Pwn2Own 2018 Safari 漏洞利用开发记录系列 Part 2:Apple Safari浏览器漏洞挖掘之旅(上篇)
原文:https://blog.ret2.io/2018/06/13/pwn2own-2018-vulnerability-discovery/
漏洞挖掘是漏洞利用开发生命周期的第一个阶段。并且,这一阶段的持续时间是“因洞而异”的,这是因为,对于不同目标的来说,搜索空间、代码质量和评估过程可能会存在巨大的差异。此外,到底优先采用手动方式还是自动方式进行漏洞挖掘,对于挖掘时间也存在显著影响,并且通常难以有效权衡。
作为我们的Pwn2Own 2018博客系列的第二部分,本文将为读者详细介绍如何利用我们研究复杂软件对象(如Safari浏览器)的方法,来缩小审计范围,选择漏洞挖掘策略,并开发相应的浏览器fuzzer。
由我们基于语法的JS fuzzer生成的JavaScript测试用例代码片段
关于这个博客系列以及整个Pwn2Own 2018漏洞利用链的概述,请参阅第一篇文章。
初步侦察
面对大型软件数百万行的代码,要想从中挖掘安全漏洞的话,可能会有一种闷头一击的感觉。为了克服这一点,最重要的事情就是,要设法掌握目标软件的基础知识,同时,这也是零日漏洞利用过程中最不光鲜照人部分:初步侦查。
目标软件的作用是什么?用户如何与软件交互?该项目是如何构建的?它的主要组成部分是哪些?它过去的漏洞是什么样的?
总之,这一步就是汇总与目标相关的文档或安全文献,并花时间来深入研究它们。为此,需要建立链接列表并做好笔记,但是有一点要记住:不要企图掌握一切知识。
现实世界的漏洞利用过程往往是从对现有资源的详尽研究开始起步的
如果攻击目标没有公开的研究文献或文档,那么考察与目标软件(例如,Google的v8,Mozilla的SpiderMonkey,Microsoft的Chakra%7B:target=%22_blank%22%7D "Chakra")等)或设备(如果攻击目标为硬件的话)相关的资料通常也会很有帮助。
如果您直接跳过该步骤的话,往往得不偿失:获取同样的知识,如果使用其他方法的话,所需的时间通常是阅读相关文档所需时间的10倍。
WebKit:锁定一个目标
在处理中小型目标时,直接锁定所有目标通常是可行的......然而,当针对规模和复杂性剧增的代码库时,这样做的难度会呈指数级增加。
利用通过研究现有文献所获得的知识,能够迅速缩小待审计代码的范围,直到将攻击面的数量降到可以接受的范围为止——这一点非常重要。
利用上面的策略,我们将WebKit的预期审计范围从300多万行C/C++代码减少至70k行以内。通过缩小包围圈,我们就能非常有针对性地对代码库中的子集进行审计,进而有效提高审计的深度和质量。
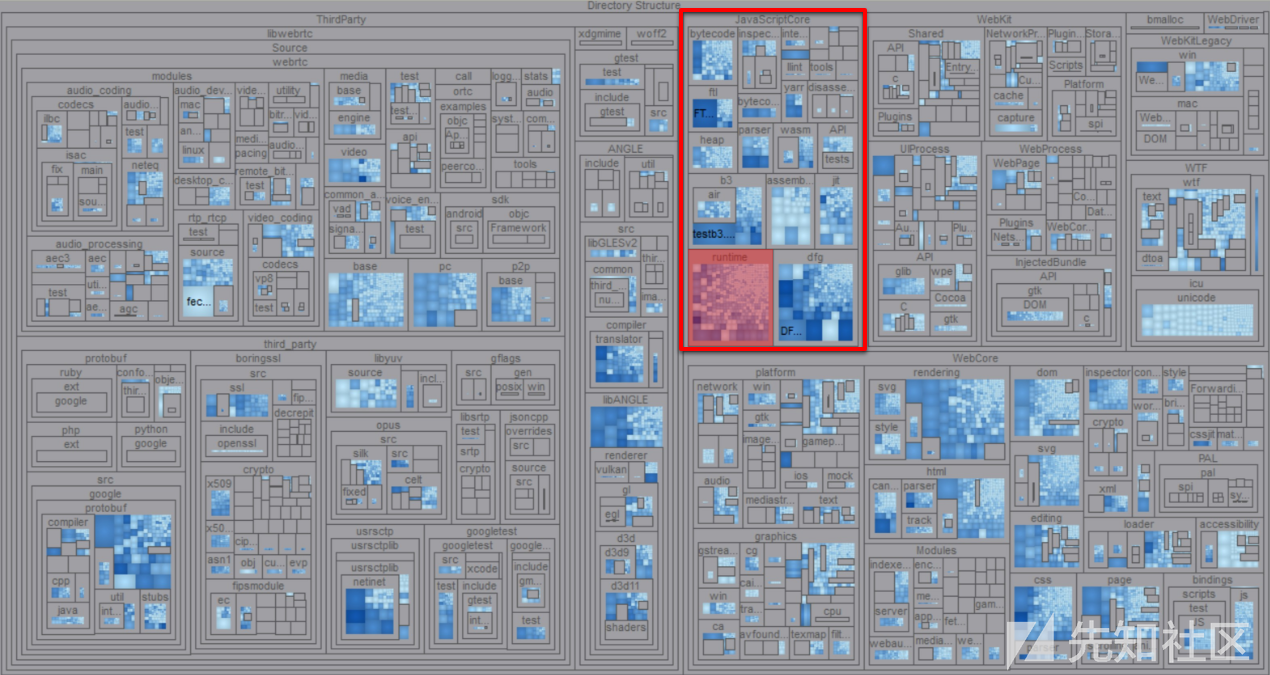
WebKit源代码目录的树形图
为了在Pwn2Own 2018大赛中取胜,我们将目标定为JavaScriptCore,即Safari浏览器的JS引擎。当然,这个决定也不是临时起意,而是建立在深入考察现有研究文献的基础上的,事实证明,这是一个非常正确的决策。虽然JS引擎中的漏洞已经越来越少,但这些漏洞的高度可利用性却是不容忽视的。
选定JavaScriptCore后,尽管考察范围已经大为缩小,但即使如此,光是JSC本身的代码,也有35万行左右的C/C++代码,这仍是一个巨大的挑战。为了熟悉代码库,我们需要将考察范围进一步缩小,直到缩小到一个“平易近人”的程度为止。

JavaScriptCore源代码目录的树形图。JavaScript运行时以红色突出显示
构成JS运行时的C/C++代码(上面用红色突出显示)几乎可以直接映射为编写JavaScript时使用的高级对象。实际上,运行时是所有JS引擎的表层。
这个高级层中的文件大部分位于/Source/JavaScriptCore/runtime中:

JavaScriptCore运行时目录,在前两张图片中都显示为红色
由于这里只关注JSC的runtime文件夹,所以,我们的考察范围会降低到70k行左右的代码。当然,这个数字仍然相当可观,但是,通过缩小考察范围,使得我们的任务变得更加容易实现了。最后,到底降低到什么程度才算是“合理的”,将取决于您计划动用的资源(时间、资金和人员)和漏洞挖掘策略。
选择目标后,接下来要做的事情就是选择一种漏洞挖掘方法。
代码审计策略
有效的软件(安全)审计可以采用两种不同的方法。当然,至于选择哪一种方法,虽然会受到个人的偏好的影响,但最主要的决定因素,是由潜在的优先级和动机决定的。
Fuzzing通常是许多安全爱好者的首选策略,因为它通常成本低且富有成效。我们知道,Fuzzer可以在很短的时间内覆盖大量的攻击面,但代价是我们作为人类可以提供的洞见和“创造力”却派不上用场。使用fuzzer快速查找漏洞虽然简单有效,但是凡事有利即有弊,其他人也可以使用这种方法,所以很容易出现“撞车”现象。换句话说,这些漏洞通常具有较短的保质期。
源代码审查,通常既繁琐又令人沮丧,对于经过严格审查的源代码来说,尤其如此。但是对于那些坚持不懈的人来说,往往能够发现根源性的漏洞,这些漏洞对于大多数模糊测试者甚至其他类型的审计人员来说,都是遥不可及的。因为,这些安全漏洞的特点是有效期往往更持久,因此,通常是漏洞收购商的高价收购对象。
然而,对于参赛而言,侧重于模糊测试方法是比较合理的。我们为JSC设定的搜索层是一个非常有挑战性的目标,因为多年来它一直是众矢之的。此外,该层所处的位置也很浅,并且是WebKit中经过了最严格的检测的代码,因为它们经过了模糊测试者或源代码审查者的严格考验。不过,在当今的环境下面,在这个范围内发现的漏洞,不太可能长期有效。
在下文中,我们将为读者详细介绍构建JS fuzzer的方法和注意事项。
基于语法的Fuzzing测试
经典fuzzing测试技术(例如比特位翻转、简单的输入变异和测试用例拼接)通常无法用于高度结构化的上下文输入,如解释语言(JavaScript)。为了对这种类型的输入进行fuzzing测试,最好的方法是使用语法来合成一些不仅语法正确并且语义合理的测试用例。
实际上,语法通常可以通过分析师以手动方式将其表示为一组用于构建数据的“规则”。例如,下面让我们编写一些简单的语法来生成数学表达式:
digit :=
1
2
3
...
operator :=
+
-
*
...
利用这些“语言”原语,我们就能够打造出更高级的新型语法结构(如数学表达式):
expr :=
+digit+ +operator+ +digit+
为了让读者对这个概念有一个感性的认识,我们让测试用例生成器使用我们编写的语法规则,来输出任意数量的随机表达式:
1 + 1
1 * 2
3 - 2
2 + 3
...
实际上,我们可以将该想法推广到更复杂的任务上面,例如生成合乎语法的有效JavaScript代码。当然,为此需要阅读相关规范并将它们转换为相应的语法定义。
结束语
在本文中,我们为读者详细介绍了在挖掘像浏览器这样高度复杂的攻击对象的过程中,如何通过初步侦查确定合理的攻击目标,选择合适的漏洞挖掘方法,最后,还为读者介绍了我们使用的基于语法的Fuzzing测试方法。在本文的下篇中,我们将继续为读者奉献更多的精彩内容。