用侧信道读取特权内存(上)
本文是Reading privileged memory with a side-channel的翻译文章。下篇见这里
前言
我们发现,CPU数据高速缓存时序可能会被滥用,从错误推测的执行中高效地泄漏信息,导致(最坏的情况下)各种上下文中跨本地安全边界的任意虚拟内存读取漏洞。
已知这个问题的变体会影响许多现代处理器,包括英特尔,AMD和ARM的某些处理器。对于少数英特尔和AMD CPU型号,我们有针对真正软件的攻击。我们在2017-06-01向英特尔,AMD和ARM报告了此问题[1] 。
到目前为止,这个问题有三种已知的变体:
- 变体1:边界检查旁路(CVE-2017-5753)
- 变体2:分支目标注入(CVE-2017-5715)
- 变体3:流氓数据缓存加载(CVE-2017-5754)
在此处所述的问题公开披露之前,Daniel Gruss,Moritz Lipp,Yuval Yarom,Paul Kocher,Daniel Genkin,Michael Schwarz,Mike Hamburg,Stefan Mangard,Thomas Prescher和Werner Haas也报告了这些问题; 他们的[writeups/博文/论文稿]可以在下面找到:
在我们的研究过程中,我们开发了以下概念验证(PoC):
- PoC演示了经测试的Intel Haswell Xeon CPU,AMD FX CPU,AMD PRO CPU和ARM Cortex A57 [2]中用户空间中变体1的基本原理。这个PoC只测试在同一个进程中读取错误推测执行的数据的能力,而不会跨越任何特权边界。
- 变种1的PoC在具有发行标准配置的现代Linux内核下以普通用户权限运行时,可以在Intel Haswell Xeon CPU上的内核虚拟内存中执行4GiB范围内的任意读取[3] 。如果内核的BPF JIT被启用(非默认配置),它也可以在AMD PRO CPU上运行。在Intel Haswell Xeon CPU上,大约4秒的启动时间后,内核虚拟内存可以以每秒2000字节左右的速度读取。[4]
- 对于版本2的PoC,当在基于Intel Haswell Xeon CPU的virt-manager创建的KVM guest虚拟机中以超级用户权限运行时,可以读取在主机上运行的特定(已过时)版本的Debian发行版内核[5]以大约1500字节/秒的速率托管内核内存,并具有优化空间。在执行攻击之前,对于具有64GiB RAM的机器,需要执行大约10到30分钟的初始化; 所需的时间应该与主机RAM的数量大致呈线性关系。(如果客户端有2MB大容量页面,初始化应该快得多,但是还没有经过测试。)
- 变种3的PoC在以正常用户权限运行时,可以在某种先决条件下读取Intel Haswell Xeon CPU上的内核内存。我们相信这个先决条件是目标内核内存存在于L1D缓存中。
有关此主题的有趣资源,请参阅“文献”部分。
在这篇博文中关于处理器内部解释的警告:这篇博文包含了很多关于基于观察到的行为的硬件内部的推测,这可能不一定对应于实际处理器。
我们对可能的缓解有一些想法,并向处理器供应商提供了其中的一些想法。然而,我们相信处理器供应商的地位远比我们设计和评估缓解措施更好,我们期望它们成为权威指导的来源。
我们发送给CPU供应商的PoC代码和写法可以在这里找到:https://bugs.chromium.org/p/project-zero/issues/detail?id=1272
测试处理器
- Intel(R) Xeon(R) CPU E5-1650 v3 @ 3.50GHz (本文档的其余部分称为“Intel Haswell Xeon CPU”)
- AMD FX(tm)-8320 Eight-Core Processor (本文档的其余部分称为“AMD FX CPU”)
- AMD PRO A8-9600 R7, 10 COMPUTE CORES 4C+6G (本文档的其余部分称为“AMD PRO CPU”)
- An ARM Cortex A57 core of a Google Nexus 5x phone [6] (本文档的其余部分称为“ARM Cortex A57”)
词汇表
退出(retire):当其结果(例如寄存器写入和存储器写入)被提交并使其对系统的其他部分可见时,指令退出。指令可以不按顺序执行,但必须按顺序退出。
逻辑处理器核心(logical processor core):逻辑处理器核心是操作系统认为的处理器核心。启用超线程后,逻辑核心的数量是物理核心数量的倍数。
缓存/未缓存的数据(cached/uncached data):在本文中,“未缓存”的数据是仅存在于主内存中的数据,而不是CPU的任何缓存级别中的数据。加载未缓存的数据通常需要超过100个CPU时间周期。
推测性执行(speculative execution):处理器可以执行经过分支而不知道其是否被采用或其目标在何处,因此在知道它们是否应该被执行之前执行指令。如果这种推测结果不正确,那么CPU可以放弃没有架构效应的结果状态,并继续在正确的执行路径上执行。在知道它们处于正确的执行路径之前,指令不会退出。
错误推测窗口(mis-speculation window):CPU推测性地执行错误代码并且尚未检测到错误发生的时间窗口。
变体1:边界检查旁路
本节解释所有三种变体背后的常见理论,以及我们PoC变体1背后的理论,在Debian distro内核下运行在用户空间中时,可以在内核内存的4GiB区域执行任意读取,至少在以下配置中:
- Intel Haswell Xeon CPU,eBPF JIT关闭(默认状态)
- Intel Haswell Xeon CPU,eBPF JIT打开(非默认状态)
- AMD PRO CPU,eBPF JIT打开(非默认状态)
eBPF JIT的状态可以使用net.core.bpf_jit_enable sysctl进行切换。
理论解释
“英特尔优化参考手册”在第2.3.2.3节(“分支预测”)中对Sandy Bridge(以及后来的微架构修订版)进行了如下说明:
分支预测预测分支目标并启用该分支
处理器在分支之前很久就开始执行指令
真正的执行路径是已知的。
在第2.3.5.2节(“L1 DCache”)中:
负载可以:
[...]
在前面的分支得到解决之前进行推测。
不按顺序并以重叠方式进行缓存未命中。
英特尔软件开发人员手册[7]在第3A卷第11.7节(“隐式高速缓存(Pentium 4,Intel Xeon和P6系列处理器)”中声明:
隐式高速缓存发生在内存元素具有可缓存性时,尽管该元素可能永远不会以正常的冯诺依曼序列被访问。由于积极的预取,分支预测和TLB未命中处理,隐式高速缓存出现在P6和更新的处理器系列上。隐式缓存是现有Intel386,Intel486和Pentium处理器系统行为的扩展,因为在这些处理器系列上运行的软件也无法确定性地预测指令预取的行为。
考虑下面的代码示例。如果arr1-> length 未缓存,则处理器可以推测性地从arr1-> data [untrusted_offset_from_caller] 加载数据。这是一个超出界限的阅读。这应该不重要,因为处理器将在分支执行时有效回滚执行状态; 推测性执行的指令都不会退出(例如导致寄存器等被影响)。
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...;
unsigned long untrusted_offset_from_caller = ...;
if (untrusted_offset_from_caller < arr1->length) {
unsigned char value = arr1->data[untrusted_offset_from_caller];
...
}
但是,在下面的代码示例中,存在一个问题。如果arr1-> length,arr2-> data [0x200] 和arr2-> data [0x300] 没有被缓存,但所有其他被访问的数据都是,并且分支条件预测为true,处理器可以在加载arr1-> length并重新执行之前进行如下推测:
load value = arr1-> data [ untrusted_offset_from_caller ]- 从
arr2-> data中的数据相关偏移量开始加载,将相应的高速缓存行加载到L1高速缓存中在执行返回到非推测路径后,因为处理器注意到struct array { unsigned long length; unsigned char data[]; }; struct array *arr1 = ...; /* small array */ struct array *arr2 = ...; /* array of size 0x400 */ /* >0x400 (OUT OF BOUNDS!) */ unsigned long untrusted_offset_from_caller = ...; if (untrusted_offset_from_caller < arr1->length) { unsigned char value = arr1->data[untrusted_offset_from_caller]; unsigned long index2 = ((value&1)*0x100)+0x200; if (index2 < arr2->length) { unsigned char value2 = arr2->data[index2]; } }
untrusted_offset_from_caller大于arr1-> length,包含arr2-> data [index2]的高速缓存行停留在L1高速缓存中。 通过测量加载arr2-> data [0x200]和arr2-> data [0x300]所需的时间,攻击者可以确定推测执行过程中index2的值是0x200还是0x300--它揭示了arr1-> data [untrusted_offset_from_caller] &1是0还是1。
为了能够实际将这种行为用于攻击,攻击者需要能够在目标上下文中使用超出边界的索引执行此类易受攻击的代码模式。 为此,易受攻击的代码模式必须存在于现有代码中,或者必须有可用于生成易受攻击代码模式的解释器或JIT引擎。 到目前为止,我们还没有确定任何现有的可利用的易受攻击的代码模式实例; 变体1泄漏内核内存的PoC使用eBPF解释器或eBPF JIT引擎,这些引擎内置于内核中并可供普通用户访问。
这个小的变体可能可以代替使用一个越界读取函数指针来获取错误推测路径中的执行控制权。我们没有进一步调查这个变种。
内核攻击
本节更详细地介绍如何使用eBPF字节码解释器和JIT引擎,使用变体1来泄漏Linux内核内存。尽管变体1攻击有许多有趣的潜在目标,但我们选择攻击Linux内核eBPF JIT /解释器,因为它比其他大多数JIT提供了更多的对攻击者的控制。
Linux内核自3.18版开始支持eBPF。非特权用户空间代码可以将内核提供的字节码提供给内核,然后:
- 由内核字节码解释器解释
- 翻译成本机机器码,该机器码也使用JIT引擎在内核上下文中运行(它翻译单个字节码指令而不执行任何进一步的优化)
字节码的执行可以通过将eBPF字节码作为过滤器附加到套接字上,然后通过套接字的另一端发送数据来触发。
JIT引擎是否启用取决于运行时配置设置 - 但至少在测试过的Intel处理器上,攻击独立于此设置工作。
与传统的BPF不同,eBPF具有数据类型,如数据阵列和函数指针数组,eBPF字节码可以在其中编制索引。因此,可以使用eBPF字节码在内核中创建上述代码模式。
eBPF的数据阵列效率低于它的函数指针数组,所以攻击将在可能的情况下使用后者。
测试过的两台机器都没有SMAP,PoC依赖于此(但它原则上不应该是一个先决条件)。
此外,至少在经过测试的Intel机器上,在内核之间弹跳修改后的缓存行很慢,显然是因为MESI协议用于缓存一致性[8]。 在一个物理CPU内核上更改eBPF阵列的引用计数器会导致包含引用计数器的高速缓存行被跳转到该CPU内核,从而使所有其他CPU内核上的引用计数器的读取速度变慢,直到已更改的引用计数器已被写回到内存。 由于eBPF阵列的长度和引用计数器存储在同一个高速缓存行中,这也意味着更改一个物理CPU内核上的引用计数器会导致eBPF阵列的长度读取在其他物理CPU内核上较慢(故意为false共享)。
该攻击使用两个eBPF程序。 第一个通过页面对齐的eBPF函数指针数组prog_map在可配置索引处尾部调用。 简单地说,这个程序用于通过猜测从prog_map到用户空间地址的偏移量并在猜测的偏移量处调用throughprog_map来确定prog_map的地址。 为了使分支预测预测偏移量低于prog_map的长度,在两者之间执行对边界索引的尾调用。 为了增加错误猜测窗口,包含prog_map长度的高速缓存行被反弹到另一个核心。 要测试偏移猜测是否成功,可以测试用户空间地址是否已加载到高速缓存中。
因为这种直接暴力猜测地址的方法会很慢,所以我们使用下面的优化:
在用户空间地址user_mapping_area处创建2^15个相邻用户空间存储器映射[9] ,每个由2^4个页面组成,覆盖总面积为2^31 字节。每个映射映射相同的物理页面,并且所有映射都存在于页面表中。

这允许攻击以2^31个字节为单位执行。 对于每一步,在通过prog_map导致越界访问之后,只需要测试user_mapping_area的前2^4个页面中的每一个缓存行以获取缓存内存。 由于L3高速缓存物理索引,因此对映射物理页面的虚拟地址的任何访问都将导致映射同一物理页面的所有其他虚拟地址也被高速缓存。
当这种攻击发现一个hit(缓存的内存位置时),内核地址的高33位是已知的(因为它们可以根据发生hit的地址猜测得出),并且地址的低16位也是已知的 (来自user_mapping_area内找到命中的偏移量)。 user_mapping_area的地址是剩余的中间部分。

剩余的位可以通过平分剩余的地址空间来确定:
将两个物理页面映射到相邻的虚拟地址范围,每个虚拟地址范围为剩余搜索空间一半的大小,然后逐位确定剩余地址。
此时,可以使用第二个eBPF程序实际泄漏数据。 在伪代码中,这个程序看起来如下:
uint64_t bitmask = <runtime-configurable>;
uint64_t bitshift_selector = <runtime-configurable>;
uint64_t prog_array_base_offset = <runtime-configurable>;
uint64_t secret_data_offset = <runtime-configurable>;
// index will be bounds-checked by the runtime,
// but the bounds check will be bypassed speculatively
uint64_t secret_data = bpf_map_read(array=victim_array, index=secret_data_offset);
// select a single bit, move it to a specific position, and add the base offset
uint64_t progmap_index = (((secret_data & bitmask) >> bitshift_selector) << 7) + prog_array_base_offset;
bpf_tail_call(prog_map, progmap_index);
该程序在运行时可配置的偏移量和位掩码处从eBPF数据阵列“victim_map”中读取8字节对齐的64 bit,并对该值进行位移,使得一个bit映射到相距2^7个字节的两个值中的一个 (当用作数组索引时足以不落入相同或相邻的缓存行)。 最后,它添加一个64 bit的偏移量,然后使用结果值作为prog_map的偏移量,以用于尾部调用。
这个程序可以用来通过反复调用eBPF程序来将内存偏移调用到victim_map中来泄漏内存,这个偏移量指定了要泄漏的数据,并且在prog_mapthat中出现了一个超出边界的偏移量,从而导致prog_map + offset指向用户空间的一个内存区域。 误导分支预测和弹跳缓存线的方式与第一个eBPF程序的方式相同,不同之处在于现在保存victim_map长度的缓存线也必须退回到另一个内核。
变体2:分支目标注入
本节介绍了我们PoC的变体2背后的理论,当在使用Intel Haswell Xeon CPU上的virt-manager创建的KVM guest虚拟机中使用root权限运行时,可以读取主机上运行的特定版本的Debian发行版内核内核内存的速度大约为1500字节/秒。
基础
之前的研究(见最后文献部分)已经表明,不同安全上下文中的代码可能影响彼此的分支预测。到目前为止,这只被用来推断代码所在位置的信息(换句话说,是为了制造受害者对攻击者的干扰); 然而,这种攻击变体的基本假设是它也可以用来重定向受害者上下文中的代码执行(换句话说,创建攻击者对受害者的干扰;反之亦然)。

攻击的基本思想是将包含目标地址从内存加载的间接分支的受害代码作为目标,并将包含目标地址的缓存行清除到主内存。 然后,当CPU到达间接分支时,它不会知道跳转的真正目的地,并且它将不能计算真正的目的地,直到它将高速缓存行加载回CPU为止,这通常需要花费几百个周期。 因此,通常有超过100个周期的时间窗口,其中CPU将基于分支预测推测性地执行指令。
Haswell分支预测内部
英特尔处理器实施的分支预测内部部分已经发布; 然而,让这种攻击正常工作需要进一步的实验来确定更多细节。
本节重点介绍从Intel Haswell Xeon CPU实验派生的分支预测内部结构。
Haswell似乎有多种分支预测机制,工作方式非常不同:
- 通用分支预测器,每个源地址只能存储一个目标; 用于各种跳转,如绝对跳转,相对跳转等。
- 专门的间接调用预测器,可以为每个源地址存储多个目标; 用于间接呼叫。
- (根据英特尔的优化手册,还有一个专门的返回预测器,但是我们还没有详细分析,如果这个预测器可以用来可靠地转储出一部分虚拟机进入的调用栈,非常有趣。)
通用预测器
正如先前研究中所记录的,通用分支预测器仅使用源指令最后一个字节地址的低31位进行预测。 例如,如果跳转从0x4141.0004.1000到0x4141.0004.5123存在分支目标缓冲区(BTB)条目,通用预测器也将使用它来预测从0x4242.0004.1000跳转。
当源地址的较高位如此不同时,预测目标的较高位与它一起改变,在这种情况下,预测的目的地址将是0x4242.0004.5123,显然这个预测器不会存储完整的绝对目标地址。
在使用源地址的低31位查找BTB条目之前,使用XOR将它们折叠在一起。 具体而言,以下几位被折叠在一起:
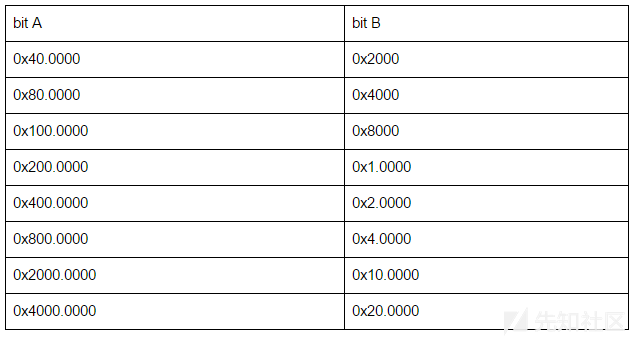
换句话说,如果一个源地址与这个表的一行中的两个数字异或,那么在执行查找时,分支预测器将无法将结果地址与原始源地址区分开来。
例如,分支预测器可以区分源地址0x100.0000和0x180.0000,也可以区分源地址0x100.0000和0x180.8000,但不能区分源地址0x100.0000和0x140.2000 或源地址0x100.0000和0x180.4000。 在下文中,这将被称为别名源地址。
当使用别名源地址时,分支预测器仍然会预测与未混淆源地址相同的目标。 这表明分支预测器存储截断的绝对目标地址,但尚未验证。
根据观察到的不同源地址的最大前向和后向跳转距离,目标地址的低32位可以存储为绝对32位值,并附加一个bit,指定从源跳转到目标是否跨越2^32边界; 如果跳转跨越这样的边界,则源地址的31 bit确定指令指针的高位一半是应该递增还是递减。
间接调用预测器
该机制的BTB查找的输入似乎是:
- 源指令地址的低12位(我们不确定它是第一个还是最后一个字节的地址)或它们的一个子集。
- 分支历史缓冲区状态。
如果间接调用预测器无法解析分支,则由通用预测变量解析。英特尔的优化手册暗示了这种行为:“间接调用和跳转,它们可能被预测为具有单调目标或具有根据最近程序行为而变化的目标。”
分支历史缓冲区(BHB)存储关于最后29个采取分支的信息(基本上是最近控制流程的指纹)并用于更好地预测可能有多个目标的间接调用。
BHB的更新功能的工作原理如下(伪代码; src 是源指令最后一个字节的地址,dst 是目标地址):
void bhb_update(uint58_t *bhb_state, unsigned long src, unsigned long dst) {
*bhb_state <<= 2;
*bhb_state ^= (dst & 0x3f);
*bhb_state ^= (src & 0xc0) >> 6;
*bhb_state ^= (src & 0xc00) >> (10 - 2);
*bhb_state ^= (src & 0xc000) >> (14 - 4);
*bhb_state ^= (src & 0x30) << (6 - 4);
*bhb_state ^= (src & 0x300) << (8 - 8);
*bhb_state ^= (src & 0x3000) >> (12 - 10);
*bhb_state ^= (src & 0x30000) >> (16 - 12);
*bhb_state ^= (src & 0xc0000) >> (18 - 14);
}
当用于BTB访问时,BHB状态的某些位似乎用XOR进一步折叠在一起,但精确的折叠功能尚未被理解。
BHB很有趣,有两个原因。 首先,需要关于其近似行为的知识,以便能够准确地引起间接调用预测器中的冲突。 但它也允许在任何可重复的程序状态下抛出BHB状态,攻击者可以在超级调用后直接执行代码 - 例如攻击管理程序时。 然后可以使用转储的BHB状态来指导管理程序,或者如果攻击者可以访问管理程序二进制文件,则确定管理程序加载地址的低20位(在KVM的情况下:加载低20位 的kvm-intel.ko地址)。
逆向工程分支预测器内部
本小节描述了我们如何逆向Haswell分支预测器的内部结构。有些内容是从内存中写下来的,因为我们没有详细记录我们做的事情。
我们最初尝试使用通用预测器对内核执行BTB注入,使用先前研究中的知识,即通用预测器仅查看源地址的下半部分,并且仅存储部分目标地址。 这种工作 - 然而,注射成功率非常低,低于1%。 (这是我们在方法2的初始PoC中使用的方法,针对在Haswell上运行的修改后的虚拟机监控程序。)
我们决定编写一个用户空间测试用例,以便能够更轻松地测试不同情况下的分支预测器行为。
基于分支预测器状态在超线程之间共享的假设[10],我们编写了一个程序,其中两个实例分别固定到在特定物理内核上运行的两个逻辑处理器中的一个,其中一个实例尝试执行分支注入,而另一个实例测量分支注入成功的频率。 这两个实例都是在禁用ASLR的情况下执行的,并且具有相同地址的相同代码。
注入过程对访问(每个进程)测试变量的函数执行间接调用;测量过程对函数进行间接调用,该函数根据时序测试每个进程的测试变量是否被缓存,然后将其逐出 使用CLFLUSH。 这两个间接呼叫都是通过相同的呼叫站点执行的。 在每次间接调用之前,使用CLFLUSH将存储在内存中的函数指针刷新到主内存以扩大推测时间窗口。
此外,由于英特尔优化手册中提及“最近的程序行为”,因此总是采用的一组条件分支插入到间接调用之前。
在这个测试中,注入成功率高于99%,为我们今后的实验奠定了基础。

然后我们试图找出预测方案的细节。 我们假设预测方案使用某种全局分支历史缓冲区。
为了确定分支信息保持在历史缓冲区中的持续时间,仅在两个程序实例中的一个中采用的条件分支被插入在一系列始终采用的条件跳转的前面,则总是采用的条件跳转(N)的数量是变化的。 结果是,对于N = 25,处理器能够区分分支(误预测率低于1%),但是对于N = 26,它没有这样做(错误预测率超过99%)。
所以分支历史缓冲区必须至少能存储最后的26个分支的信息。
两个程序实例之一的代码随后在内存中移动。 这表明只有源地址和目标地址的低20位对分支历史缓冲区有影响。
在两个程序实例中使用不同类型的分支进行测试表明,静态跳转,条件跳转,调用和返回以同样的方式影响分支历史缓冲区; 未采取有条件的跳跃不会影响它; 源指令的最后一个字节的地址是计数的地址; IRETQ不会影响历史缓冲区状态(这对测试很有用,因为它允许创建历史缓冲区不可见的程序流)。
在间接调用内存之前,移动最后的条件分支多次显示分支历史缓冲区内容可用于区分最后一个条件分支指令的许多不同位置。 这表明历史缓冲区不存储小历史值列表; 相反,它似乎是历史数据混合在一起的更大的缓冲区。
然而,为了对分支预测有用,历史缓冲区在需要一定数量的新分支之后会“忘记”过去的分支。 因此,当新数据混合到历史缓冲区中时,不会导致历史缓冲区中已经存在的位中的信息向下传播 - 并且考虑到向上组合的信息可能不会非常有用。 考虑到分支预测也必须非常快,我们认为,历史缓冲区的更新功能可能左移旧历史缓冲区,然后XOR处于新状态(参见图)。

如果这个假设是正确的,那么历史缓冲区包含大量关于最近分支的信息,但只包含与每个历史缓冲区更新有关的最后一个含有任何数据的分支所移动的信息位数。因此,我们测试了翻转跳转的源地址和目标地址中的不同位,然后是带有静态源和目标的32个始终采用的跳转,允许分支预测消除间接调用的歧义。[11]
中间有32个静态跳转,似乎没有位翻转被影响,所以我们减少了静态跳转的次数,直到可以观察到差异。28次跳转的结果是目标的0x1和0x2 bits以及源的0x40和0x80 bits被影响。但是翻转目标中的0x1和源中的0x40或目标中的0x2和源的0x80不允许消除歧义。
这表明历史缓冲区每次插入的移位是2位,并显示哪些数据存储在历史缓冲区的最低有效位中。然后,我们在跳转位后通过减少固定跳转次数来确定哪些信息存储在剩余位中。