CVE-2018-9411:影响多个高权限Android服务的漏洞
前言
Zimperium zLabs的研究员最近披露了一个影响多个高权限Android服务的关键漏洞。Google将其指定为CVE-2018-9411并在7月安全更新(2018-07-01补丁级别)中进行了修补,包括9月安全更新(2018-09-01补丁级别)中的其他补丁。
我为此漏洞编写了一个PoC,来演示如何使用它来从常规非特权应用程序中提升权限。
这篇博文将介绍漏洞和漏洞利用的技术细节。以及漏洞相关背景、漏洞相关的服务和漏洞详情。至于为什么选择某个特定服务作为其他服务的攻击目标,文中会详细阐述。
Project Treble
Project Treble对Android内部运作方式进行了大量更改。其中有一个较大的变更,使得许多系统服务都被碎片化了。以前,服务包含AOSP(Android开源项目)和供应商代码。在Project Treble之后,这些服务全部分为一个AOSP服务以及一个或多个供应商服务,称为HAL服务。有关更多背景信息,参阅我的BSidesLV演讲和我之前的博文。
HIDL
Project Treble引入的分离机制导致了IPC(进程间通信)总数的增加; 先前在AOSP和供应商代码之间通过相同过程传递的数据现在必须通过AOSP和HAL服务之间的IPC。因为Android中的大多数IPC通过Binder通信,所以谷歌决定新的IPC也应该这么做。
但仅仅使用现有的Binder代码是不够的,Google也决定进行一些修改。首先,他们引入了多Binder域,以便将这种新型IPC与其他域分开。更重要的是,他们引入了HIDL- 一种通过Binder IPC传递的数据的新格式。这种新格式有一组新的库集,专门用于AOSP和HAL服务之间的IPC新Binder域。其他Binder域仍使用旧格式。
与旧的HIDL格式相比,新HIDL格式的操作有点像层。两者的底层都是Binder内核驱动程序,但顶层是不同的。对于HAL和AOSP服务之间的通信,使用新的库集; 对于其他类型的通信,使用旧的库集。两组库都包含的代码非常相似,以至于某些原始代码甚至直接 被复制到新的HIDL库中(虽然我个人觉得这样复制粘贴并不好)。尽管每个库的用法并不完全相同(你不能简单地用一个替换另一个),但它仍然非常相似。
两组库集都表现为在Binder事务中作为C++对象传输的数据。这意味着HIDL为许多类型的对象引入了自己的新接口,包括了从相对简单的对象(如表示字符串的对象)到更复杂的实现(如文件描述符)或对其他服务的引用。
共享内存
Binder IPC一个重要的方面是使用了共享内存。为了保持简单性和良好性能,Binder将每个事务限制为最大1MB。如果进程希望通过Binder在彼此之间共享大量数据,进程会使用共享内存。
为了通过Binder共享内存,进程利用了Binder用来共享文件描述符的功能。文件描述符可以使用mmap映射到内存,并允许多个进程通过共享文件描述符来共享相同的内存区域。常规Linux(非Android)的需要面对的一个问题是:文件描述符通常由文件提供,那如果进程想要共享匿名内存区域会怎么样?对于这种情况,Android使用了ashmem,它允许进程在不涉及实际文件的情况下分配内存来备份文件描述符。
通过Binder共享内存是HIDL和旧库集之间不同实现的一个例子。在这两种情况下,最终操作都是相同的:一个进程将ashmem文件描述符映射到其内存空间,通过Binder将该文件描述符传输到另一个进程,然后另一个进程将其映射到自己的内存空间。但是处理这个的对象的接口是不同的。
在HIDL的情况下,共享内存的一个重要对象是hidl_memory。如源代码中所述:“hidl_memory是一种可用于在进程之间传输共享内存片段的结构”。
漏洞
让我们来仔细看看hidl_memory的成员:
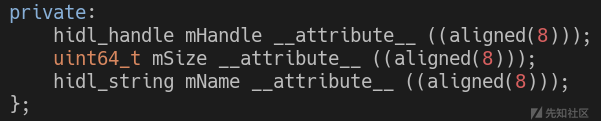
来自system / libhidl / base / include / hidl / HidlSupport.h的片段(源代码)
- mHandle - 一个句柄,是一个包含文件描述符的HIDL对象(在这种情况下只有一个文件描述符)。
- mSize - 要共享的内存大小。
- mName - 应该代表内存的类型,但只有ashmem类型会起作用。
当通过HIDL中的Binder传输这样的结构时,复杂对象(如hidl_handle或hidl_string)有自己的自定义代码用于读写数据,而简单类型(如整数)则“原样”传输。这意味着它的内存大小将作为64位整数传输。另一方面,在旧的库集中,使用32位整数。
这看起来就很奇怪了,为什么内存的大小是64位?为什么不像和旧的库集不一样?32位进程又如何处理这个问题呢?让我们看一下映射hidl_memory对象的代码(针对ashmem类型):
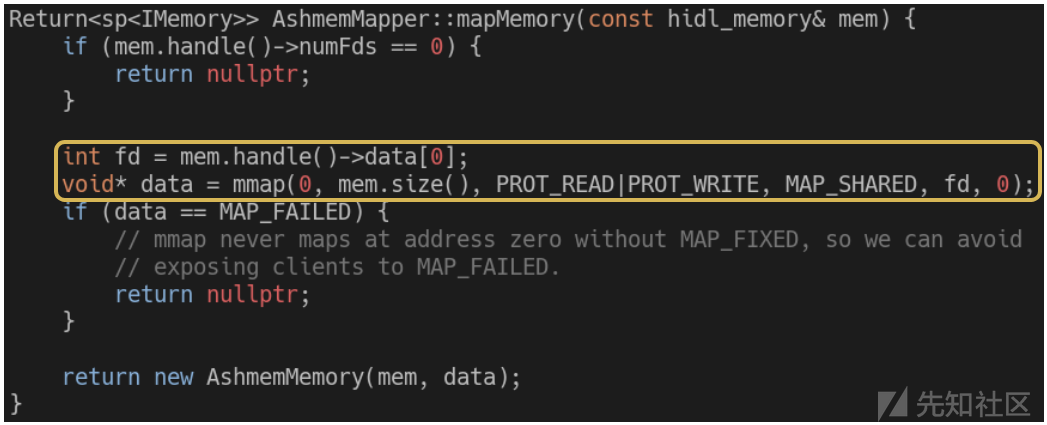
来自system / libhidl / transport / memory / 1.0 / default / AshmemMapper.cpp的片段 (源代码)
有趣!没有任何关于32位进程的处理,甚至没有提到内存大小是64位。
那这中间发生了什么呢?mmap签名中长度字段的类型是size_t,这意味着它的位数与进程的位数相匹配。在64位进程中没有问题,一切都是64位。而在32位进程中,它的大小则被截断为32位,因此仅会使用低32位。
也就是说,如果32位进程接收到大小大于UINT32_MAX(0xFFFFFFFF)的hidl_memory,则实际的映射内存区域将小得多。例如,对于大小为0x100001000的hidl_memory,内存区域的大小将仅为0x1000。在这种情况下,如果32位进程基于hidl_memory大小执行边界检查,结果肯定是失败,因为它们会错误地指示内存区域跨越整个内存空间。这就是漏洞所在!
寻找目标
即然有了漏洞,那现在就试着找到一个利用目标。
寻找符合以下标准的HAL服务:
- 编译为32位。
- 接收共享内存作为输入。
- 在共享内存上执行边界检查时,也不会截断大小。例如,以下代码就没有风险,因为它对截断的size_t执行边界检查:

这些是触发漏洞的基本要求,但我认为还有一些可选的更可靠的目标:
- 在AOSP中有默认接口。虽然供应商最终负责所有HAL服务,但AOSP确实包含某些供应商可以使用的默认接口。在许多情况下,当存在这样的接口时,供应商并不愿意修改它,最终还是原样照搬。这使得这样的目标更有趣,因为它可能与多个供应商相关,而不是特定于供应商的服务。
应该注意的是,尽管HAL服务被设计为只能由其他系统服务访问,但事实并非如此。有一些特定的HAL服务实际上可以由常规的非特权应用程序访问,每个服务都有其自身的原因。因此,目标的最后一个要求是:
- 可以从无特权的应用程序直接访问。否则一切都只能存在于假设中,因为我们将讨论这样一个目标,只有在你已经破坏了另一个服务的情况下才能访问它。
幸运的是,有一个满足所有这些要求的HAL服务:android.hardware.cas,AKA MediaCasService。
CAS
CAS(Conditional Access System),表示条件访问系统。CAS本身大部分超出了本博文的范围,但总的来说,它与DRM类似(因此差异并不是很明显)。简单地说,它的功能与DRM相同 - 存在需要解密的加密数据。
MediaCasService
首先,MediaCasService确实允许应用程序解密加密数据。参阅我以前的博客文章,该博文处理了名为MediaDrmServer的服务中的漏洞,您可能会注意到与DRM进行比较的原因。MediaCasService与MediaDrmServer(负责解密DRM媒体的服务)从其API到内部运行方式都非常相似。
与MediaDrmServer略有不同的是其术语:API不是解密,而是称为解扰(尽管它们最终也会在内部对其进行解密)。
让我们看看解扰方法是如何运作的(这里省略了一些小部分以简化操作):

不出所料,数据通过共享内存共享。有一个缓冲区指示共享内存的相关部分(称为srcBuffer,但与源数据和目标数据相关)。在此缓冲区上,服务从其中读取源数据以及将目标数据写入的位置存在偏移量。可以看出源数据实际上是清除的而不是加密的,在这种情况下,服务将简单地将数据从源复制到目的地而不进行修改。
这个漏洞看起来很赞!至少服务仅使用hidl_memory的size来验证它是否适合共享内存,而不是其他的参数。在这种情况下,通过让服务认为我们的小内存区域跨越整个内存空间,我们可以绕过边界检查,并将源和目标偏移量放在任何我们想放的地方。这能给我们提供对于服务内存的完全读写访问权限,因为我们可以从任何地方读取共享内存并从共享内存写入任何地方。注意到负偏移也在这也起作用,因为即使0xFFFFFFFF(-1)也会小于hidl_memory大小。
查看descramble的代码,验证确实存在这种情况。快速说明:函数validateRangeForSize只检查“ first_param + second_param <= third_param ”,同时注意可能存在的溢出。

来自hardware / interfaces / cas / 1.0 / default / DescramblerImpl.cpp的片段(源代码)
如上所示,代码根据hidl_memory大小检查srcBuffer是否位于共享内存中。在此之后,不再使用hidl_memory,并且针对srcBuffer本身执行其余检查。完美!我们所需要就是获得完全读写权限来触发漏洞,然后将srcBuffer的大小设置为大于0xFFFFFFFF。这样,源和目标偏移的任何值都是有效的了。
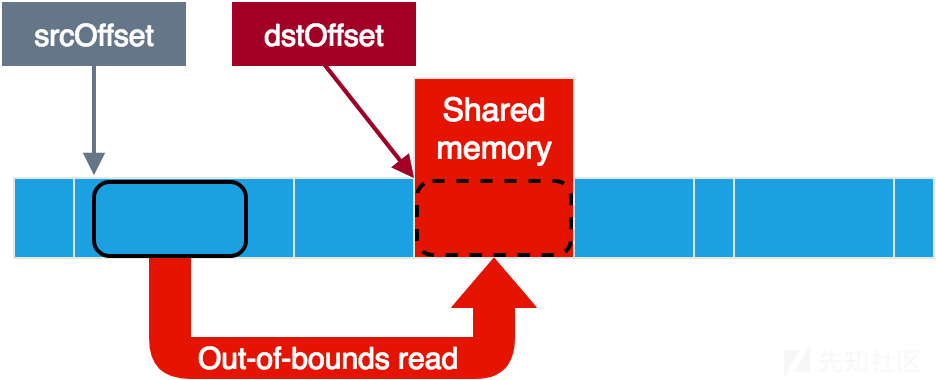
使用漏洞来越界读取
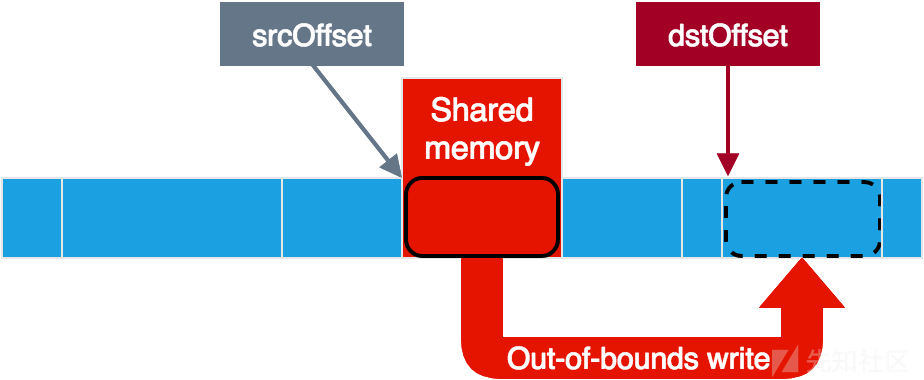
使用漏洞进行越界写入
TEE设备
在使用这个原语编写漏洞之前,让我们考虑一下我们希望这个漏洞实现的目标。此服务的SELinux规则表明它实际上受到严格限制,并没有很多权限。不过,它还是有一个普通非特权应用程序没有的权限:访问TEE(可信执行环境)设备。
此权限非常有趣,因为它允许攻击者访问各种各样的东西:不同供应商的不同设备驱动程序,不同的TrustZone操作系统和大量的trustlet。在我之前的博文中,我已经讨论过这个权限有多危险。
虽然访问TEE设备确实可以做很多事情,但此时我只需证明我可以获得此访问权限。因此,我的目标是执行一个需要访问TEE设备的简单操作。在Qualcomm TEE设备驱动程序中,有一个相当简单的ioctl,用于查询设备上运行的QSEOS版本。因此,构建MediaCasService漏洞的目标是运行此ioctl并获取其结果。
利用
注意:我的exp针对特定设备和版本 - Pixel 2与2018年5月的安全更新(build fingerprint: “google/walleye/walleye:8.1.0/OPM2.171019.029.B1/4720900:user/release-keys”) 。博客文章末尾提供了完整漏洞利用代码的链接。
到目前为止,我们拥有了对目标进程内存的完全读写权限。虽然这是一个很好的开头,但仍有两个问题需要解决:
- ASLR - 虽然我们有完全的读访问权限,但它只是相对于我们共享内存的映射位置; 我们不知道它与内存中的其他数据相比在哪里。理想情况下,我们希望找到共享内存的地址以及其他我们感兴趣的数据的地址。
- 对于漏洞的每次执行,共享内存都会被映射,然后在操作后取消映射。无法保证共享内存每次都会映射到同一位置; 另一个内存区域完全有可能在其执行后取代它。
让我们看一下这个特定版本的服务内存空间中链接器的一些内存映射:

链接器恰好在linker_alloc_small_objects和linker_alloc之间创建了2个内存页(0x2000)的小间隙。这些存储器映射的地址相对较高; 此进程加载的所有库都映射到较低的地址。这意味着这个差距是内存中最高的差距。由于mmap的行为是尝试在低地址之前映射到高地址,因此任何映射2页或更少内存区域的操作都会映射到此间隙中。幸运的是,该服务通常不会映射任何这么小的东西,这意味着这个差距应该始终不变。这解决了我们的第二个问题,因为这是内存中的确定性位置,我们的共享内存将始终映射。
让我们在间隙之后直接查看linker_alloc中的数据:
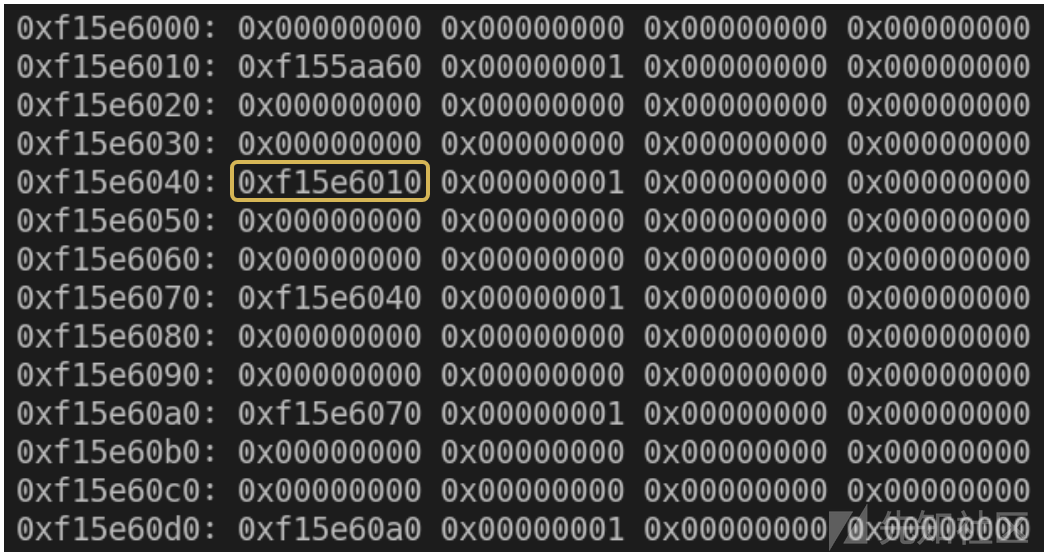
这里的链接器数据对我们非常有帮助; 它包含可以轻松指示linker_alloc内存区域地址的地址。由于漏洞可以让我们相对读取,并且我们已经得出结论,我们的共享内存将在此linker_alloc之前直接映射,我们可以使用它来确定共享内存的地址。如果我们将地址偏移0x40并将其减少0x10,我们就能得到linker_alloc地址。减去共享内存的大小就可以得到共享内存的地址。
到目前为止,我们解决了第二个问题,但只是解决了第一个问题的部分。我们确实有共享内存的地址,但没有其他感兴趣的数据。但是我们感兴趣的其他数据是什么?
劫持一个线程
MediaCasService API的一部分是可以为客户端提供事件侦听器。如果客户端提供侦听器,则会在发生不同CAS事件时通知它。客户端也可以自己触发事件,然后将其发送回侦听器。当通过Binder和HIDL的方式是当服务向侦听器发送事件时,它将等待侦听器完成事件的处理; 一个线程将被阻塞,等待监听器。
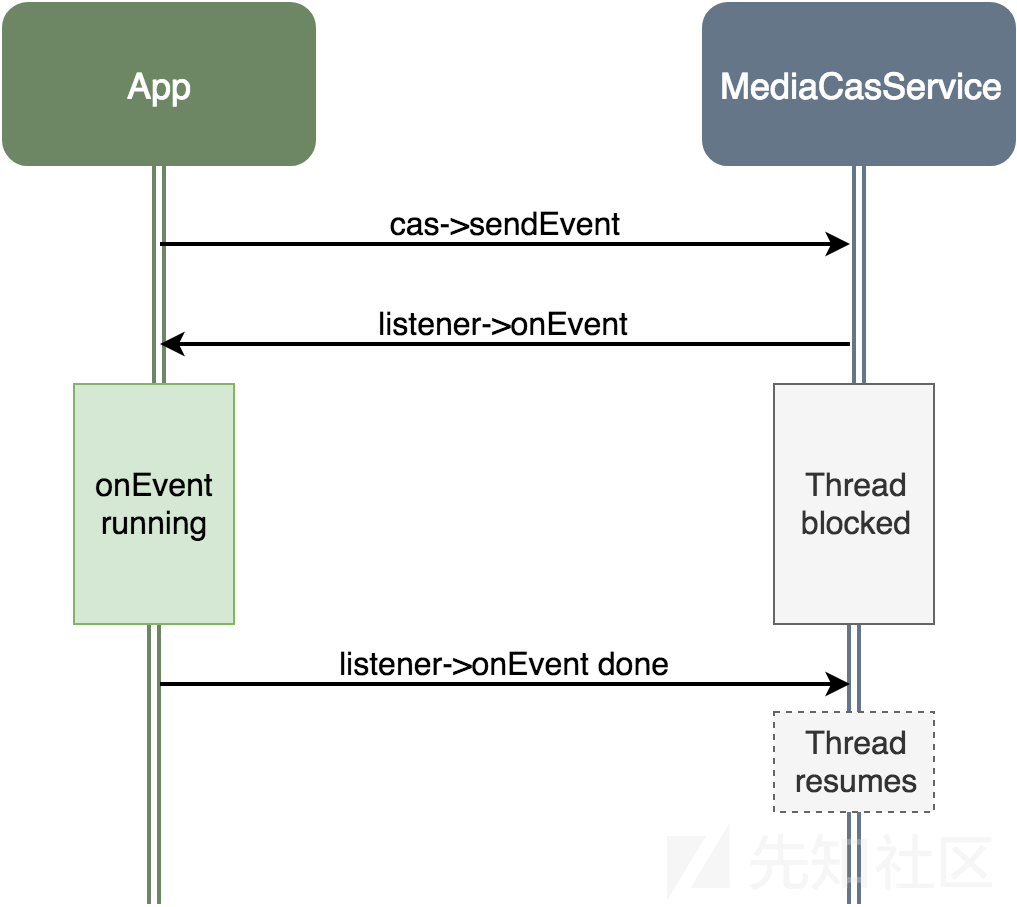
触发事件的流程
我们可以在已知的预定线程中,阻止服务中的线程,让其等待我们的下一步操作。一旦我们有一个处于这种状态的线程,我们就可以修改它的堆栈来劫持它; 然后,只有在我们完成后,我们才能通过完成处理事件来恢复线程。但是我们如何在内存中找到线程堆栈?
由于我们的确定性共享内存地址非常高,因此该地址与被阻塞的线程堆栈的可能位置之间的距离很大。因为ASLR的存在,使得通过相对于确定性地址找到线程堆栈的可能性大大减小,需要另寻他路。尝试使用更大的共享内存,并在阻塞的线程堆栈之前映射它,因此我们将能够通过此漏洞相对地访问它。
相比于只将一个线程带到阻塞状态,我们更倾向使用多个(本例中5个)。这会导致创建更多线程,并分配更多线程堆栈。通过执行此操作,如果内存中存在少量线程堆栈大小的空白,则应填充它们,并且阻塞线程中的至少一个线程堆栈会映射到低地址,而不会在其之前映射任何库(mmap的行为是在低地址之前映射高地址的区域)。然后,理想情况下,如果我们使用大型共享内存,则应在此之前进行映射。

填充间隙并映射共享内存后的MediaCasService内存映射
一个缺点是,有可能其他非预期的东西(如jemalloc堆)会被映射到中间,因此被阻塞的线程堆栈可能不是我们所要的。有多种方法可以解决这个问题。我决定直接使服务崩溃(使用漏洞来写入未映射的地址)并再次尝试,因为每次服务崩溃时它都会重新启动。在任何情况下,这种情况通常都不会发生,即使这样,一次重试通常就足够了。
一旦我们的共享内存在被阻塞的线程堆栈之前被映射,我们就使用该漏洞从线程堆栈中读取两样东西:
线程堆栈地址,使用pthread元数据,它位于堆栈本身之后的同一内存区域中。
libc映射到的地址,以便稍后使用libc中的小工具和符号构建ROP链(libc具有足够的小工具)。我们通过读取libc中特定点的返回地址(位于线程堆栈中)来实现这一点。

从线程堆栈读取的数据
从现在开始,我们可以使用漏洞读取和写入线程堆栈。我们有确切的共享内存位置地址和线程堆栈地址,因此通过使用地址之间的差异,我们可以从共享内存(具有确定性位置的小内存)到达线程堆栈。
ROP链
我们拥有可被恢复的被阻塞的线程堆栈的全部权限,因此下一步是执行ROP链。我们确切地知道要用我们的ROP链覆盖堆栈的哪个部分,因为我们知道线程被阻塞的确切状态。覆盖部分堆栈后恢复线程,从而执行ROP链。
遗憾的是,SELinux对此过程的限制使得我们无法将此ROP链转换为完全任意的代码执行。没有execmem权限,因此无法将匿名内存映射为可执行文件,并且我们无法控制可以映射为可执行文件的文件类型。在这种情况下,目标非常简单(只是运行单个ioctl),所以我只是编写了一个ROP链来执行此操作。从理论上讲,如果你想要执行更复杂的东西,依赖强大的原语,完全是有可能做到的。例如,如果你想根据函数的结果执行复杂的逻辑,你可以执行多阶ROP:执行一个运行该函数的ROP,并将其结果写入某处,读取结果,在自己的进程中执行复杂的逻辑,然后基于此运行另一个ROP链。
如前所述,目标是获得QSEOS版本。这里的代码本质上是由ROP链完成的:

stack_addr是堆栈内存区域的地址,它只是一个我们知道可写的地址,不会被覆盖(堆栈是从底部开始往上构建的),因此我们可以将结果写入该地址,然后使用漏洞读取它。最后的睡眠保证运行ROP链后线程不会立即崩溃,以便我们读取结果。
构建ROP链本身非常简单。libc中有足够的小工具来执行它,所有符号也都在libc中,我们已经拥有了libc的地址。
完成后,由于我们劫持了一个线程来执行我们的ROP链,因此进程处于一个不稳定的状态。为了使所有内容都处于干净状态,我们只使用漏洞(通过写入未映射的地址)使服务崩溃,以便让它重新启动。
写在后面
正如我之前在我的BSidesLV演讲和我之前的博客文章中所讨论的那样,谷歌宣称Project Treble有利于Android的安全性。虽然在许多情况下都是如此,但这个漏洞却是Project Treble与其初衷背道而驰的一个例子。此漏洞位于一个特定的库中,这个库是作为Project Treble的一部分专门引入的,在之前的库中不存在(虽然这些库几乎完全相同)。这次的漏洞存在于常用的库中,因此它会影响许多高权限服务。
GitHub上提供了完整的exp代码。注意:该漏洞仅用于教育或防御目的; 不适用于任何恶意或攻击性用途。