利用Splunk 完成渗透测试前期的情报分析
先知原创作者翻译:原文链接
摘要:在进行攻击性安全数据分析的时候,Splunk在数据的浏览和分析方面,要比传统的Grep更具优势。
为什么选择Splunk而非ELK?
ELK本身就是一个非常优秀的开源项目,如果辅之以Cyb3rward0g的HELK项目的话,在易用性方面将更上一层楼。事实上,在我“归顺”Splunk之前,已经用过ELK一段时间了。使用ELK时,我意识到必须事先创建一个.config文件来指定数据的位置,然后再上传数据。这给我带来了许多不便,因为这意味着,对于每个小数据集,都需要指出相应的头部和数据类型。然而,Splunk只需简单地点击Web UI并上传CSV文件,数据上传的工作就能够轻松搞定。
我知道,很多渗透测试团队都在使用ELK进行日志记录和分析工作,关于这方面的详细介绍,我会在另一篇文章中加以介绍。ELK通常不适用于“快餐式”PoC环境,这种环境一般用于评估需要哪些资源来创建一个进攻性的分析系统,以及这样做会得到什么好处。在这篇文章中,我们将重点介绍如何使用Splunk作为日志分析系统来实现数据的快速可视化和搜索。
安装Splunk
安装过程非常简单,读者可以访问Splunk的网站,然后下载适用于Windows的MSI软件包,或根据自己的操作系统下载相应的软件包。我使用的电脑具有20GB RAM和300GB SSD硬盘的系统,该软件在这台电脑上面的运行效果不错;当然,内存少一点也没关系,因为Splunk看起来不太吃内存。
我们建议读者使用开发人员许可证,该许可证具有6个月的试用期,在这段时间内,读者可以通过Splunk为所需数据编制索引。实际上,索引的过程只是将数据导入数据库并对其进行优化,以便于进行搜索。
数据摄入
是的,这个工作的确很轻松:你甚至可以通过上传方式来直接获取.json.gz文件。不过,由于Project Sonar文件实在太大,所以,我使用命令splunk add oneshot sonar.json.gz将其加载到Splunk中。虽然获取数据通常需要花费一点时间,但一旦完成,搜索就会快如闪电。
如果数据小于500MB的话,我们甚至可以使用Web UI完成数据的上传:

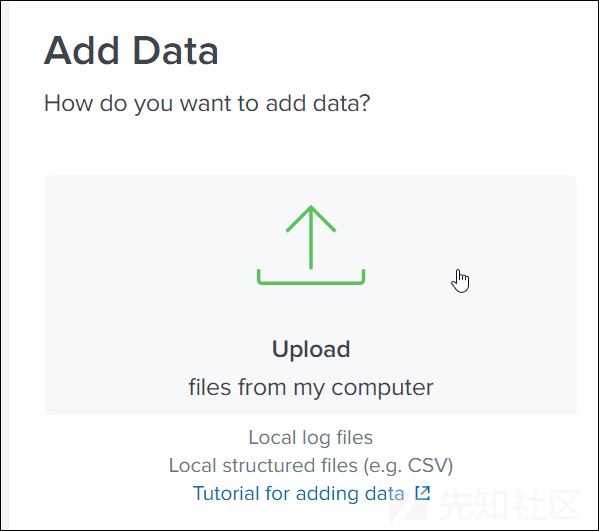
Project Sonar
为了演示如何应用Project Sonar的Forward DNS数据,我决定考察一下Splunk在聚合和理解数据方面的能力。
内容分发网络
查找形如*.cloudfront.net的域名。
常规的grep命令:
:/$ time zcat fdns_a.json.gz | grep '\.cloudfront\.net' | tee -a cloudfront.net.txt
real 10m25.282s
user 9m16.984s
sys 1m23.031s
使用Splunk进行相应的搜索:
value="*.cloudfront.net"
47.63 seconds
使用grep命令完成上述搜索所花费的时间,是使用Splunk所需时间的13.13倍。
域搜索
获取特定域的所有子域:
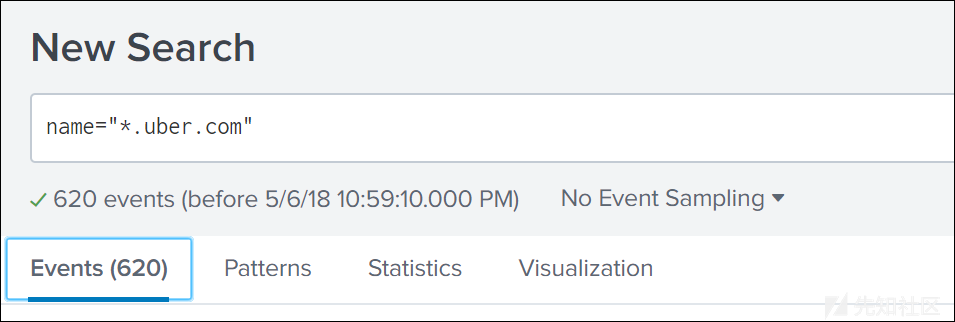
这个过程几乎是瞬间完成的。如果使用常规的grep命令的话,这个过程通常需要10分钟左右。然而更加有趣的是,我们还可以利用Splunk的分析功能执行相关操作来查找诸如“多少个域共享同一个主机?”等信息,例如:

这将得到如下所示结果:

从上图可以看出,右侧的所有主机名都指向了一台特定的服务器。
除此之外,我们也可以映射服务器的物理位置,例如:
name="*.uber.com" | stats values(name) by value | iplocation value | geostats count by City
这将得到如下所示结果:

当然,有时这样做可能没有多大用处,但的确却可以立刻获悉目标服务器的地理位置。
如果需要对攻击目标组织在特定国家/地区内的服务器进行精确打击的话,则可以使用Splunk来进行相应的过滤:
name="*.uber.com" | stats values(name) by value | iplocation value | search Country="United States"

如果有必要的话,甚至可以将范围缩小至某个具体的国家。
获取所有子域
此外,我们也可以执行以下搜索来获取所有子域。当然,解析14亿个结果可能需要花费太多时间,所以,这里仅仅以一个域为例进行说明:
index=main [search name="*.uber.com"]
| table name
| eval url=$name$ | lookup ut_parse_extended_lookup url

或搜索特定的子域:
index=main [search name="*.uber.com"]
| table name
| eval url=$name$ | lookup ut_parse_extended_lookup url
| table ut_subdomain
| dedup ut_subdomain
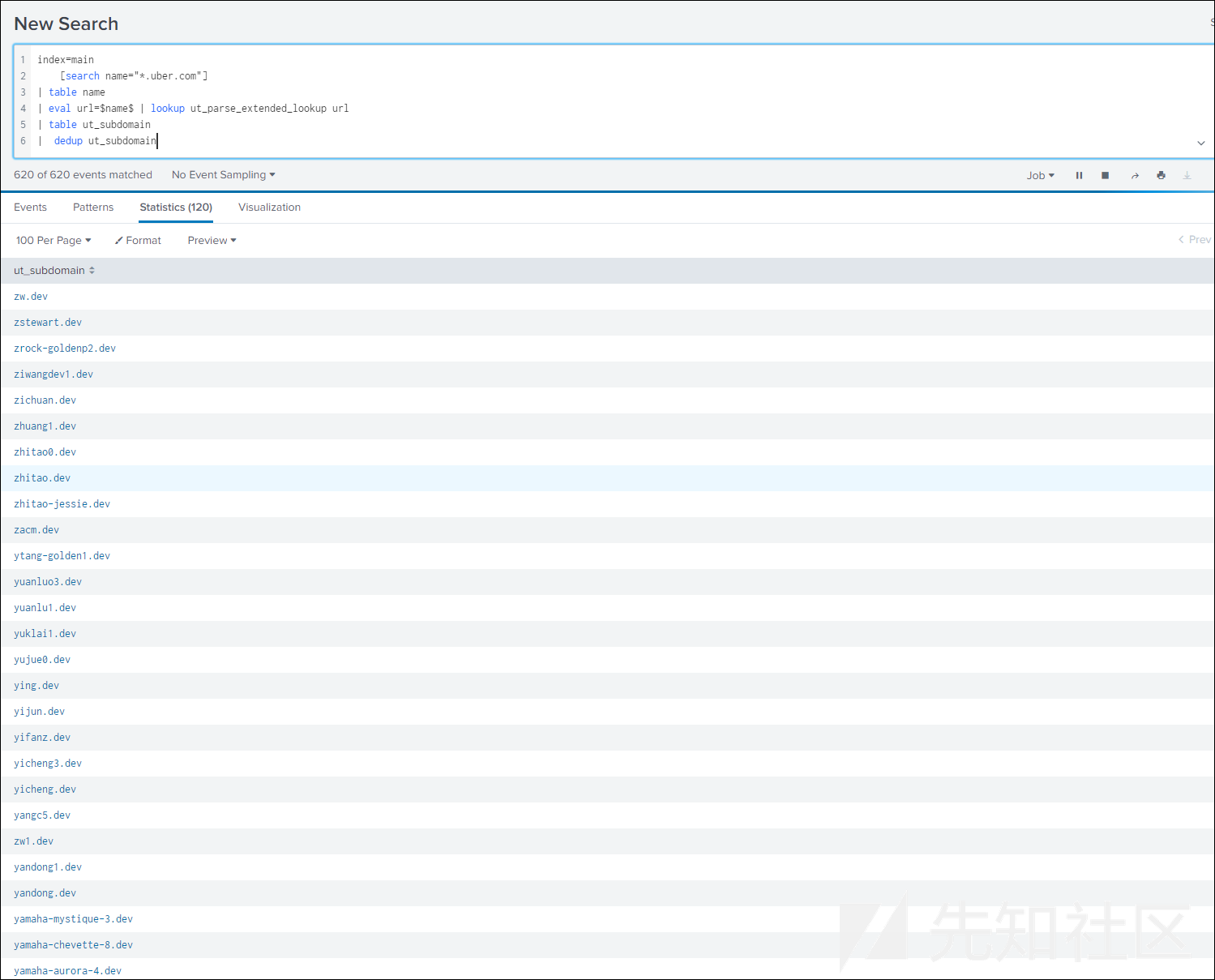
当需要从目标组织下属域名中搜索相同的子域以寻找更多子域的时候,这种方法会很有帮助。
DomLink domains-> Give me all subdomains
如果结合我的工具DomLink一起使用的话,我们就可以获取相应的搜索结果,并让Splunk为我们提供隶属于目标组织的所有子域的完整清单。两者结合之后,这会变得轻而易举。
首先运行该工具,然后使用命令行标志将结果输出到指定的文本文件中:

现在,我们已经获取了一个域列表,位于我们的输出文件中,这样,就可以读取这些域名,并创建一个以name开头的新文件,然后使用简单的正则表达式,通过*.替换域名的第一个字段:
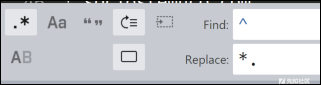
经过上面的处理之后,我们的文件内容将会变成下面这样:

将这个文件保存到C:\Program Files\Splunk\etc\system\lookups目录中,并将其命名为Book1.csv。然后,执行以下搜索操作:
index=main [inputlookup Book1.csv] | table name
结果如下所示:
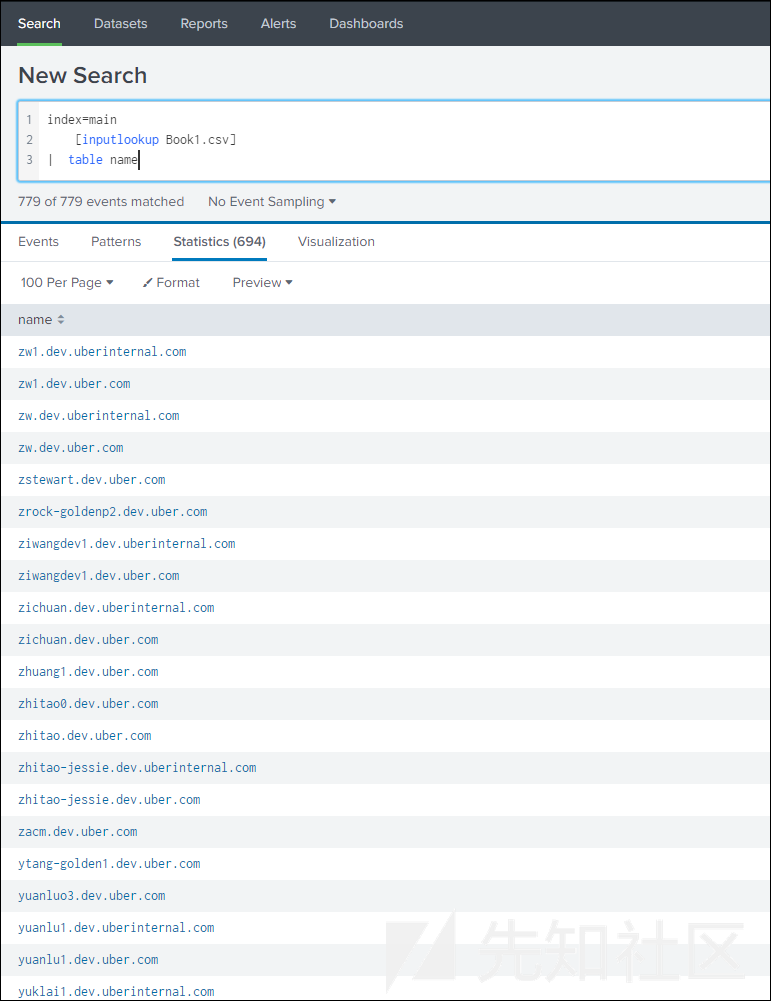
然后,我们就可以导出这些结果,继而将其导入其他工具中了。
密码转储
这里使用的是LeakBase BreachCompilation的数据,同时,为了将数据导入Splunk,我们还参考这篇文章,利用Elk对Outflank的密码转储数据的格式进行了相应的处理。通过运行其中提供的脚本,就可以方便地将转储数据转换为以空格符分隔的文件格式,这实在是太方便了:
我对该脚本稍作修改,使其将相应结果输出到磁盘,而不是直接推送到ELK/Splunk。
这一点对于我们来说非常重要。这是因为,Splunk无法接收空格符分隔的文件,因此,我们必须修改Outflank提供的脚本,将相应的格式转换为可导入的CSV格式。
为此,只需执行splunk add oneshot input.csv -index passwords -sourcetype csv -hostname passwords -auth "admin:changeme",然后就ok了!
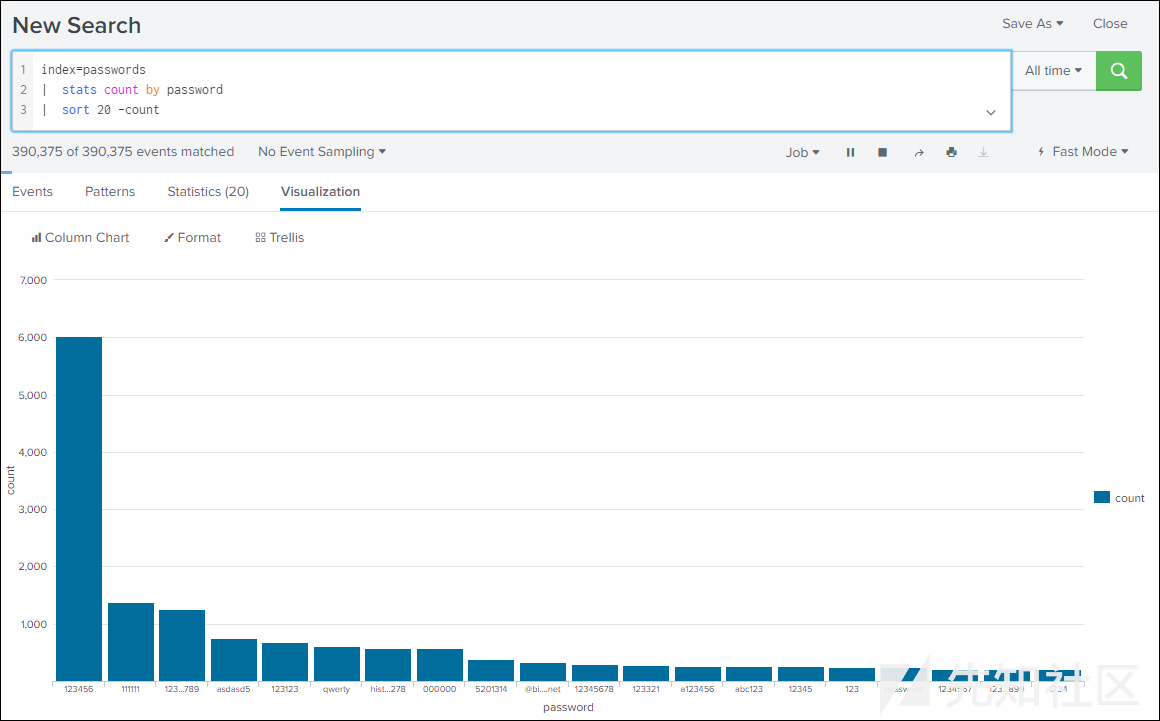
好了,让我们看看最常用的密码到底是什么!
index=passwords
| stats count by password
| sort 100 -count

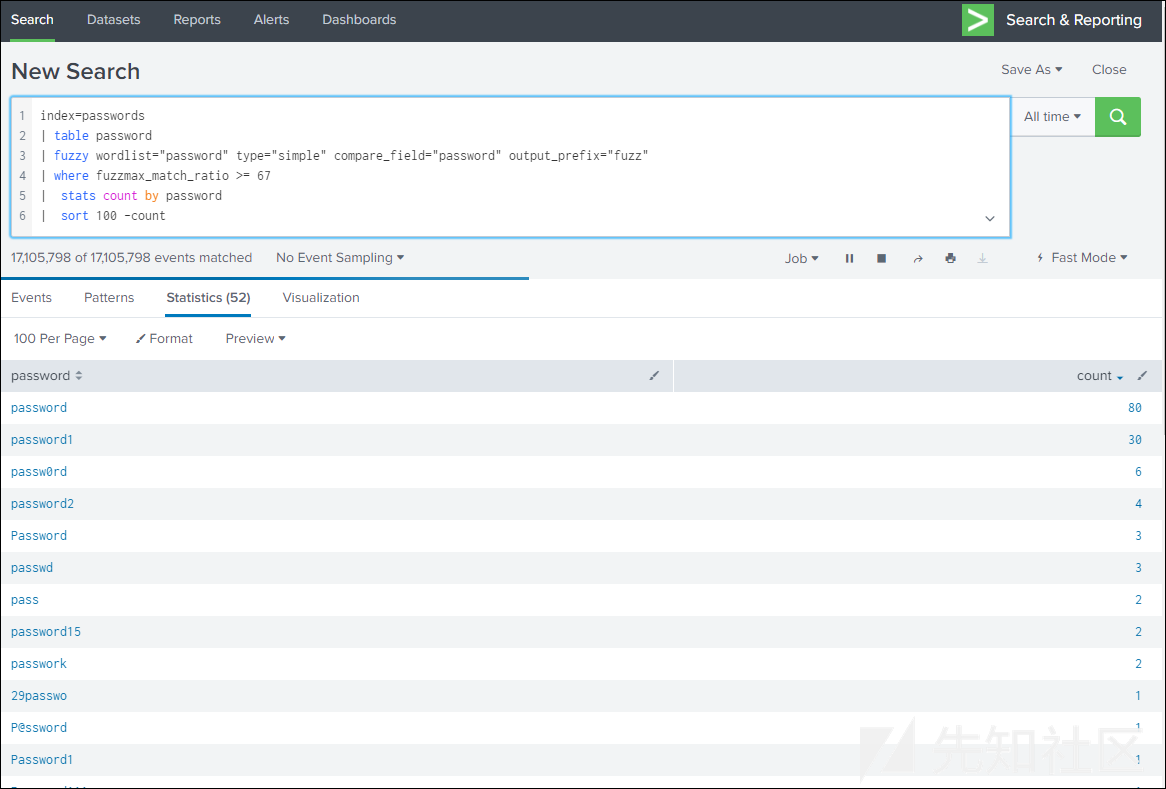
如果对基础词汇感兴趣的话,可以使用模糊匹配技术,例如:
index=passwords
| table password
| fuzzy wordlist="password" type="simple" compare_field="password" output_prefix="fuzz"
| where fuzzmax_match_ratio >= 67
| stats count by password
| sort 100 -count
@facebook.com电子邮件最常用的密码:
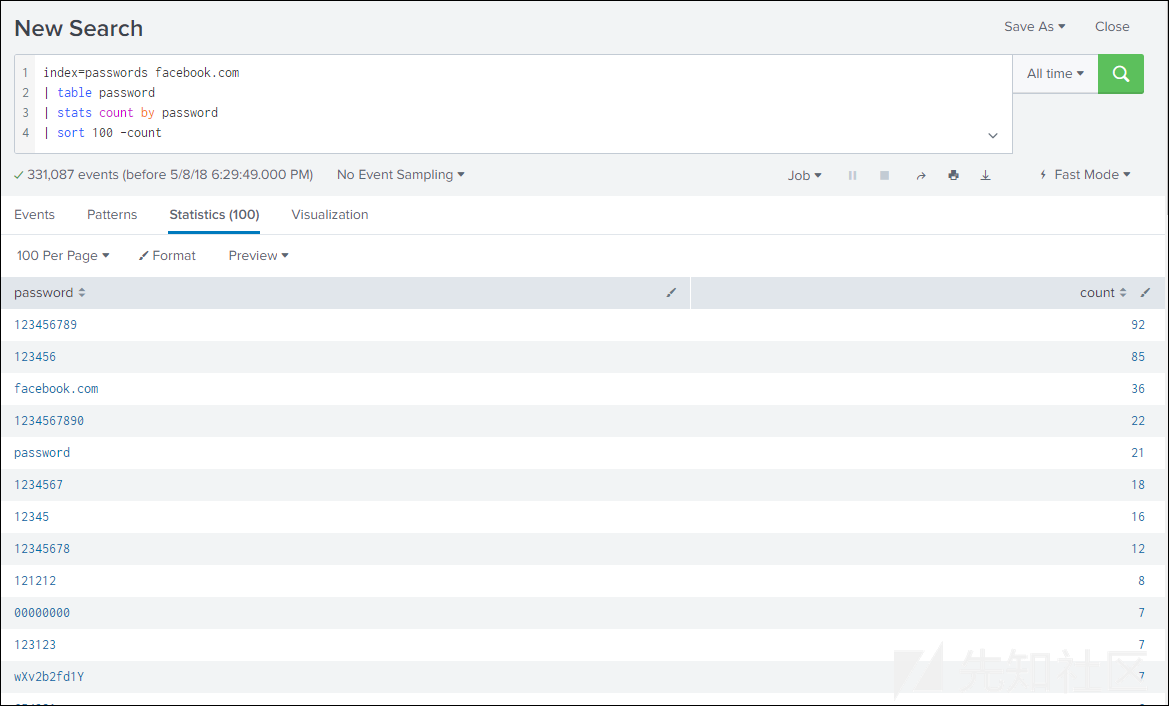
下面,我们以图形化的形式来展示数据:

更有趣的是,我们可以通过员工OSINT获取的电子邮件轻松实现密码的交叉核对。当然,我们也可以通过grep命令来完成这项任务。
DomLink domains -> Give me all passwords for all domains
在运行DomLink(关于DomLink,上文已有介绍)之后,我们可以继续使用它来完成相应的查找工作。不过,这里使用的正则表达式是@domain.com,而非.domain.com,此外,还需要按照下面的方法来设置电子邮件的标题字段:

然后执行查询操作:
index=passwords [inputlookup uber.csv]
| table email, password
这样,我们就会得到一份表格形式的输出结果,如果需要的话,可以将其导出为CSV格式:

这简直太棒了,至少我是这么认为的。
员工OSINT
当我们在外部基础架构上执行有针对性的钓鱼攻击或"拖库"时,通常首先要搞到相应的用户名清单,所以,这时了解组织员工的概要信息就非常重要了。不过,LinkedInt好像就是专门为此而生的。此外,我们还需要一个靠谱的工具,以帮助我们获取目标组织的员工名单。这对于少数几家公司的一两个特定数据集来说,优势并不是特别明显。然而,如果您要为Alexa上前100万个网站和财富500强企业自动收集员工数据的话,这种方法的优势就立马显现出来了。当然,这些工作可以实现全自动化。
这里,我们将演示如何从一个尚未公开的数据集(可能会在HITB GSEC上公开)中导入数据,以分析员工的基本信息。这里介绍的方法也同样适用于LinkedInt。实际上,我们只需将数据作为CSV文件导入即可,具体如前所述。

我们可以使用Splunk搜索符合特定姓氏、名字或地理位置要求的员工:
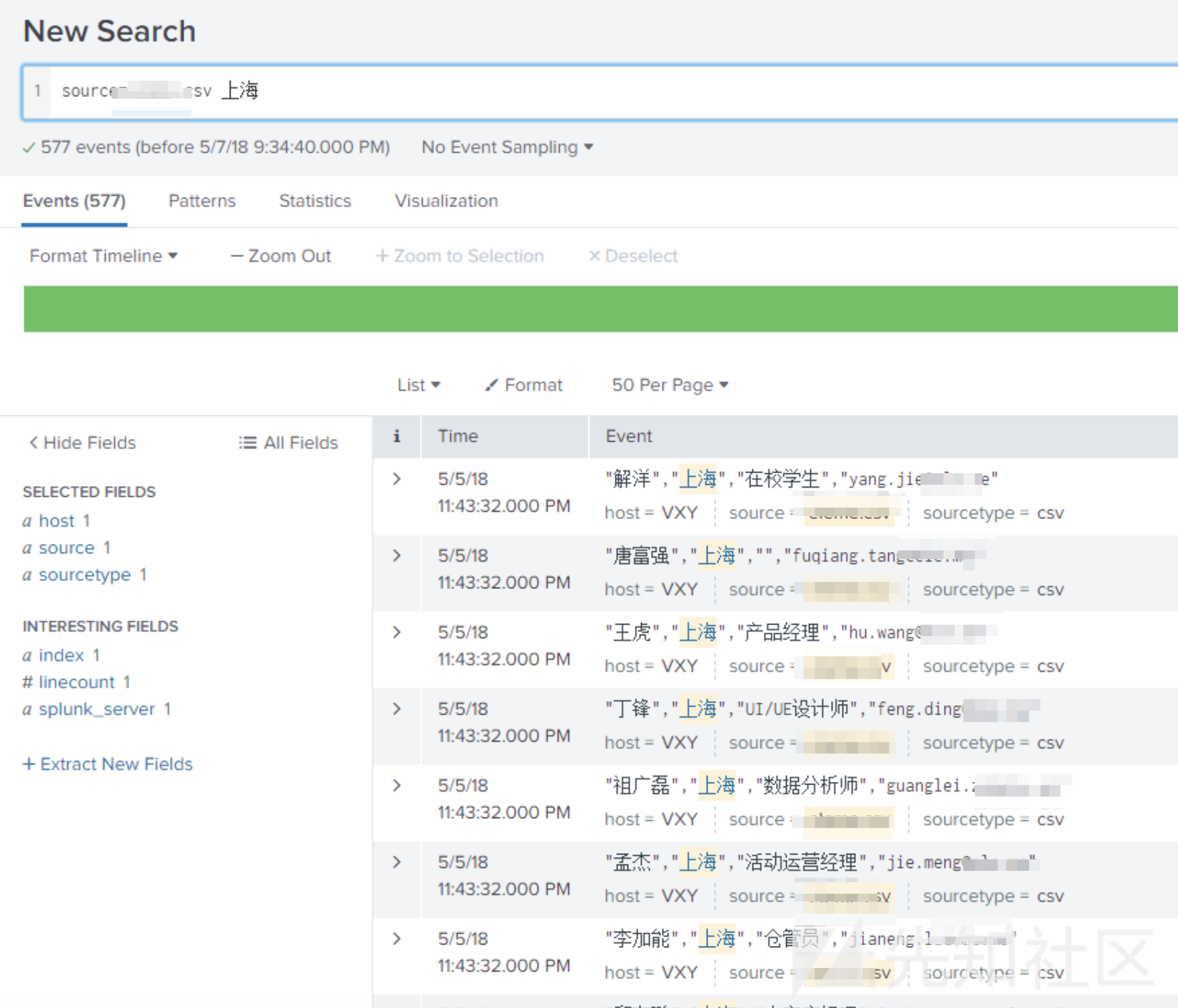
我们甚至可以考察相关的工作岗位上的员工数量等信息:

从这里可以看出,大部分员工都是送货人员,因为这家公司相当于中国的Deliveroo。
实际上,我们还可以进一步将其绘制成角色分布图:


虽然这里只有5000名左右的员工数据,但是已经足以了解目标组织中人员的大致分布情况了,至少在进行下一步的社工之前,可以帮助我们回答下列问题:
- 是否需要雇佣社工人员?
- 我应该拥有什么头衔?
- 我的角色是什么?
- 我在哪里?(是的,如果X角色位于Y地址的概率很高的话,就选Y地址)
- 担任该角色的员工有多少?
对于某些公司来说,如果有很大一部分(近10% )员工都是送货员的话,那么他们很可能无法接触到普通员工,也很难获得普通员工的信任。所以,根据上述问题做出相应的选择是非常重要的一件事情。
最后,我想知道自己的OSINT和员工的实际分布的实际差距有多大,换句话说到底有多么准确?

综合运用员工OSINT与密码转储
如果将通过员工OSINT获取的电子邮件与密码转储结合起来,那么查找密码就会变得更加轻松:
index=passwords [search index=eleme
| eval email=$Email$
| table email]
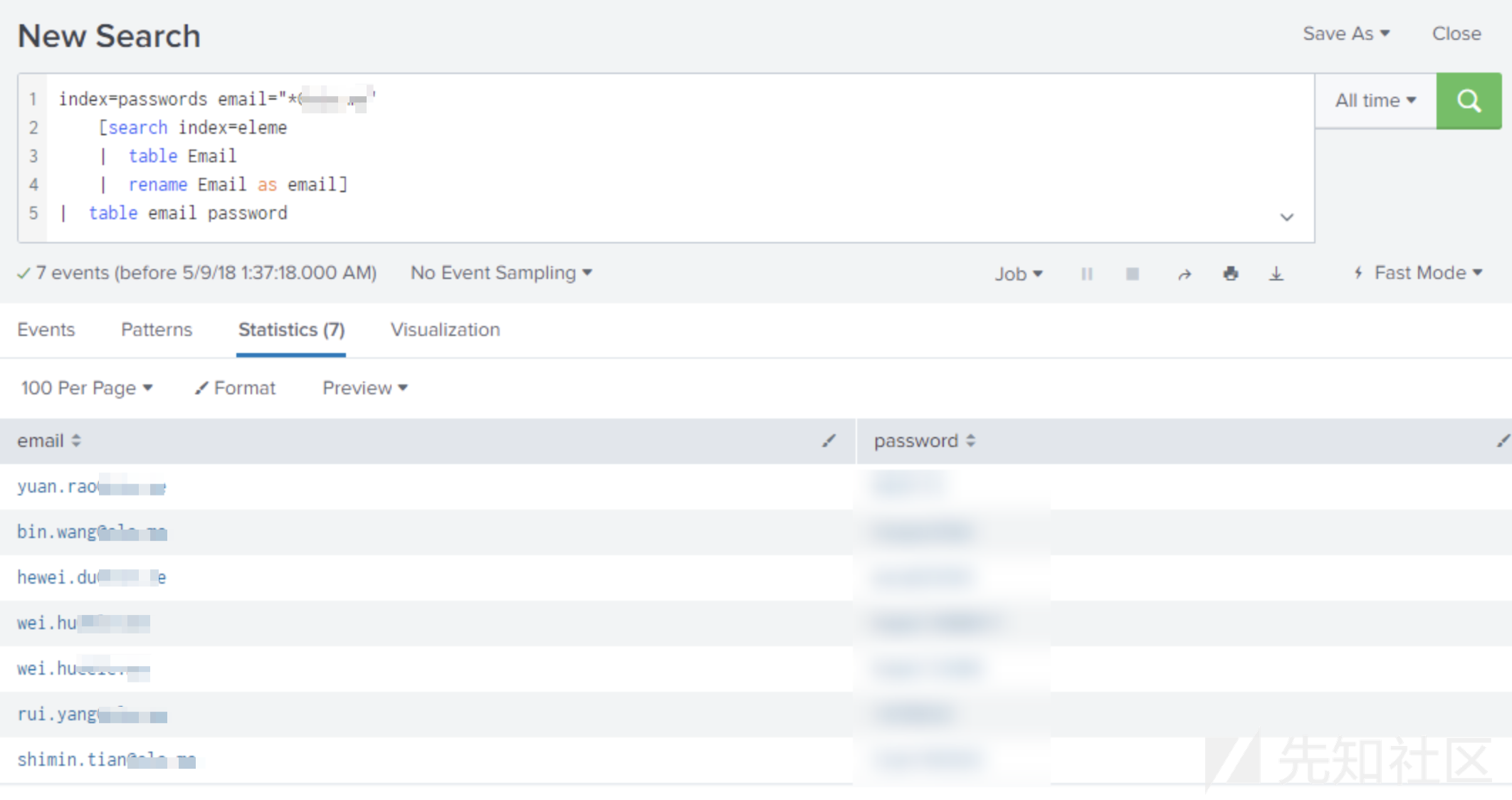
真不错,至少我是这么认为的。当然,您也可以使用grep来实现这一点,但上面这种方法不仅在导入新CSV文件的时候要更加简便,并且几乎可以立即找到匹配的密码列表(可以将其导出为CSV或表格)。
Nmap扫描

将.gnmap文件上传到Splunk,把时间戳设置为none。
然后,可以运行以下示例查询来格式化数据,并通过Splunk以高效的方式完成相应的搜索:
1
source="uber.gnmap" host="uber" sourcetype="Uber" Host Ports | rex field=_raw max_match=50 "Host:\s(?<dest_ip>\S+)"
| rex field=_raw max_match=50 "[Ports:|,]\s?(?<port>\d+)\/+(?<status>\w+)\/+(?<proto>\w+)\/+(?<desc>\w+|\/)"
| rex field=_raw "OS:\s(?<os>\w+)"
| eval os = if(isnull(os),"unknown",os)
| eval mv=mvzip(port, status)
| eval mv=mvzip(mv, proto)
| eval mv=mvzip(mv, desc)
| mvexpand mv
| makemv mv delim=","
| eval ports=mvindex(mv, 0)
| eval status=mvindex(mv, 1)
| eval proto=mvindex(mv, 2)
| eval desc=if(mvindex(mv, 3) == "/","null",mvindex(mv,3))
| table dest_ip ports status proto desc os
| sort dest_ip

如果你有大量的扫描需要进行解析的话,这种方式是非常有效的。例如,您可以扩展该查询来绘制所有开放了TCP的443端口的服务器的地理位置:
source="uber.gnmap" host="uber" sourcetype="Uber" Host Ports
| rex field=_raw max_match=50 "Host:\s(?<dest_ip>\S+)"
| rex field=_raw max_match=50 "[Ports:|,]\s?(?<port>\d+)\/+(?<status>\w+)\/+(?<proto>\w+)\/+(?<desc>\w+|\/)"
| rex field=_raw "OS:\s(?<os>\w+)"
| eval os = if(isnull(os),"unknown",os)
| eval mv=mvzip(port, status)
| eval mv=mvzip(mv, proto)
| eval mv=mvzip(mv, desc)
| mvexpand mv
| makemv mv delim=","
| eval ports=mvindex(mv, 0)
| eval status=mvindex(mv, 1)
| eval proto=mvindex(mv, 2)
| eval desc=if(mvindex(mv, 3) == "/","null",mvindex(mv,3))
| table dest_ip ports status proto desc os
| sort dest_ip
| table dest_ip,ports
| search ports=443
| iplocation dest_ip
| geostats count by City

[1]参考文章:How to parse Nmap in Splunk
小结
数据的处理和分析在渗透测试过程中扮演了一种重要的角色。俗话说,工欲善其事,必先利其器,就像密码破解需要借助于32个GPU的破解平台一样,Splunk也有助于令渗透测试过程更加简化和高效。
许多人认为,GZIP的类比有些流于表面,那好,下面我们就给出agn0r对Splunk基于Lexicon结构的运行机制的深刻洞见:
