利用循环神经网络检测Web攻击
原文:https://aivillage.org/posts/detecting-web-attacks-rnn/
几十年来,攻击检测一直都是信息安全不可分割的组成部分。根据目前掌握的信息来看,世界上第一个IDS实现可以追溯到上世纪80年代早期。以下内容摘自维基百科:
Dorothy E. Denning在Peter G. Neumann的协助下于1986年发布了IDS模型,从而为当今的攻击检测系统奠定了基础。[20] 她的模型使用统计数据进行异常检测,并在SRI International公司创建了IDS的前身——当时命名为入侵检测专家系统(IDES),该系统运行在Sun工作站上,可以同时对用户和网络级数据进行检测。
下面,让我们来看一下统计方法如今在异常检测领域的表现。
几十年后的今天,已经围绕攻击检测形成了一个完整的产业。同时,各种各样的相关产品也如雨后春笋般涌现出来,如IDS、IPS、WAF、防火墙等,其中大部分产品都是基于规则的攻击检测。由此看来,在生产环境中使用某种统计学方面的异常检测算法进行攻击检测的想法,似乎已经不像过去那样大行其道了,但是,果真如此吗?
检测针对Web应用程序的网络攻击
第一批专门用于检测与应用程序有关的网络攻击的防火墙,是在上世纪90年代初开始面市的。自那时以来,攻击技术和保护机制都发生了翻天覆地的变化,因为攻击者每天都在不停的进步,安全厂商只能被迫跟进。
现在,大部分WAF都使用类似下面介绍的方式来检测攻击:将基于规则的引擎嵌入到某种类型的反向代理中。这方面最著名的例子就是mod_security,它是一个用于Apache Web服务器的WAF模块,创建于2002年。但是,基于规则的检测方法有一些缺点,例如,它们无法检测新型的攻击,即0day攻击,但是,同样面对这些新型攻击,人类专家却很容易将其检测出来。如果仔细思考一下,就会觉得这一点也不奇怪——人类的大脑的工作方式与一组正则表达式的工作方式是截然不同的。
从WAF的角度来看,攻击类型可以分为基于时间序列和基于单个HTTP请求/响应的两种类型。我们的研究重点,是检测后面那类攻击,包括:SQL注入、跨站脚本攻击、XML外部实体注入、路径遍历、OS命令、对象注入,等等。
但是,首先让我们问自己下面的问题:
当人们看到一个请求时,他们会怎么做?
下面给出的是针对某个应用程序的常规HTTP请求:
POST /vulnbank/online/api.php HTTP/1.1
Host: 10.0.212.25
Connection: keep-alive
Content-Length: 59
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://10.0.212.25
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://10.0.212.25/vulnbank/online/login.php
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Cookie: PHPSESSID=4dorluj4ccherum6m9c1i0j917
type=user&action=login&username=ytrtry&password=tyhgfhgfhg
即使您的任务是查找发送给该应用程序的恶意请求,您很可能也会先观察一些正常的请求。在观察一些发给应用程序端点的请求之后,就会对正常请求的结构和功能有一个大致的了解。
现在,我们来看看下面的请求:
POST /vulnbank/online/api.php HTTP/1.1
Host: 10.0.212.25
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://10.0.212.25/vulnbank/online/login.php
Content-Type: application/x-www-form-urlencoded
X-Requested-With: XMLHttpRequest
Content-Length: 76
Cookie: PHPSESSID=mlacs0uiou344i3fa53s7raut6
Connection: keep-alive
type=user&action=login&username=none'+union+select+1,2,login,password,5,6,7,NULL,NULL,10,11,12,13,14,15,16,17+from+users+limit+1+--1
它会马上引起您的注意,因为某些东西是有问题的。当然,我们需要一些时间来了解具体情况,并且在找出请求中存在异常的部分后,就会进一步思考它属于什么类型的攻击。从本质上讲,我们的目标就是让我们的攻击检测AI以某种类似于人类推理的方式来工作。
不过,这里需要面对一个非常棘手的问题:对于某些流量来说,虽然乍一看是恶意的,对于特定的网站来说,实际上可能是完全正常的。
例如,让我们来看看下面的请求:

这是异常的请求吗? 实际上,该请求是由Jira漏洞跟踪器发出的,并且对于该服务来说这是一个标准的请求,这意味着该请求是良性的。
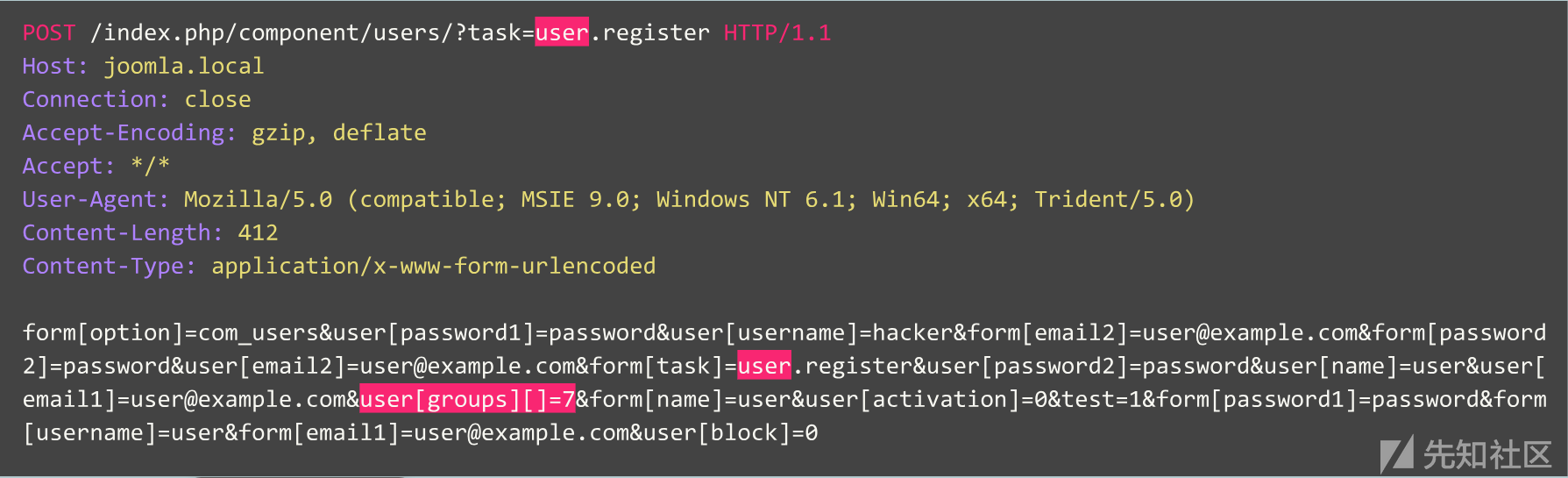
现在,让我们来看看另一个例子:

初看起来,该请求好像是基于Joomla CMS的网站上典型的用户注册请求。但是,这里请求的操作是“user.register”,而不是正常的“registration.register”。实际上,前一个选项已弃用,因为它含有一个安全漏洞,允许任何人将自己注册为管理员。
实际上,该漏洞就是著名的“3.6.4以下版本的Joomla系统的帐户创建/权限提升漏洞”(CVE-2016-8869,CVE-2016-8870)。
我们是如何入坑的
首先,我们研读了关于该主题的相关研究。在过去的几十年中,在创建各种不同的统计或机器学习算法来检测攻击方面,人们已经进行了大量的尝试。最常见的一种方法,就是将其作为分类任务进行处理,其中的类别可以是“良性请求、SQL注入、XSS、CSRF,等等”。对于给定数据集来说,虽然分类器能够获得一定的准确度,但这种方法仍然面临一些非常重要的问题:
- 类别集合的选择。如果在训练期间模型只有三个类别,例如“良性、SQLi、XSS”,然而,如果在生产环境中遇到“CSRF”类型的攻击,甚至是全新的攻击技术的话,该如何是好?
- 类别的含义。假设需要保护十位客户,并且每个客户都运行完全不同的Web应用程序。对于大多数人来说,您根本不知道针对他们的应用程序的某种“SQL注入”攻击到底是什么样子的。这就意味着,您必须设法以人工方式来构建训练数据集,这是一个非常可怕的决定,因为这样的话,我们用以训练模型的数据的分布情况,将会与真实数据的分别情况截然不同。
- 模型结果的可解释性。好吧,它给出了“SQL注入”标签,那接下来呢?我们以及我们的客户(他们往往是第一个看到该警报的人,但他们通常不是网络攻击专家)还必须猜测模型认为哪些部分是恶意的。
请牢记一点,我们的目标是设法进行分类。
由于HTTP协议是基于文本的,所以显而易见,我们必须了解一下现代文本分类器。这方面,众所周知的一个例子就是IMDB电影评论数据集的情绪分析。一些解决方案就是使用RNN网络对这些评论数据进行分类。于是,我们也决定使用类似的RNN分类模型,但这里会略有不同。例如,用于自然语言分类的RNN网络使用了词嵌入技术,但是,我们还不清楚HTTP等非自然语言中有哪些“词”。所以,我们决定在模型中使用字符嵌入方法。
遗憾的是,现成的嵌入技术并不适用于我们要解决问题,因此,我们采用了一种简单的映射方法:把字符映射为具有内部标记(如“<go>”和“<eos>”)的数字代码。</eos></go>
在完成模型的开发和测试之后,之前预估的所有问题都变得清晰起来,但至少我们的团队已经走出了无用推测的境地,并为一些问题找到了答案。
我们是如何行进的
此后,我们决定采取一些措施,让我们模型的结果更具可解释性。在探索过程中,我们无意中遇到了所谓的“注意力”机制,于是将其整合到自己的模型中,并取得了令人满意的成果:将这些技术综合在一起后,终于获得了一些人类可解释的结果。现在,我们的模型不仅能够输出标签,同时还能给出输入的每个字符的注意力系数。
如果能够将模型的结果(例如通过Web界面)可视化的话,我们就可以在发现“SQL注入”攻击的确切位置上标记出相应的颜色。到目前为止,虽然我们已经取得了一定的成果,但仍有许多问题摆在面前。
很明显,我们必须在注意机制的方向上继续深耕,并逐渐摆脱分类模型。在阅读了大量序列模型相关研究(例如,“Attention is All You Need”、“word2vec”、编码-解码架构)并利用我们的数据进行实验之后,终于鼓捣出了一个在某种程度上能够像人类专家一样工作的异常检测模型。
自编码器
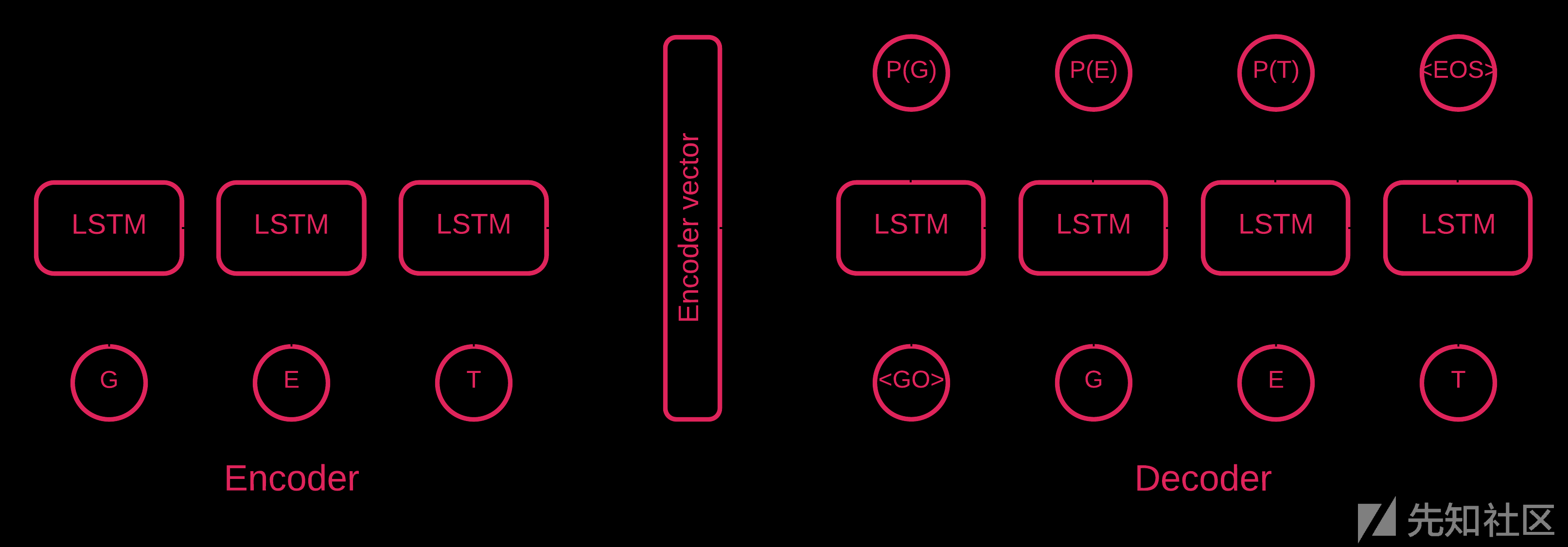
显而易见,在某些时候,序列到序列自编码器[5]才是最适合我们的模型。
序列到序列模型[7]由两个多层LSTM网络组成:一个编码器和一个解码器。其中,编码器的作用是将输入序列转换为固定维度的矢量,而解码器的作用是使用编码器的输出对目标矢量进行解码。
自编码器就是一种序列到序列模型,其思路就是设法让目标值等于其输入值。该模型的思想,就是教神经网络重建它所看到的东西,换句话说,其本质是学习一个相等函数。因此,对于一个训练好的自编码器,如果输入一个异常样本,那么,它在重建过程中,将会引入非常大的误差。
实现代码
我们的解决方案由多步组成:模型的初始化、训练、预测和验证。
对于存储库中的大多数代码来说,都是无需解释的,所以,这里只关注一些重要的部分。
该模型将初始化为Seq2Seq类的实例,该类的构造函数参数为:
batch_size:一个批量中包含的样本数
embed_size:嵌入空间的维度(应小于词汇量)
hidden_size:lstm中隐藏状态的数量
num_layers:lstm构造块的数量
checkpoints:检查点目录的路径
std_factor:用于定义模型阈值的stds数
dropout:每个元素被保留的概率
vocab:Vocabulary对象
之后,初始化自编码器的各个层。首先,来看看编码器的初始化:
# Encoder
cells = [self._lstm_cell(args['hidden_size']) for _ in range(args['num_layers'])]
multilstm = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)
_, enc_state = tf.nn.dynamic_rnn(
multilstm,
enc_embed_input,
sequence_length=self.lengths,
swap_memory=True,
dtype=tf.float32)
然后,看看解码器的初始化:
# Decoder
output_lengths = tf.reduce_sum(tf.to_int32(tf.not_equal(self.targets, 1)), 1)
helper = tf.contrib.seq2seq.TrainingHelper(
dec_embed_input,
output_lengths,
time_major=False)
cells = [self._lstm_cell(args['hidden_size']) for _ in range(args['num_layers'])]
dec_cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)
decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, helper, enc_state)
dec_outputs = tf.contrib.seq2seq.dynamic_decode(
decoder,
output_time_major=False,
impute_finished=True,
maximum_iterations=self.max_seq_len, swap_memory=True)
由于我们要解决的问题是异常检测,因此目标值和输入值是相同的。因此,我们的feed_dict会是下面的样子:
feed_dict = {
model.inputs: X,
model.targets: X,
model.lengths: L,
model.dropout: self.dropout,
model.batch_size: self.batch_size,
model.max_seq_len: seq_len}
每训练一轮之后,最佳模型都被保存为检查点,这样一来,完成训练后,就可以通过加载相应的检查点来进行预测了。为了进行测试,我们建立了一个实时Web应用程序,并使用我们的模型为其提供保护,这样就可以测试真实攻击是否成功。
受注意力机制效果的鼓舞,我们尝试将其应用于自编码器,结果发现,从最后一层输出的概率能更好地找出给定请求的异常部分。

在我们的样品测试阶段,得到了非常好的结果:精确率和召回率都接近0.99。ROC曲线直接奔1而去。这看起来棒极了!

最终代码可以从这里下载。
测试结果
实验结果证明,我们提出的Seq2Seq自编码器模型能够高精度地检测HTTP请求中的异常部分。

这个模型的工作方式更像人类:它只学习对Web应用程序而言是“正常”的用户请求。它能够检测请求中的异常部分,并突出显示请求中被视为异常部分的确切位置。我们利用针对测试应用程序的一些攻击数据对该模型的性能进行了评估,结果让人倍受鼓舞。例如,上图描绘了我们的模型如何检测到SQL注入分为两个Web表单参数。这种SQL注入技术被称为“分段化”,即攻击的有效载荷部分通过若干HTTP参数进行传递,这使得传统的、基于规则的WAF难以检测出这种情况,因为它们通常单独地检查每个参数。另外,我们的模型代码和训练/测试数据是以Jupyter笔记本的形式进行发布的,因此,任何人都可以重现我们的结果并提出改进建议。
总结与展望
当然,这里仍有许多不足之处有待改进。
首先,第一个问题是尝试对攻击进行分类。我们不妨回顾一下人类专家是如何发现网络攻击的:首先,他会注意到一些异常的事实,然后,他会开始推理,如果这是网络攻击的话,那么是什么类型的攻击。我们的模型能够完成第一步,它会在请求中查找异常序列。既然我们已经将所有重要的异常数据压缩为小型的字符序列,使得所有特定于应用程序的请求部分看起来都不像异常数据,那么,如果我们尝试在其上运行分类器的话,结果会如何呢?这看起来可以重现人类推理的第二步,即我们正在处理的攻击属于哪种类型。
第二个问题是可以用来逃避这种检测方法的对抗性示例。近年来,涌现出许多对抗性ML的研究论文,研究表明,人们能够让模型“看到”他们想要它看到的任何东西。显然,如果夏娃试图逃避我们的检测模型,那么,她可能会想出一些对抗技术来达到目的。
第三个问题是性能。现在,在两个GPU上训练我们的小数据集都需要几天时间,所以,目前根本不具备可扩展性。
尽管如此,我们仍然认为这项工作提出了一种有趣的方法来构建用于检测Web应用程序攻击的模型。在本研究中,最重要的贡献之一是试图以无人监督但具备可解释性的方式来模仿人类专家的推理过程。值得注意的是,我们可以清楚地看到这项研究将来的发展步骤,而且每一步都是非常合理,并极可能实现的。我们希望这项工作能够激发其他团队和研究人员对于深度学习在安全攻击检测方面的兴趣,并热切期待能够与他们进行广泛深入的合作。
参考资料
[1] Understanding LSTM networks
[2] Attention and Augmented Recurrent Neural Networks
[4] Attention is all you need (annotated)
[5] Neural Machine Translation (seq2seq) Tutorial
[6] Autoencoders