浅谈纵深防爬的”抗战“ 之路
0x00 爬虫=爬数据?
之所以又提“什么是爬虫”这个老生常谈的问题,是前几天有个验证码接口被刷的用户在群里讨论防护方案,他认为这种不算是爬虫,爬数据的才叫爬虫(这里的“爬数据”指的是爬机票酒店住宿价格新闻小说漫画评论SKU等等)。
没错,传统意义上的爬虫定义是这样的,但本文即将讨论的爬虫,指任何能自动化完成一系列Web请求最终达到某种目的的程序,这些目的包括但不限于模拟投票让你在某个在线评选中高票胜出、破解你的验证码(或者把验证码发给打码平台)、模拟正常用户下单买票以后却不付款(让正常用户无票可买)等等、……现如今爬虫的“趋利性”已经非常明显,从获取核心的商业信息(如价格、用户信息等)到扰乱正常用户的活动(如抢购、恶意刷票等),爬虫已带来越来越多业务营收、公司信誉以及核心数据方面的损失。
0x01 爬虫的幕后黑手们
反爬虫与反反爬虫的对抗是一条不归路吗?
这个问题要辩证来看,从阿里云安全团队线上对抗的经验来看,答案完全取决于你在跟什么水平的爬虫对抗,我们姑且拍脑袋把互联网上的爬虫流量来源划为下面这几类:
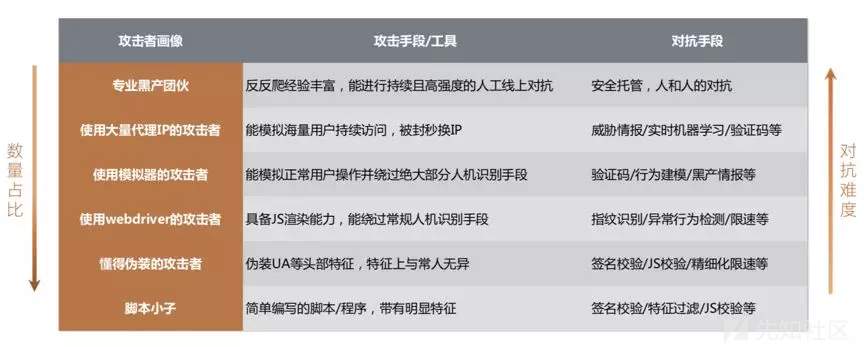
嗯…你大概也看出来,越往上,就越是不归路了。现如今专业的黑灰产团伙因为背后有足够强的利益驱动,不论是资源(比如换IP用的IP池)还是技术能力(各种绕过防爬策略的猥琐手法)都有了长足进步,老话怎么说的来着,无利不起早,就怕流氓会武术……
不过还好,二八法则至少从量上看也适用于这个话题,往往占比例更大的,还是技术含量相对较低的爬虫,毕竟攻防都有成本,对于大多数爬虫来说,爬不动你可以爬别人嘛,何必花力气研究你的防爬策略呢?毕竟没有防爬保护的站点才是大多数XD。
捡软柿子捏的思路还有另一个更常见的场景。现如今大部分的业务都会提供传统PC、移动端APP以及API等多个服务渠道,APP做了加固爬网页,网页做了混淆爬API…这是真真的木桶原理,哪里好爬爬哪里,哪里防爬策略好绕过就爬哪里,这不是理论上的场景,而是我们已经真实遇到的案例。因此,一个能覆盖所有场景的防爬体系非常重要。
0x02 何为纵深?有多深?
因材施教,对症下药。回到之前对攻击者的分层上来说,我们需要有不同的套路对付不同等级的攻击者。在无数个与线上爬虫对抗的日夜里,我们既见过简单封禁一个IP就搞定的大规模撞库行为,也遇到过具备完善的监控系统和技术人员24小时绕个不停的黑产团伙。从对抗上来说,绝对安全不会被绕过的系统是不存在的,我们能做的就是不断提高攻击者的绕过成本,而这个成本会随着防护层次的丰富指数级上涨。
下面我们来梳理一下防爬的思路:特征库直接封禁、JS无感人机识别、行为异常检测和威胁情报库。
1. 特征检测
经验丰富的安全人员往往能很快从访问日志中看出有无异常行为,举几个常见的例子:
- 正常用户不会直接请求的页面访问却不带任何referer
- 从主域名跳转过来的请求不带任何cookie
- UA包含Python/Java/xxBot/Selenium
- 省内生活论坛却有大量海外IP访问
- request body中包含一个大量重复的手机号
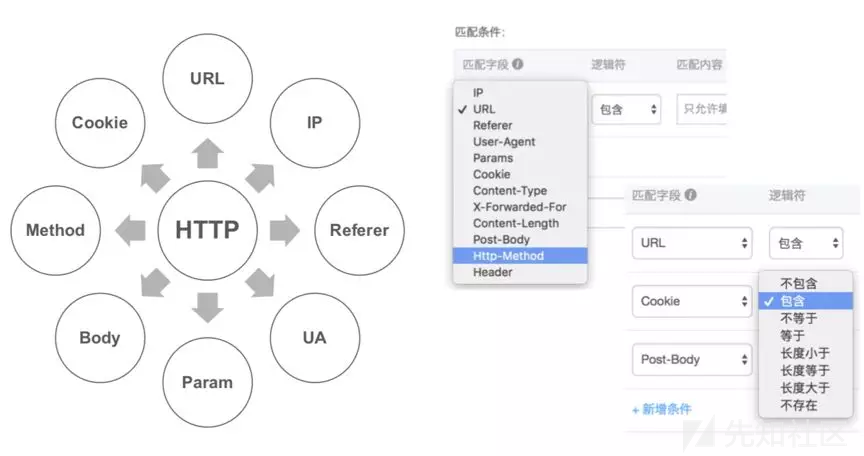
这些明显或不明显的“特征”,都可以作为第一道爬虫检测策略——特征封禁。这里的特征可以是各种HTTP头部、body以及它们的组合条件。阿里云爬虫风险管理产品提供了非常灵活的七层访问控制策略,如同一把应用层的瑞士军刀,是行走江湖的必备佳品:
2. JS无感人机识别
除了访问控制,通过JS采集网页环境中的操作行为、设备硬件信息、指纹等特征来判断请求是否来自于自动化工具也是常见的思路。思路虽然简单,但在没什么秘密的前端对抗环境中,确保采集到的信息和风险判断模型的准确性却是专业的安全团队投入相当大的精力来建设的能力。

现在,我们将阿里巴巴集团积累多年的验证码集成到了防爬产品中,用户不需要做任何业务改造即可接入,一键获得淘宝同款的人机识别能力,在诸如下图所示的防护垃圾注册、撞库、暴力破解、验证码被刷、恶意下单等场景下有着很好的效果(补充一句:正经用户无感知哟):
3. 行为异常检测
特征匹配因具备很强的对抗特征,是最容易绕过的防护规则,接下来我们聊聊异常行为检测。说到行为,大部分第一反应肯定是限速。没错,但是限速两个字展开却有很多细节的问题,比如以什么路径作为限速条件?除了IP还能以什么作为限速对象?除了频率还有什么统计方式?我们再举几个栗子:
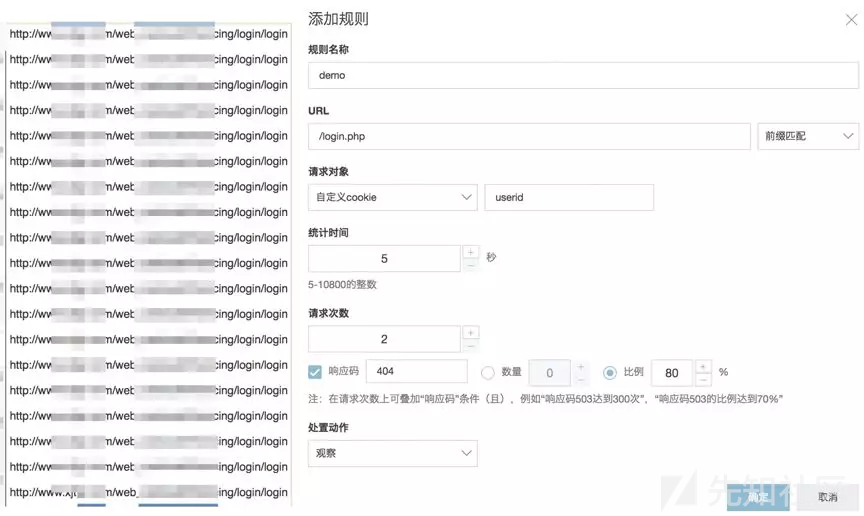
我担心以IP为对象限速会误伤公司出口等NAT环境,希望以客户端为对象来统计
没问题,我们可以用cookie、设备指纹、MAC地址等多种指标。我只关注登录接口的暴力破解行为,希望只对这个接口做统计
没问题,统计路径匹配/login.php即可,我们支持前缀、正则、完全匹配等方式。我的业务请求中会有一个参数userid来标识某个用户,我想基于这个指标做限速
没问题,您只需要在配置里指定这个参数的key(如userid)即可,我们会对超过阈值的value(如xiaoming)进行处置。爬虫会遍历我业务中很多不存在的路径,我希望当一个会话中404的比例超过一定值时采取措施
没问题,可以根据响应状态码(如404、502)的统计来识别爬虫。
这类基于会话行为的规则也可以灵活的满足很多场景下的异常行为检测需求:
当然异常行为检测远不止这些,从UBA(UserBehavior Analysis)角度去建模,也是一种不错的思路(毕竟这年头不说点机器学习也不好意思谈安全了)。机器学习能够综合多个观察角度和维度去识别爬虫,增加了绕过和对抗的成本,这是相对于规则类防护的一个优势。而且,针对一些精心构造的低频、离散IP,机器学习可以很好的弥补规则检测的短板。
目前,阿里云安全的算法团队已经有十几种针对不同场景下恶意爬虫的识别模型,包括时序异常、请求分布异常、业务逻辑异常、上下文异常、指纹异常等等,借助阿里云平台强大的实时计算能力,可以做到实时的异常行为检测——实时是个很关键的点,因为随着爬虫越来越智能,有一些高级爬虫等一般算法产出结果的时候早就消失在人海深藏功与名了,识别效率会大打折扣。
4. 威胁情报能力
之前说到了甲方做防爬的一些优势,那么从全国最大的云平台上诞生的防爬产品最大的优势就是威胁情报的能力了,这里再举个栗子:
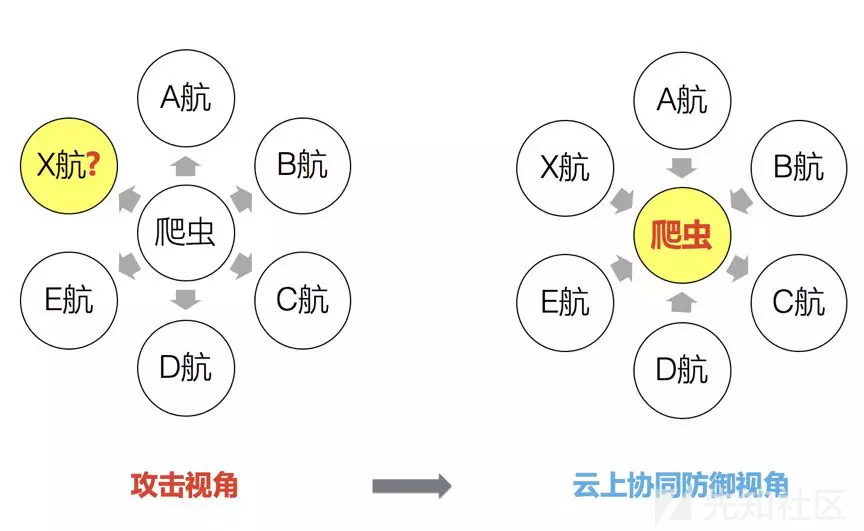
以航空行业为例,机票向来是爬虫重点关注的对象,从爬虫的角度来看,一个黄牛或旅行社背后的爬虫往往会光顾各大航司以获取最全的票价信息,所以当我们检测到一个爬虫光顾了ABCDE航司后,你说他爬X航的概率大吗?当然。 这个不是假设,而是我们已经在实际的流量中发现的行为。于是我们由此拓展开来,基于一定的模型生成在多家航司网站上有过可疑行为的,实时的(注意是实时的哦)爬虫库,这就是典型的云上协同防御模型。这样对于新接入的X航来说,我们甚至可以用情报的思路把防护做到事前。
其实从攻击者的角度来看也很好理解,虽然现如今专业的爬虫都会租用大规模的代理IP池、宽带IP池,实现“被封秒换”的效果以逃避爬虫检测,但攻击的成本也是存在的,也要考虑资源复用的问题,所以不同的攻击者从IP贩子手里买到的可能是相同的一票IP。于是当我们把这些代理IP扩大到一定量以后,就会在恶意行为上出现越来越高的重合度。
目前阿里云安全团队从云上流量分析出的各种类型的威胁情报库已经具备一定的规模,依据云平台强大的计算能力,可以依据历史一小时/一天/一周(场景不同)的流量情况计算,以应对快速变化的黑灰产资源池,这是我们防爬体系的另一个重要组成部分。
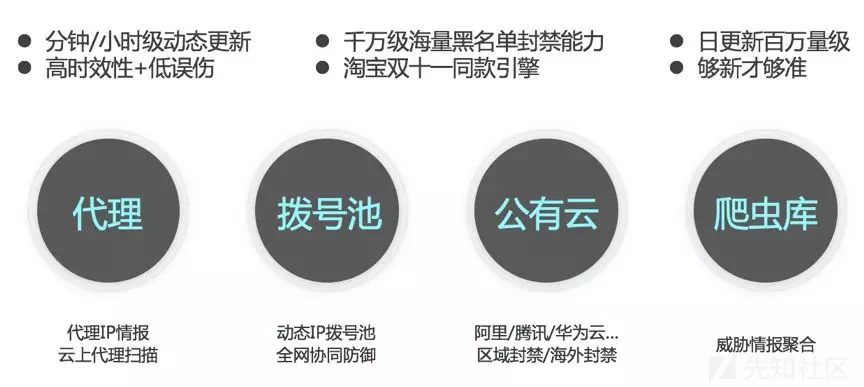
0x03 好的防爬系统应该体现人的价值
攻防对抗永远是动态的,没有一套万金油的策略可以搞定所有场景,因此好的安全产品应该体现人的价值,帮助安全工程师将自身的技术和经验最高效地发挥价值。所以,阿里云安全团队致力于提供给用户的爬虫风险管理产品,致力于打造一套尽可能灵活的“工具”,帮助用户跳过繁琐的实现细节,直接在策略甚至业务层面进行防护规则的部署,同时利用云上海量的数据和计算能力、弹性扩容能力以及威胁情报,帮用户快速打造适合自己业务特点的防爬系统。
同时,结合阿里云的SLS日志服务,我们可以很方便的对当前流量做快速分析,或者设置个性化的业务指标监控和告警,如将最近半小时内某域名下某个IP的访问路径按次数排序、某种策略的命中及绕过情况、监控每分钟的注册量/下单量有没有突增的情况、滑块验证弹出及通过的情况等等,这样我们就完成了一个从检测到处置再到监控和对抗的闭环。
0x04 结语
反爬与反反爬是一场无休止的战争,像任何一场战争一样,最终拼的还是双方的资源。近些年随着selenium、按键精灵、打码平台和人工智能等一系列“猥琐”手段的加入,对于真正持续投入对抗的场景,终局大概是双方达成某种心照不宣的默契然后相忘于江湖吧……
最后打个广告,阿里云防爬产品”爬虫风险管理“已全面开放公测,主打数据爬取、接口滥刷、恶意刷票、撞库爆破等防护场景,欢迎老铁们来尝鲜,一起交流: