到过类似的算法,它将一个定长整数经过移位和一些简单的逻辑运算后得到这个整数中1的个数。具体算法如下:
uint8_t count1(uint32_t x) {
x = (x & 0x55555555UL) +((x >> 1) & 0x55555555UL);
x = (x & 0x33333333UL) +((x >> 2) & 0x33333333UL);
x = (x & 0x0f0f0f0fUL) +((x >> 4) & 0x0f0f0f0fUL);
x = (x & 0x00ff00ffUL) +((x >> 8) & 0x00ff00ffUL);
x = (x & 0x0000ffffUL) +((x >> 16) & 0x0000ffffUL);
return x;
}
那这样一来,其实有两种方案可选,一种是将位图表缩小到16位进行查表操作,一种是使用这个移位算法。
我们需要对比一下两种方案的优劣。
对于查表操作,表面上看效果很好,只需要进行一次寻址过程即可大功告成。而移位算法需要进行10 次 &, 5 次移位, 5 次加法,看起来会慢一些。
虽然查表过程只需要1次寻址,但这个寻址是在内存中进行的,即CPU至少需要一个访问内存的指令。在现在的CPU结构中,内存的速度比起CPU来说是很慢的,大约需要250个时钟周期。移位算法如果能全部在寄存器中操作,则只需要 10 + 5 + 5 = 20 个时钟周期。
250 >> 20。
是是是,你没说错,CPU的L1确实比内存要快很多。但L1不由我们控制,而且你要把192KB的一张大表(对于L1可怜巴巴的那点大小而言)放到L1中。指令不要缓冲了(数据也放不进指令缓存)?流水线不用预测了?都给你放完L1我挖矿怎么办?寄希望于把表缓到L1里加速不现实,也不优美。
回过头我们使用-O3来编译移位算法,看看是不是符合我们的设想:

果然,它全部变成了寄存器和立即数的操作。
到这个份儿上了还能优化吗?当然可以!call和retn指令需要整理堆栈信息,而且还容易有一个大大的jmp到处乱飞。我们把这段内联汇编(或者就直接拿源代码)写成一个宏,抛弃耗时的函数调用过程。
现在这样,就很优美了。
五、最终结果:一台128GB内存的机器撑起了一片天空
经过调整后的服务很快就上线了,正如上面截图所示,我们花了100多GB的内存撑起了这个服务。而且经过一段时间的验证,我们通过这个小功能(虽然优化过程很坎坷),发现了潜藏很久的慢速爬虫。

我也深知,反爬虫的挑战其实是丰富多样的,仅凭IP一个维度的数据很难观察到事件的核心。事实上,我们除了对访问分布进行监控外,依然安排了很多其他措施共同对抗爬虫的“入侵”。仅凭一把武器是拿不下一场战争的,只有对事件进行多维度的描述,才能够更接近本质。与君共勉
最后致个歉,大家看我唠唠叨叨BB了这么多个字,源码呢?很抱歉,受制于保密协议,我不能提供这个工具的源代码,还请大家谅解。