企业安全建设之探索安全数据分析平台
0x01 背景
写这篇文章的初衷有两点:1、研究方向是机器学习+网络安全,主要做的工作说白了就是抓住机器学习和网络安全的结合点训练模型,现在模型有了一些,希望模型落地产生实际的作用,所以想建设一个安全数据分析平台;2、对企业安全建设和安全研究感兴趣,而安全大数据平台在未来几年是企业安全能力建设的核心,也是第一步,所以想建设一个安全数据分析平台练练手。但是这些还只能算温室里的宝宝,把玩着自己的小玩具,我知道搭建的小城堡抵挡不住小怪兽,一是因为我还处在温室之中(还在学校)接触真实的威胁场景比较少,二是相较于黑产威胁等未知威胁,我们都还处在温室之中,所以需要不断的去探索。
0x02 技术架构简单介绍
首先要明确问题,我们要做的是安全数据是什么安全数据?从哪里来?安全数据主要来源于流量和日志。那是做流量数据呢还是日志数据呢?日志数据优点是好处理,缺点是覆盖的信息面小;流量数据优点是信息面全,缺点是信息量大,难处理。各有优劣。我选择了兼顾两者,解析流量成日志,解析后的日志信息较全且容易处理。
那么怎么处置解析后的日志呢?这就涉及到了通用的大数据框架,可以直接借鉴通用的大数据框架打造安全大数据框架,总的来说本文参考的大数据框架有两种:伯克利数据分析栈(BDAS)和ELK Stack。我们来了解下两种大数据框架,伯克利数据分析栈约等于hadoop生态圈+storm+spark,其核心框架是spark,同时该数据分析栈涵盖支持结构化数据SQL查询与分析的查询引擎Spark SQL和Shark,提供机器学习功能的系统MLbase及底层的分布式机器学习库MLlib、并行图计算框架GraphX、流计算框架Spark Streaming和Storm、采样近似计算查询引擎BlinkDB、内存分布式文件系统Tachyon、资源管理框架Mesos等子项目。
要说明的是,Hadoop平台数据离线批处理,实时性差;流计算框架Storm和Streaming有些区别,storm是基于事件级别的流处理,而spark Streaming是mini-batch形式的近似流处理的微型批处理,不是真正意义上的流处理;以上这些都是编程框架,并不能拿来即用。

伯克利数据分析栈项目结构图
而ELK栈就比较简单了,包括ElasticSearch、Logstash、Kibana三个组件,其核心是ElasticSearch。Logstash用于采集、转换数据,相当于hadoop生态圈的flume,一个分布式海量日志收集系统;ElasticSearch是全文搜索引擎,可以快速地储存、搜索和分析海量数据;Kibana是数据可视化组件,可以在Elasticsearch集群上索引的内容之上提供可视化功能。ELK和splunk一样,拿来即用。
0x03 各大公司数据平台技术架构对比
新浪某平台采用的技术架构是常见的Kafka整合ELK stack方案。Kafka作为消息队列缓存用户日志;使用logstash做日志解析,统一成json格式输出到elasticsearch;使用elasticsearch提供实时日志分析与强大的搜索和统计服务;kibana作为数据可视化组件。
斗鱼的某亿级实时日志分析平台的架构和上面的新浪某平台架构差不多,都是基于elk stack,只是少数的组件可能有所不同。

腾讯蓝鲸数据平台告警系统的技术架构同样基于分布式消息队列和全文搜索引擎,但腾讯的告警平台不仅限于此,它的复杂的指标数据统计任务通过使用 Storm 自定义流式计算任务的方法实现,这可能正对应着上面分析过的elk可能不太适合做复杂的大数据统计,storm等编程框架虽说复杂一点,但不可否认有着其独特的用处。
七牛采用的技术架构为 Flume+Kafka+Spark,Flume 相较于 Logstash 有更大的吞吐量,而且与 HDFS 整合的性能比 Logstash 强很多,感觉使用同一套框架的组件性能更佳,七牛云平台的日志数据到 Kafka 后,一路同步到 HDFS,用于离线统计,另一路用于使用 Spark Streaming 进行实时计算,计算结果保存在 Mongodb 集群中。
美团某数据平台的架构基于Hadoop生态和Storm流式计算,首先是数据接入,其次是实时计算和离线计算,下图为整体数据流架构图。
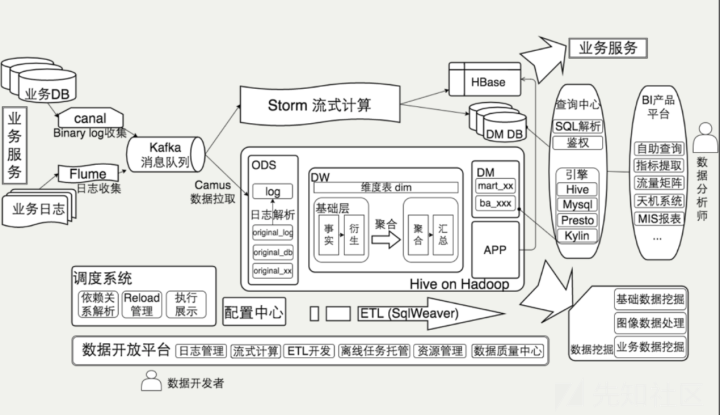
IBM某数据分析平台深度整合了ELK、Spark、Hadoop等组件,技术架构图如下,

其中黑框部分是以elasticsearch为核心的elk栈,外围组件是hadoop生态和spark
0x04 我的安全数据分析平台
暂时我的需求比较简单,分析一两台测试机器的流量,数据量不大,想要的是低门槛操作。
从功能上来说,elk主要做搜索,日志,不太适合做大数据统计,spark实时计算倒是比较适合统计计算。从数据量来说,Spark一套潜在能处理的数据量大一些,但是多数业务需求远到不了Spark Streaming或者ELK的性能瓶颈,两套框架都满足我此时的需求。从流处理计算复杂度来说,在复杂计算场景下,Spark的API提供的表达力更强,也比ELK的配置语言更容易进行充分的单元测试,此处我不考虑复杂计算场景,所以两个框架都满足我的需求。从框架的复杂度来说,ELK简单、轻量、易扩展、易上手,而Spark等是编程框架,需要学习一门编程语言才能处理数据。总结一下:elk能做的,hadoop生态+storm+spark同样能做,还能做的更好,spark栈能做的elk不一定能做到;复杂业务大多使用spark等复杂框架,简单业务可以直接上elk栈。综合对比我的需求和两套框架,同时借鉴ibm数据分析平台整合elk栈和spark、hadoop的方案,我暂时选择ELK栈,但是考虑到二次抽洗,以及周边生态等等其他因素,未来可能还是得加入spark和hadoop生态圈。所以我的做法是先实现bro+kafka+elk,之后加入hadoop生态和spark,如图,
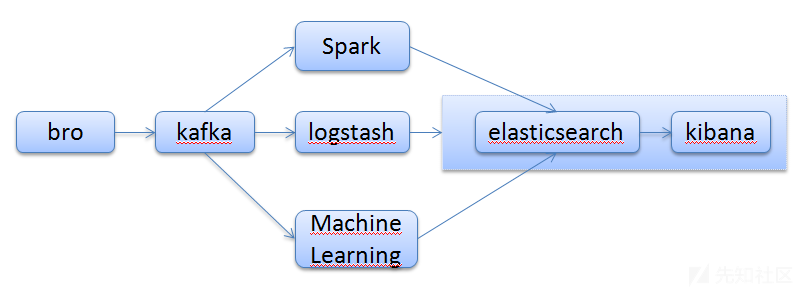
分为三条支线elasticsearch伪实时搜索,自写的机器学习模型测试脚本近似实时计算,之后可能会被spark代替。Bro+elk搭建网上有现成的资料,例如基于Bro的应用层数据包识别工具和威胁猎杀实战(一):平台等,搭建比较简单,就不介绍了。
0x05 模型部署和系统落地
根据比较成熟的开源资料训练了几个模型,dnstunnel:使用深度学习检测DNS隧道;xssdetection:使用深度学习检测XSS;urldetection:使用机器学习检测URL;参见https://github.com/404notf0und/AI-for-Security-Testing
,按照里面的代码可以分别训练出配置文件和模型,尝试部署模型,主要就是加载训练出的模型消费Kafka中的数据。这里要注意的是写测试脚本是在理解训练脚本的基础上进行的,因为训练阶段有些只能做到训练保存模型参数,不能把特征化步骤一起封装到模型中,而有些可以利用pipeline将TFIDF特征化处理保存到模型中,这样在测试时就不需要再调用tfidf类特征化数据了,只需要直接加载模型输入原始数据。这里以部署xss检测模型为例,部分测试代码为:
def xss_detection(payload):
xssed_data=[]
maxlen=200
word=GeneSeg(payload)
xssed_data.append(word)
data=xssed_data[0]
datas_index=[to_index(data)]
datas_index=pad_sequences(datas_index,value=-1,maxlen=maxlen)
datas_embed=[]
dims=len(embeddings["UNK"])
for datas_index in datas_index:
data_embed=[]
for d in datas_index:
if d != -1:
data_embed.extend(embeddings[reverse_dictionary[d]])
else:
data_embed.extend([0.0] * dims)
datas_embed.append(data_embed)
data=(datas_embed[0])
result=model.predict([data])
if result==numpy.array([1]):
return True
else:
return False
def xss(url):
parsed_url=urlparse(url)
query=parsed_url.query
if query=='':
return 0
else:
try:
variables = query.split('&')
values = [ variable.split('=')[1] for variable in variables if len(variable.split('='))>1 ]
for value in values:
result=xss_detection(value)
if result==True:
return 1 #print("may be xss_attack:",url)
else:
return 0
except Exception as err:
return 0
print(xss('http://br-ofertasimperdiveis.epizy.com/produto.php?linkcompleto=iphone-6-plus-apple-64gb-cinza'))
print(xss('http://my-softbank-security.com/wap_login.htm'))
再从Kafka中消费数据,测试模型,
consumer = KafkaConsumer('http')
for message in consumer:
print(message)
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
http_log = json.loads(message.value.decode('utf-8'))
http_query = http_log["host"]+http_log["uri"]
#print(http_query)
if xss(http_query):
print(http_query," XSS ")
"""
dns_query = http_log["query"]
x = domain2list(extract(dns_query).domain)
X = mat([x,])
rs = results[model.predict_classes(X)[0][0]]
print(rs, dns_query)
"""
然后同理就可以堆已有的检测模型了,例如dns隧道检测模型和dga检测模型,首先加载模型,然后模型消费kafka数据。
consumer = KafkaConsumer('dns')
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
dns_log = json.loads(message.value.decode('utf-8'))
dns_query = dns_log["query"]
org_X = extract_domain(dns_query)
X = [[valid_chars[y] if y in valid_chars else 0 for y in x] for x in org_X]
X = pad_sequences(X, maxlen=maxlen, value=0.)
X = np.mat(X)
rs = model.predict_classes(X)[0][0]
print(rs, dns_query)
把所有训练的模型全实验一遍做了个平台demo,数据量小的情况下可以做到实时安全检测和分析,考虑到平台的扩展性,之后可能会加入spark,hadoop等,可能会采用spark的MLlib训练测试机器学习模型。但是由于此处没考虑到实际业务的需求,搭建的平台可能会简单化理想化。
最后简单总结一下:安全数据分析平台主要由大数据框架、安全数据和安全算法组成,如果把安全大数据分析平台比作是一个人的话,那么大数据框架是骨架,安全数据是血液,安全算法是血管,缺一不可。
0x06 Reference
http://webber.tech/posts/%E5%9F%BA%E4%BA%8E%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%92%8C%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%9A%84web%E5%BC%82%E5%B8%B8%E5%8F%82%E6%95%B0%E6%A3%80%E6%B5%8B%E7%B3%BB%E7%BB%9FDemo%E5%AE%9E%E7%8E%B0/
https://www.aqniu.com/tools-tech/12461.html
https://github.com/SparkSharly/DL_for_xss
https://www.jianshu.com/p/eb2bc8d8ebc0
https://www.ibm.com/developerworks/cn/analytics/library/ba-1512-elkstack-logprocessing/index.html