一个有趣的任意文件读取
前言
给你一个黑盒测试环境:可以上传任意文件,文件将在上传完成后被读取并将内容返回至网页。请问如何利用这点进行攻击?
如果你的答案只有 “构造突破上传路径” “尝试突破文件拓展名以getshell” “尝试利用解析漏洞”,那么这篇文章的思考也许会给你带来一些帮助。
环境及确认
这个问题是我在做一道CTF题目时所遇到的,题目给出了一个站点,打开内容如下
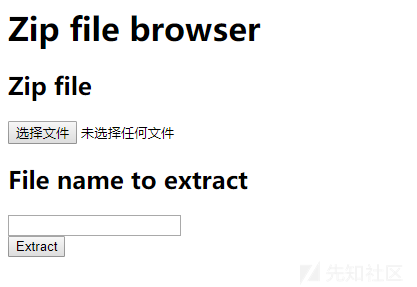
题目的玩法很清楚,上传一个zip压缩包,程序会进行解压,指定要读取的文件名,文件内容将被返回至网页。
我们先对普通的文件进行解压,构造一个存在1.txt的压缩包,内容为hello world
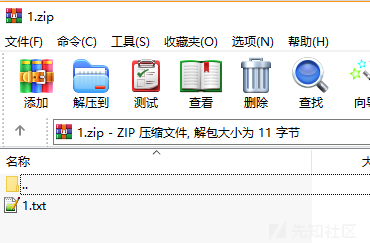
网页返回hello world,毫无疑问。
尝试攻击读取路径
我们先尝试一下跨目录读取文件--先想办法获取到站点目录,我们尝试解压不存在的2.txt,程序返回一个Warning级别的报错Warning: file_get_contents(/tmp/dir_hackme5_5809325816847423574698891475912692524028/2.txt): failed to open stream: No such file or directory in /home/hackme5/task/index.php on line 41,由此我们获取到了当前文件位置。
尝试一下extract../../../../../../../../../../home/hackme5/task/index.php,却提示hax0r no!,想必是存在过滤,使用/home/hackme5/task/index.php同样被过滤了,测试发现是/字符被检测,而\ 字符在linux又不能完成路径的作用。
但是不能轻言放弃,于是我开了burp进行了字符的fuzz,使用迭代器创建%00~%ff并为payload使用urldecode选项,在/ 和路径开头、结尾处放置payload,但结果一无所获,没有任何值得欣喜的结果产生。(不过因为当时测试的时候发现容易把网站跑出点问题,所以复现的时候就不再进行fuzz了,所以关于fuzz部分都不再截图,不过这也并不是正确解法,所以也无关紧要。对站点进行fuzz的话,需要注意速度,不然网站可能承受不了。)
失败了吗?是的,几乎可以确定,文件读取路径不是可以攻击的目标。
尝试构造特殊压缩文件
在构造读取路径失败之后,第一件做的事就是构造路径为../../../../../home/hackme5/task/shell.php的压缩包,但是失败了。这是是十分值得尝试的攻击,我还使用了burp对上传的压缩包内的路径进行fuzz,希望能得到一点启发,但是并没有成功getshell。
仔细想想,既然过滤了/,也就表示如果存在目录结构,那么可能会出一些问题。我们可以尝试一下构造存在目录结构的压缩包,当然,另一方面,我们更应该尝试一下通过在压缩包中构造../这类路径来尝试突破解压路径,如果成功了,就意味着我们可以getshell。
我们先尝试一下构造目录。

此时在压缩包中,存在test/1.txt这样的结构,我们试着上传并读取1.txt。

可以看到的是,程序直接解压了位于test/1.txt中的文件。这似乎有点不太有利于攻击。我们在不同层级目录下创建同名1.txt文件测试,test文件夹内的内容为hello world,test文件夹外的内容为hello me。
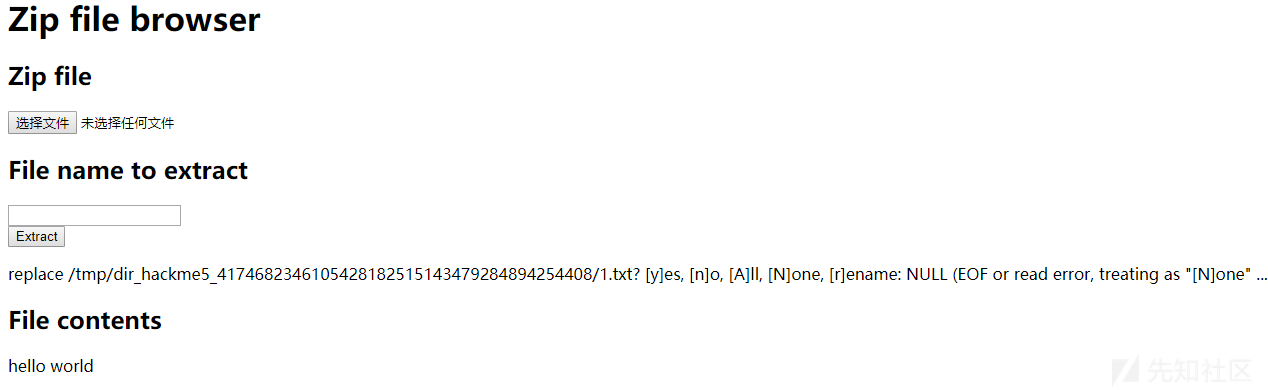
可以看到,程序报了一个错误,并且最后解压出的文件为test文件夹内的文件。此时我们可以大概猜测一件事情:程序将压缩文件进行解压的时候,处理了路径问题,将文件解压到了同一目录下。
此外,根据报错提示,我们还可以猜测,php代码使用了类似system('code')的形式调用了其他程序,实际上根据后面的[y]es, [n]o, [A]ll, [N]one, [r]ename: NULL (EOF or read error, treating as "[N]one" ...),我们可以从谷歌或者根据经验来推断出,调用的是unzip。
或许我们还需要更多的报错信息,当我们输入为空时,报错内容如下

我们还可以从burp的fuzz返回信息中获取一些其他的信息,以保证信息的完整。总之这些报错内容都提供了一点“程序使用unzip -j来进行解压”
总之,对压缩包进行任何的构造,都是徒劳的,除非构造一个带有unzip的0day的压缩包,但是我Google了一圈,并没有适用的相关消息。
失败了吗?是的,我很确信无论如何对压缩包进行构造,都产生不了危害,顶多是让php报一些warning。
思考,解决方案
我们先来理一下程序的逻辑。
首先,将压缩包进行不带目录的解压到一个/tmp目录下随机的文件夹里,然后从文件夹里读取我们想要的文件名,但无法带路径。
随机的文件夹能否控制?确定不能
读取的文件路径能否控制?确定不能
文件解压能否跳出路径?确定不能
这个控制是否安全?如果是我的话会怎么写?
想到最后一个问题的时候,我想了想,是的,控制是安全的,如果是我我也会这么写。
想到这里,我想,唯一能攻击的点就是读取的文件本身了。我们需要一个特殊的文件。如果…文件能够重定向的话…于是我想到了软连接。
linux下的软连接和Windows下的快捷方式类似,都是一个文件,但是不同的是,windows资源管理器可以直接操作快捷方式本身,而Linux下的操作默认往往是直接操作软连接指向的对象。
比如,在Windows下,我们可以使用vim对.lnk文件进行编辑读取,但是同样的命令,在linux下,操作的就是软连接指向的对象。
想到这里,我测试了一下php中的file_get_contents函数是否同样如此
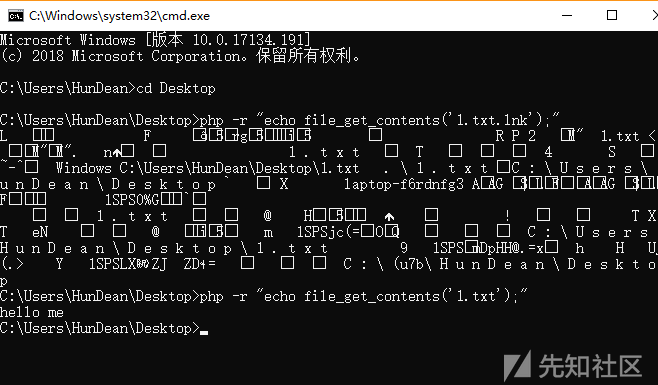
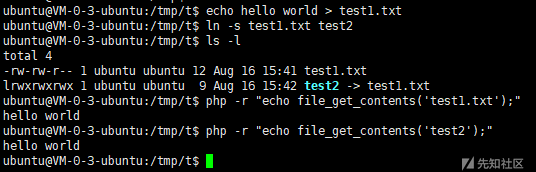
结果是显然成立的。由此我们就可以尝试利用软链接来达到任意文件读取的目的。
于是我们通过ln -s /home/hackme5/task/index.php test创建一个软链接,然后zip -y 1.zip test来创建一个压缩包,使用-y参数以保证打包的是一个软链接文件,然后再来尝试一下这个新的压缩包。
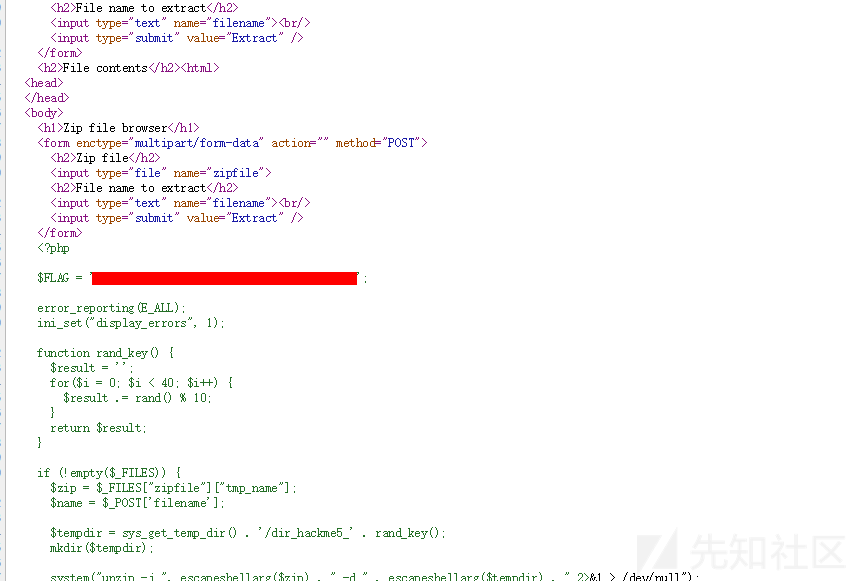
于是我们成功的读到了index.php的内容,源码里面给出了flag。如果喜欢的话,读一读其他文件也未尝不可。

更多的思考
当我发现软链接的这种玩法时,有一丝兴奋,这意味着在一些情况下,我们可以把在线浏览变成任意读取,而不需要依靠其他方式跨路径,在另一个角度看来,这就像是“角色伪造”,当程序根据一些可控文件的内容从而进行一些流程判定时,的确将有引发漏洞的可能。
沿着软链接产生判定错误的思路,我搜索了一下,看到了这篇GitLab 任意文件读取漏洞的分析,其中一步同样利用到了软连接。
而在ph师傅的小密圈里找到了另一个相关案例CVE-2016-1247,不过不便贴出原文,这里给出的是来自知道创宇的分析。
上面给出的两个案例,一个产生了任意读取的作用,另一个影响了程序的流程判定,已经把我能想到的两点攻击都展现出来了。
对于软连接而言,修改和读取软连接,默认情况下读取的是软连接指向的对象,而删除软连接,则是删除软连接自身,因此基于软连接的攻击并不适合那种“检查后判断是否删除”的流程(不会造成源文件删除,也就不会产生任意文件删除),此外还需要目标平台为*uix,有一点局限性,但起码提供了一些新的思路。