深入研究PDF的攻击面与1年间收获的100+CVEs
前言
本文是Asia Blackhat 17年上一篇译文,链接:Dig Into the Attack Surface of PDF and Gain 100+ CVEs in 1 Year
文中以PDF的漏洞挖掘为基础,提供了漏洞挖掘中作者所总结的一些思路。比如:如何去寻找目标的攻击面。译者觉得如何寻找攻击面,怎么提高fuzz效率这些点,对自己很有启发,所以索性将整个文章翻译,与大家分享。
摘要
可移植文档格式(a.k.a. PDF)是世界上使用最广泛的文件格式之一,这种复杂的文件格式也暴露了一个巨大的潜在攻击面,这对我们来说非常重要。在去年,通过深入挖掘PDF的攻击面并高效地fuzz很流行的PDF阅读器。作者在世界上最流行的PDF阅读器中发现了近150个漏洞,包括Adobe Acrobat and Reader,Foxit Reader,Google Chrome,Windows PDF Library, OS X Preview 和 Adobe Digital Editions。 供应商修复了100多个漏洞并为它们分配了CVE编号。
以下部分总结了本文:
- 简介
- 攻击面
- 测试用例
- fuzzing 技巧
- 结果
- 参考文献
1.简介
自Adobe于1993年发布完整的PDF规范以来,PDF已成为世界上更安全可靠的信息交换的标准[1]。但是,这种复杂的文件格式也会暴露出一个巨大的潜在攻击面,这对我们来说非常重要。有一些关于PDF安全性的研究,其中一些列出如下:
- Nicolas Grégoire: Dumb fuzzing XSLT engines in a smart way [2]
- Zero Day Initiative: Abusing Adobe Reader’s JavaScript APIs [3]
- Sebastian Apelt: Abusing the Reader’s embedded XFA engine for reliable Exploitation [4]
但是,这些研究中的每一项仅涵盖PDF的单个攻击面。更重要的是,从未提及基本但最常用的PDF特性,如图像和字体。由于PDF是一种复杂的格式,因此可以在这里完成大量工作。通过深入研究PDF的攻击面,我在各种PDF阅读器中发现了近150个漏洞。我的工作主要集中在Adobe Acrobat and Reader上,并且在这个产品中发现了大多数漏洞。但是,这并不意味着这个产品比其他PDF阅读器更容易受到攻击。
2.攻击面
如果你想知道攻击面是什么,首先要问自己的问题是如何找到攻击面。 在这里,我总结了四种可能的方法来找到攻击面。
2.1 标准文档
PDF的ISO标准是ISO 32000-1:2008 [5],文档的副本可以从Adobe的网站[1]免费下载。 该文档有756页,几乎描述了可移植文档格式本身的所有内容。 但是,本文档中未详细描述某些功能,例如JavaScript,XFA(XML Forms Architecture),FormCalc等。
以下是一些有用的参考资料:
- JavaScript for Acrobat API Reference [6]
- XML Forms Architecture (XFA) Specification [7]
- FormCalc User Reference [8]
此外,PDF支持嵌入外部文件,如字体(TrueType,Type0,Type1,Type3等),图像(Jpeg2000,Jpeg,Png,Bmp,Tiff,Gif,Jbig2等),XML(XSLT等)。 本文不讨论这些文件的标准文档。
2.2 安全公告
密切关注安全公告是观察安全趋势状态的好方法。 最重要的是,我们可以知道哪个组件存在缺陷。 以下是值得一读的公告:
- Zero Day Initiative’s Advisory [9]
- Chromium Issue Tracker [10]
- Adobe Security Bulletins and Advisories [11]
2.3 安装文件
对于闭源软件,查找攻击面的一种好方法是调查安装目录下的文件,尤其是可执行文件。 为了弄清楚特定可执行文件的功能,我们可以关注以下信息。
- 文件名
- 属性
- 内部字符串,包括ASCII和Unicode字符串
- 功能名称,包括内部符号和导出功能
- 版权信息
例如,通过分析文件的属性,我们可以得出结论,Adobe Reader安装目录中的文件JP2KLib.dll负责解析JPEG2000图像。 下图显示了该文件的属性页:
下图显示了部分文件在Adobe Acrobat and Reader的安装目录中的角色:

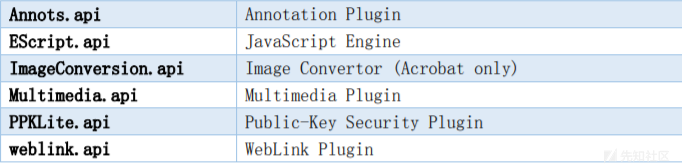
2.4 开源项目
找到攻击面的另一种方法是调查类似的开源项目。 PDFium是一个著名的开源PDF渲染引擎,它基于Foxit Reader的技术,由Chromium的开发人员维护。
事实上,通过比较PDFium的源代码和Foxit Reader的反汇编代码,我们可以在PDFium和Foxit Reader之间找到许多类似的代码。
我们可以通过分析PDFium的源代码来尝试找到攻击面。 但对于PDFium,另一种方法是分析libFuzzer组件。 目前,PDFium在“testing / libfuzzer”目录中有19个官方fuzzer[12]。 下图显示了这些fuzzer的详细信息:

3.测试用例
测试用例或种子文件在fuzz过程中起着重要作用。 对于传统的基于突变的模糊测试器,更多测试用例意味着更多可能的代码覆盖率,这最终意味着更多可能的崩溃。 要收集更多测试用例,在大多数情况下编写爬虫是一个可选项,但有一些替代方法。 在这里,我总结了两种可能的方法来收集测试用例。
3.1 基于代码覆盖测试用例的模糊器
American fuzzy lop(a.k.a AFL)和libFuzzer是两个着名的基于代码覆盖的模糊器。 对于AFL fuzzer,单个和小型测试用例足以驱动模糊测试过程。 对于libFuzzer,它通常使用一组最小化的测试用例作为输入数据,但即使没有任何初始测试用例,它仍然可以工作。
这两个模糊器的共同特点是它们将生成大量测试用例以获得更高的代码覆盖率。 那么为什么不重用AFL或libFuzzer生成的测试用例呢? 为了实现这一目标,我们必须使用AFL或libFuzzer来模糊开源库或类似的库。 下图显示了此方法的过程:
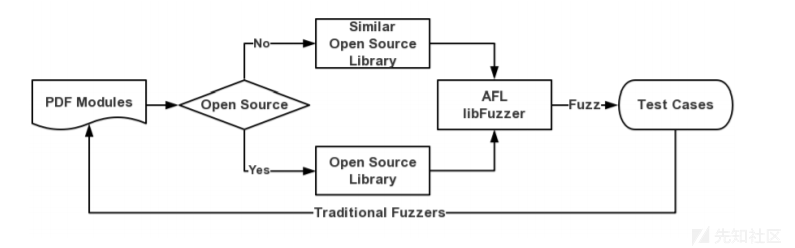
3.2 开源项目的测试套件
收集测试用例的另一种方法是重用开源项目的测试套件。 一般来说,流行的开源项目还维护着一个包含大量有效和无效文件的测试套件存储库。 某些测试用例可能会直接崩溃旧版本的二进制文件。 使用测试套件作为模糊器的种子文件是个好主意。 对于不常用的文件格式,甚至很难从搜索引擎中抓取一些。 例如,很难从Google收集一些JPEG2000图像,但是你可以从OpenJPEG中获取数百个文件[13]。 下图显示了一些可用的测试套件:

4.fuzzing 技巧
效率是模糊器的重要指标,尤其是在计算资源有限的情况下。 在这里,我总结了两个提高效率的fuzzing 技巧。
4.1 编写PDF制作工具
一般而言,PDF文件由纯文本和二进制数据组成。 如果你已经有一个具体的目标,如图像,字体等,那么直接模糊PDF并不是一个好主意。我们可以编写PDF制作工具,这样我们就只会改变我们感兴趣的数据。 有些第三方PDF制造商可以将文件(如图像和字体)转换为PDF文件。 但它不是推荐的解决方案,因为工具中的错误检查功能可能会导致丢失大量错误的测试用例。 在这种情况下,建议阅读标准文档并编写临时PDF制作工具。 PDF文件制作工具的技术细节将不在本文中讨论,因为它不是一项艰巨的任务。
4.2 Fuzz 第三方库
大型软件使用开源库并不奇怪。 尝试模糊第三方库来揭示安全漏洞是值得的。 以下显示了模糊第三方库的优点:
- 使用AFL或libFuzzer的Fuzz开源库效率更高
- 目标软件可能受已知漏洞的影响
- 零日漏洞影响使用该库的所有目标软件
下图显示了Adobe Acrobat and Reader使用的一些开源项目:
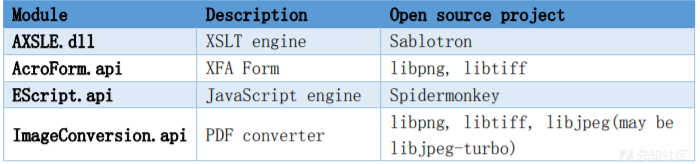
去年,我在libtiff的PixarLogDecode函数中发现了一个Out-of-Bounds写漏洞,并向Chromium报告。 这些帖子表明谷歌[14]的Mathias Svensson和思科Talos的Tyler Bohan [15]也发现了这个漏洞。 此漏洞的CVE标识符为CVE2016-5875。
下面显示受此漏洞影响的PDF阅读器:

对于Adobe Acrobat and Reader,渲染引擎未受影响,因为未在AcroForm.api中配置PixarLog压缩支持。 对于谷歌浏览器,启用了XFA的Canary,Dev和Beta版本受到影响(很快就会在Chrome Canary,Dev和Beta版本中启用XFA,很快就会停用)。 对于Foxit Reader,渲染引擎和ConvertToPDF插件都受到了影响。
4.3 编写包装器
PDF阅读器或Web浏览器是大型软件,创建这些产品的实例非常耗时,尤其是在模糊测试过程中反复创建实例。 为避免加载不必要的模块并初始化不必要的数据,编写包装器是一个不错的选择。
对于开源项目,编写包装器非常容易。 对于提供API的产品,例如Foxit Reader和Windows PDF Library,编写包装器也不难。 但对于不符合上述条件的产品,我们可能需要进行一些逆向工程来编写包装器。
Windows.Data.PDF.dll负责在Edge浏览器中呈现PDF,并且自Windows 8.1起在操作系统中提供。 可以通过Windows运行时API进行交互。 文章[16]展示了如何使用C ++编写用于呈现PDF的包装器。
5.结果
该研究始于2015年12月。它主要关注Adobe Acrobat and Reader,并且在这个产品中发现了大多数漏洞。 但是,这并不意味着这个产品比其他PDF阅读器更容易受到攻击。 在去年,122个漏洞已被供应商修补并分配了CVE编号。应该注意的是,如果漏洞满足以下条件之一,则将被排除在外:
- 不影响稳定版PDF阅读器的漏洞
- 供应商尚未解决的漏洞
- 其他研究人员报告的漏洞
下图显示了按供应商排序的漏洞分布:
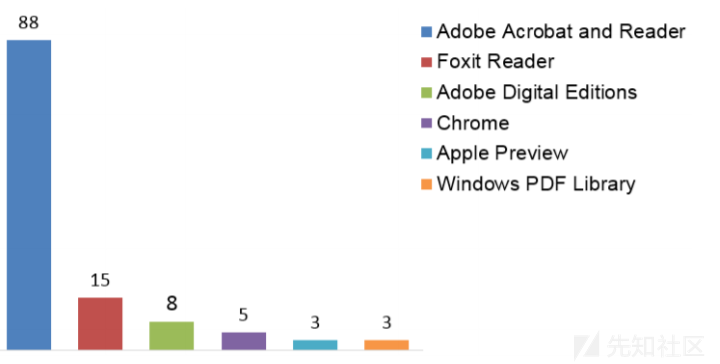
下图显示了按攻击面排序的漏洞分布:

再一次,应该注意的是,本文中的漏洞数据仅供参考,并不意味着哪个产品比其他产品更容易受到攻击。
6.参考文献
[1]. Document management - Portable document format - Part 1: PDF 1.7, http://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/PDF32000_2008.pdf
[2]. Dumb fuzzing XSLT engines in a smart way, http://www.nosuchcon.org/talks/2013/D1_04_Nicolas_Gregoire_XSLT_Fuzzing.pdf
[3]. Abusing Adobe Reader’s JavaScript APIs,
https://media.defcon.org/DEF%20CON%2023/DEF%20CON%2023%20presentations/DEFCON-23-Hariri-Spelman-Gorenc-Abusing-Adobe-Readers-JavaScript-APIs.pdf
[4]. Abusing the Reader’s embedded XFA engine for reliable Exploitation,
https://www.syscan360.org/slides/2016_SG_Sebastian_Apelt_Pwning_Adobe_Reader-Abusing_the_readers_embedded_XFA_engine_for_reliable_Exploitation.pdf
[5]. ISO 32000-1:2008, https://www.iso.org/standard/51502.html
[6]. JavaScript for Acrobat API Reference,
http://www.adobe.com/content/dam/Adobe/en/devnet/acrobat/pdfs/js_api_reference.pdf
[7]. XML Forms Architecture (XFA) Specification, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.364.2157&rep=rep1&type=pdf
[8]. FormCalc User Reference, http://help.adobe.com/en_US/livecycle/es/FormCalc.pdf
[9]. Zero Day Initiative’s published advisories, http://www.zerodayinitiative.com/advisories/published/
[10]. Chromium issue tracker,
https://bugs.chromium.org/p/chromium/issues/list?can=1&q=Type=%22Bug-Security%22
[11]. Adobe Security Bulletins and Advisories, https://helpx.adobe.com/security.html#acrobat
[12]. Official fuzzers for PDFium, https://pdfium.googlesource.com/pdfium/+/refs/heads/master/testing/libfuzzer/
[13]. OpenJPEG data, https://github.com/uclouvain/openjpeg-data
[14]. Seclists, http://seclists.org/oss-sec/2016/q2/623
[15]. LibTIFF Issues Lead To Code Execution, http://blog.talosintelligence.com/2016/10/LibTIFF-Code-Execution.html
[16]. Using WinRT API to render PDF, http://dev.activebasic.com/egtra/2015/12/24/853/