IPS BYPASS姿势
0x00 背景
之前经常也看到一些bypass的方法,如利用mysql的特性bypass web程序的防注入函数,又例如直接构造绕过防注入的正则等等。最近在编写IPS特征的时候,发现在一些其他的角度上可以做到绕过IPS防护,下面就将这些另外的角度做一个总结。在描述的时候涉及到一些网络层面的基础知识,这里不单独叙述,在利用姿势里面强调。
Ps.此处说明,方法不代表能bypass掉所有的IPS。
0x01 bypass姿势
IPS性能优化导致IPS规则bypass
做过IPS测试的选手应该都会听到过这样一句话,厂商在保证检测率90%的条件下,性能是多少。这里所说的性能一般是性能测试中涉及的新建,并发,吞吐等等指标。此处不叙述这些指标。
从上面可以看出IPS的检测效果和性能是有一个平衡关系的。先来描述一些基本概念,第一个概念是数据流和会话的概念:
在网络基础中有五元组的概念,即为源地址,目的地址,源端口,目的端口以及协议号,五元组相同即认为是一条同样的会话,当你在浏览器中访问网站的时候,打开wireshark抓包工具抓包,然后follow下这一条stream可以发现如下内容。这也就是所描述的会话和流。
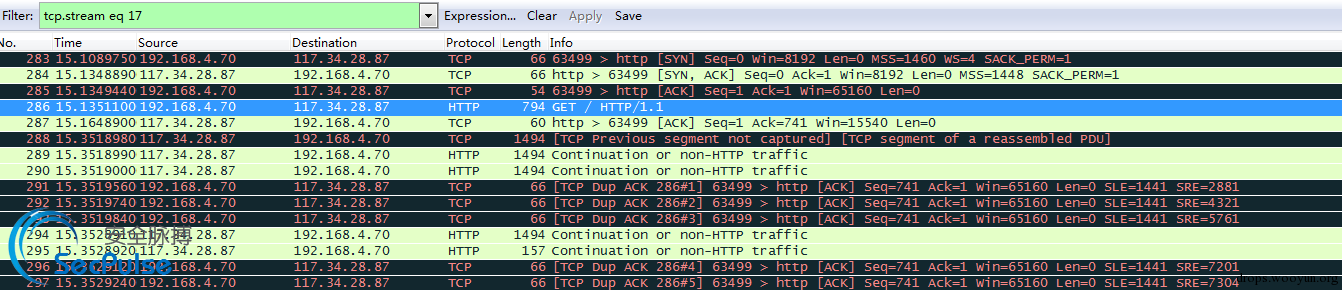
IPS中一般是通过会话,流来进行检测的。如何来通过会话来检测呢,这里有第二个概念需要了解,第二个概念为重组:
为什么要重组,一个以太网包的最大长度为1518字节,譬如我们这时候发送一个大附件出去,此时就会把数据分成多个数据包发送出去,数据包在internet上转发的时候会被路由转发,在整个internet中转发的时候会出现乱序,导致有些数据包先到IPS设备,有些数据包后到IPS设备,此时就需要IPS将发送的数据包,完整的组合起来。因为组合起来之后才可以方便后面的数据分析,提取内容。如下图所示:

现在问题就来了,如果对于每条数据流的所有内容都做检测应该就没问题了,但是每条数据流的所有内容都进行检测,肯定所耗费的资源也就越多,应该大部分厂商不会检测数据流的所有包。因此就会出现个问题,到底检测多大的大小呢?在处理这个问题的时候有些使用的是包数,有些使用的是流大小的方法。但是这都会导致所说的一个问题,就是性能优化导致的bypass。如下图所示:

在该数据流中,前面多个包如20个包没有发现特征,20个包之后的内容不再做ips检测,这样后面的包里的特征就没有受到IPS引擎的检测。
利用:
例如我们在绕过bypass的时候,人为的将get方式提交改为post方式提交,同时在提交的时候,添加大量的填充数据,如使用post的方式,上传一个大的文件,虽然这部分填充数据不会被服务器端所处理,但是在通过IPS设备的时候就会被解析处理,有可能就bypass掉了ips的检测。
截断绕过IPS规则
Ips规则即为经常说到的ips特征,见到过的很多IPS特征都是根据不同协议来分的,如http,smtp,pop3,tcp,udp等等,每一种协议下又可以有不同的内容,如http协议下可以有cookie,header,msgbody等等。
这些特征都会被以一种算法加载到内存中,然后等到数据流解析完毕之后,进行匹配。因此这里又涉及到了一个基础概念:协议解析。
协议解析为啥?即将上面重组过后的信息,提取相应的内容赋值给协议变量。打个比方,如http协议,在重组完成之后肯定会出现http标准的内容,http的cookie,header,method等等,因此IPS会根据标准的内容解析,然后将解析的内容赋值给类似http_cookie,http_method的变量。有了这些变量就可以对数据流进行IPS特征匹配了。效果如下图所示:

解析出来各种http的相关内容,当然不同的协议解析出来的内容不相同,有的可能是smtp,tcp等等。
但是在这个过程中,如果程序员处理的不好,就会出现IPS bypass的情况。
举个例子,例如某漏洞的特征为search{xxxx},特征利用正则编写,需要匹配search{},括号内容随意,此时,攻击者提交search{sada%00},这样在协议解析的时候出来的结果是search{sada,不会匹配到后面的}符号,导致了bypass。
编码绕过IPS规则
url编码绕过IPS规则同样存在可能性。
在IPS中对于同一种协议可能有多种协议变量,如HTTP中可能有没有url_decode的协议变量和进行了url_decode的协议变量,如果没有正确使用也会导致IPS规则绕过。
浏览器在发送数据包的时候,会对url进行编码,而且不同浏览器的编码还不相同,例如chrome对于单引号编码为%27,但是IE浏览器对于单引号不做编码,同时浏览器对于英文字符都不做编码的。
之前碰到了一个例子,在IPS规则中,书写特征的人员使用了未解码的协议变量书写特征,如特征为包含search关键字,此时我们可以这样bypass规则,将search书写为%73earch,这样当数据包经过IPS设备的时候,内容未作解码还是为%73earch,未匹配上规则,而到服务器端时候,被解码为search。

因此这里说,在做web测试的时候,尽量编码一些英文字符提交,可能会有惊喜。
请求方式绕过IPS规则
http常用请求方式有GET和POST两种方式,POST提交的时候又常见的有www/urlencode的方式和multipart的方式,后者常常用于文件上传。 查看一些CMS的源码,经常会发现有类似的代码,如下代码摘抄自dedecms:
if (!defined('DEDEREQUEST'))
{
//检查和注册外部提交的变量
foreach($_REQUEST as $_k=>$_v)
{
if( strlen($_k)>0 && preg_match('/^(cfg_|GLOBALS)/',$_k) )
{
exit('Request var not allow!');
}
}
foreach(Array('_GET','_POST','_COOKIE') as $_request)
{
foreach($$_request as $_k => $_v) ${$_k} = _RunMagicQuotes($_v);
}
}
可以看出无论get提交,cookie提交,post提交对于web服务器端,其实效果是一样的,但是对于IPS就不一样了。在我接触的不同的IPS中,对于不同http请求部分,拥有不同的协议变量,同时不同的协议变量也有解码和未解码之分。
举例,如dedecms中的一个漏洞,uploadsafe.inc.php界面的错误过滤导致recommend.php页面可以sql注入。网上给出的POC通常是一个url,直接粘贴到浏览器,即可以获取到了管理员账号密码,因此一些IPS规则通常就直接书写了一个httpurl解码的规则。
很容易此处更换一下提交方式,使用post的方式,无论是urlencode的方式还是form-data的方式,均可以绕过该规则。
此处如果发现post方式被过滤了,此处对于post的内容进行编码,然后再提交,仍然存在可以绕过的可能。
因此各位在编写payload的时候尽量使用编码过的post方式提交,成功的概率大一点。
Ps.之前wooyun上看见有提交二进制文件混淆绕过的,此处暂时没有想到为什么。
其他方式绕过IPS规则
1:对于host以及useraget的修改 一般不要使用默认的useragent,如使用一些自定义或则模拟浏览器的http-header字段。如那些sqlmap的特征可能就是针对于useragent做的文章。
2:字符混淆 尽量不使用网上公开的poc,针对于一些payload中可控的部分做字符混淆,使用字符填充等等。
3:漏洞利用方式 例如之前报过dedecms的recommend的注入漏洞,该漏洞是因为uploadsafe.inc.php界面导致的,其实利用页面还有flink.php等等,网上利用的最多recommend的poc,因此使用flink.php的页面可能就绕过了dedecms ips特征的防御,又如牛B的dedesql.class.php的变量覆盖漏洞,网上大多poc是基于download.php的,其实erraddsave.php等其他页面也是可以利用的,使用一些非主流POC的利用页面,也是可以bypass掉ips特征的。 一般的IPS特征都与基于一个页面来写特征,避免误报的。
0x02 总结
IPS和WAF网络攻击的防护设备,往往为了自身的一些如性能的提升,而放弃了一些功能,例如我见过有些IPS规则在编写的时候不支持正则表达式。可能就是正则表达式匹配的时候会大大的影响性能。由于这些功能上的放弃,必然导致各种各样规则的bypass,作为用户既需要这些防护设备,同时也需要做好自身网络安全的提升,如服务器的补丁,相关服务器的实时监控等等。
【原文:IPS BYPASS姿势 SP小编整理发布】