使用机器学习检测混淆的命令行
本文介绍如何使用机器学习方法解决终端上的安全难题:检测混淆的Windows命令行调用。
简介
恶意攻击者越来越多地使用PowerShell、cmd.exe这样的内置工具作为攻击活动的一部分来最小化被白名单防御策略检测到的概率。在可见的语句和命令的最终行为之间加上一个间接层可增加检测的难度。Invoke-Obfuscation和Invoke-DOSfuscation就是最近发布的自动混淆Powershell和cmd.exe的工具。
传统的模式匹配和基于规则的检测方法并不是一个通用的解决方案,而且维护的工作量很大。本文介绍如何利用机器学习方法来解决这一难题。
背景
混淆是恶意软件用来隐藏恶意活动的常用方法,从加密恶意payload到混淆字符串再到JS混淆都非常常见。混淆的目的是可以分为2个方面:
- 使在可执行代码、字符串和脚本中更难找到对应的模式;
- 使逆向工程师和分析师更难解密和完全理解恶意软件的作用。
从这个角度看,命令行混淆并不是一个新问题,但对cmd.exe的命令进行混淆相对比较新。最新发布的工具Invoke-Obfuscation (对PowerShell) 和Invoke-DOSfuscation (对cmd.exe)就证明了这些命令的灵活性,以及经过复杂的混淆之后命令如何有效地运行。
在混淆和非混淆的命令行中有两个维度,如图1和图2所示,可以分为simple/complex(简单/复杂)和clear/obfuscated(混淆/非混淆)。Simple意味着比较短和简单的字符串,其中可能含有混淆,complex表示长的、复杂的字符串,其中可能含有混淆,也可能不含混淆。因为其复杂性,所以这样的分类从机器学习视角来看也是一个比较难的问题。
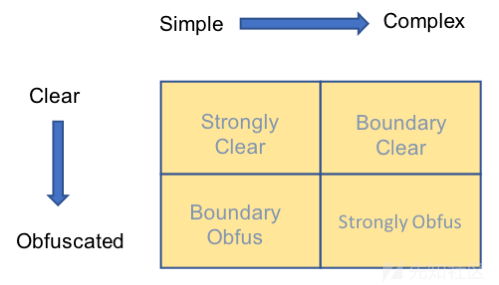
图1: 混淆的维度

图2: 弱混淆和强混淆示例
传统混淆检测
传统的混淆检测可以分为3种方法,第一个方法是写大量复杂的正则表达式来匹配Windows命令行最长被滥用的语法。图3就是这样的一个例子,图4是用来检测的命令序列的正则表达式。

图3: 常见的混淆匹配正则表达式

图4: 常见的混淆模式
这种方法有两个问题:
- 1是不可能开发出覆盖每种滥用可能性的正则表达式。命令行的灵活性导致使用正则表达式的不现实性。
- 2是即使正则表达式匹配了恶意样本使用的混淆几时,但攻击者对混淆技术做一点小小的更改就可以绕过正则表达式的检测。图5是对图4中序列的一个微小更改,用来绕过正则表达式的检测。
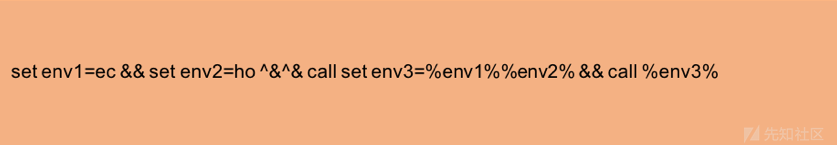
图5: 对混淆命令行进行更改来打破图3中的正则表达式的检测
第二个方法与机器学习方法类似,即写一个复杂的if-then规则。但是这样的规则很难提取和验证,维护成本也很大。图6是if-then规则的一个例子。

图6: 可能暗示混淆的if-then规则
第3个方法是融合正则表达式和if-then规则。这种方法极大地增加了开发和维护成本,同时存在前两种方法存在的脆弱性问题。图7是融合正则表达式和if-then规则的方法示例。从中可以看出生成、测试、维护和确定这些规则效率的复杂性。

图7: 融合正则表达式和if-then规则的检测方法示例
机器学习方法
使用机器学习方法简化了这些问题。下面首先介绍2种机器学习的方法:基于特定的方法和无特征的端对端方法。
一些机器学习算法可以处理任意类型的原始数据,神经网络就是这样的例子。大多数的机器学习算法需要建模者首先从原始数据中提取出特征,比如基于树的算法。
无特征机器学习
神经网络需要提前标记了特征的数据,而无特征机器学习的优势就在于可以处理原始数据,而无须进行特征设计和特征提取。模型中的第一步是将文本数据转换为数字格式。研究人员使用了基于字符的编码方法,其中每个字符类型都是用一个实数值编码的。在训练过程中该值可以自动提取,并应用到cmd.exe语法中。
机器特征的机器学习
研究人员还使用了手动提取特征和Gradient Boosted Decision Tree(梯度提升决策树)方法。模型中的特征主要来源于对字符集和关键字的频率进行统计分析。比如,多次出现的%字符可能会用于检测潜在的混淆。因为简单特征对分类的影响并不大,基于树的模型和特征融合可以学习数据中灵活的模式。
期望的结果是这些模式都非常鲁棒,可以用于之后混淆变种的分析。
数据和实验
研究人员从上万个终端事件收集了非混淆的数据,并用Invoke-DOSfuscation这类方法生成了混淆后的数据。然后开发出机器学习模型,混淆后的数据集的80%作为训练数据,剩余20%作为测试数据。研究人员确认其训练测试的分隔是分成抽样的。对于无特征机器学习,研究人员输入Unicode code point(代码点)到CNN模型的第一层。然后在进入到神经网络的其他部分前,第一层会将code point转化为语义有意义的数值表示。
对Gradient Boosted Tree方法,研究人员从原始的命令行中生成了以下特征:
- 命令行的长度
- 命令行中的补字符号数
- 匹配符合数
- 命令行中空白所占比例
- 特殊字符所占比例
- 字符串的熵
- 命令行中字符串cmd和power的频率
这些特征单独来看并不是混淆的好的标识,但Gradient Boosted Tree类似的灵活的分类器在用这些特征在足够的数据上进行训练后,就可以会混淆和非混淆命令行进行分类了。
结果
根据测试集的评估结果,研究人员在Gradient Boosted Tree和神经网络模型上得出了几乎相同的结果。
GBT模型的结果在F1-score、精确率和召回率方面近乎完美,接近1,CNN模型在精确度方面稍低。
研究人员并不期望在实际的场景中会有这样完美的结果,但还是给实际应用给了很大的信息。考虑到所有混淆后的样本都是由Invoke-DOSfuscation工具这一个源生成的,但实际场景中会有许多不同的混淆样本由不同的混淆工具生成,因此,研究人员也在从实际场景中去收集混淆后的样本。研究人员认为PowerShell混淆和命令混淆在未来的恶意软件家族中会继续出现。
测试过程中,研究人员与Invoke-DOSfuscation的作者联系,请他给出一些传统混淆检测器很难检测的混淆样本。然后用机器学习检测器进行检测,如图8所示,检测结果显示可以成功检测混淆。

图8: 使用检测学习混淆检测器来检测混淆后的文本示例
研究人员还创建了看似加密的文本,这对人类检测人员看来也是混淆过的。这被用来检测机器学习检测器的边界。测试结果显示机器学习检测器正确地将文本显示为非混淆的,如图9所示。

图9: 机器学习检测器准确分类看似加密的文本
最后,图10显示了机器学习混淆检测器成功检测出复杂的、非混淆的命令行的例子,但非机器学习检测器基于统计特征会将其误分类为混淆的命令。

图10: 机器学习混淆检测器成功检测出复杂的、非混淆的命令行
总结
本文介绍了如何使用机器学习方法来检测混淆的Windows命令行,这可以用于识别恶意的命令行滥用。研究人员证明了使用机器学习方法可以增加检测的准确率和成本。机器学习算法可以更加灵活地检测出混淆中的新变种,如果发现新的可绕过检测器的样本,可以将这些样本放入训练集中来重新训练模型。
机器学习方法的成功应用再次证明了机器学习在解决计算机安全领域难题的有用性。研究人员认为未来机器学习在计算机安全领域会有更多的应用。