数据库逆向工程(一)
数据库逆向工程,第1部分:简介
原文:https://medium.com/@MorteNoir/database-reverse-engineering-part-1-introduction-cd6e6a106a84
当今,逆向工程社区的研究重点主要集中在代码领域,他们关心的问题为“代码是如何工作的以及它们是如何处理数据的”?在本文中,我们将从另一个角度来进行逆向工程,所以,这里关注的问题是“代码所处理的数据是如何组织的”?
在此过程中,我们要面对的是专有文件格式和数据库分析、interfile格式、数据结构逆向分析方法,各种不借助反汇编和调试器的研究方法以及相关的数据解压方法。并且,通常无法借助于完整的源代码和SQL数据库。
文件格式逆向分析
数据库的逆向分析是以文件格式的逆向分析为基础的,并且,前者通常会比后者更为抽象。

抽象层次
对于第一个抽象层次来说,我们的研究对象为与其他文件无关或仅在语义上与其他文件相关的单个文件,例如,文件夹中的一组.jpg文件。首先,我们需要给出文件、文件格式和二进制文件等术语的定义。
文件是根据某些规则组织在一起的数据。
文件格式是文件中数据的组织规则。
一个简单的例子是由几行文本构成的文件。该文件的格式可以视为由换行符进行分隔的UTF-8编码格式的文本。
For us, and for our tragedy,
Here stooping to your clemency,
We beg your hearing patiently.
二进制文件是用于存放原始字节和/或人类可读信息的文件。
假设有一个二进制文件,其中存储的是某些消息及其日期,具体如图所示。这个文件的格式比前面看过的格式要更规整一些:前4个字节是消息的长度(0xC),接下来的字节中存放的是一则消息("Some message"),其长度就是前面的长度字段指定的字节数,注意,这里的NULL字节不计数;后面的一个字节中存放的内容(0x6 = 6)表示月内的几号;接下来的一个字节中的内容(0xB = 11)描述是年内的月份,最后两个字节中的内容(0x7E1 = 2017)表示的是年份。
0C 00 00 00-53 6F 6D 65-20 6D 65 73-73 61 67 65 ♀ Some message
06 0B E1 07- - - ♠◙с•
当然,互联网上已经有几篇关于文件格式逆向工程的文章,但数量并不多。此外,目前已有一些用于描述文件格式的工具,不过,这些十六进制编辑器通常需要借助命令式脚本语言来增强其功能。在这些工具中,最先进的恐怕就是Kaitai Struct了,它支持用户以声明方式来描述二进制文件格式。
数据库逆向分析
当我们研究内部紧密相关的二进制文件集合时,我们就会进入第二个抽象层次。我们称这个集合为“数据库”。
数据库是一组存放结构化数据并且彼此交叉引用的二进制文件。
请注意,这里是数据库的非常抽象的定义。不过,就像目前的逆向工程过程仍然涉及众多细枝末节一样,数据库的逆向分析过程也不例外——我们很难绕过数据库内部运行机制的研究而直接着手数据处理。当然,在极少数的情况下,我们是无需进行逆向分析的。
假设我们有一个乐队数据库,其中包含3个二进制文件:Band.dat1是一个乐队列表,Album.dat2存放的是每个乐队的专辑,Image.dat3存放的是乐队成员照片和专辑封面。
Band.dat1
Album.dat2
Image.dat3
下面,我们来介绍一下Band.dat1。它是由下列元素组成,各个元素的结构如下所示:
- 一个机器字:乐队ID。
- 0x20个字节:乐队名称;未使用的字节被置零。
- 由机器字组成的列表,直到遇到终止符0xFFFF结束:专辑ID列表。
- 0xFFFF终止符。
- 由双字组成的列表,直到遇到终止符0xFFFFFFFF结束:照片ID列表。
- 0xFFFFFFFF终止符。
在这里,有两个依赖项:专辑ID(对Album.dat2的交叉引用)和照片ID(对Image.dat3的交叉引用)。
00 00 54 6F-6F 6C 00 00-00 00 00 00-00 00 00 00 Tool
00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
00 00 00 00-01 00 02 00-03 00 FF FF-00 00 00 80 ☺ ☻ ♥ А
01 00 00 80-FF FF FF FF- - ☺ А
现在,我们来看看Album.dat2。它是一个由四个元素组成的数组,每个元素描述如下:
- 一个机器字:专辑ID。
- 一个机器字:发行年份。
- 一个字节:专辑标题长度。
- N个字节:专辑标题。
- 一个双字:封面ID。
这里只有一个依赖:封面ID(对Image.dat3的交叉引用)。
00 00 C9 07-08 55 6E 64-65 72 74 6F-77 02 00 00 ╔•◘Undertow☻
80 01 00 CC-07 06 41 65-6E 69 6D 61-03 00 00 80 А☺ ╠•♠Aenima♥ А
02 00 D1 07-09 4C 61 74-65 72 61 6C-75 73 04 00 ☻ ╤•○Lateralus♦
00 80 03 00-D6 07 0A 31-30 30 30 30-20 44 61 79 А♥ ╓•◙10000 Day
73 05 00 00-80 - - s♣ А
最后,我们来了解一下Image.dat3。它是一个包含6个元素的数组,数组长度为0x10字节,不依赖于其他文件,各个元素格式为:
- 一个双字:图片ID。
- 0xC个字节:图片(当然是虚构的)。
00 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 АPIC
01 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 ☺ АPIC
02 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 ☻ АPIC
03 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 ♥ АPIC
04 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 ♦ АPIC
05 00 00 80-50 49 43 00-00 00 00 00-00 00 00 00 ♣ АPIC
下图展示的是三个文件的格式及其依赖关系,这实际上是一种数据库架构。
数据库架构
因此,我们已经掌握了2个抽象层次——文件格式层次和数据库层次,从而为进一步研究数据库问题做好准备。
数据库逆向分析所要解决的问题,就是重建未知数据结构,并确定它们之间的依赖关系。
数据库的逆向分析是完成许多实际任务的必经之路,而非最终目标。经过这个阶段之后,就要开始处理数据:将数据转换为新型的、具有可能关系的数据库。该过程可以称为ETL(抽取,转换,加载),但它与数据库逆向分析无关。
目前,我没有找到与这个主题相关的任何文章。之所以出现这种情况,可能是因为专家没有将文件格式逆向分析和数据库逆向分析区别对待。另一个原因是数据库逆向分析是一个非常耗时的过程,通常需要在保密协议下进行的,所以,这一点也是有很大影响的。
小结
在本文中,我们为数据库给出了一个比较正式的定义,即一组文件,但在现实中,这个定义的外延并没有非常严格:如果我们主观认为某个数据集的元素是相互关联的,我们通常就会称之为数据库。研究数据如何关联是非常重要的,无论数据位于单个文件中还是分布在多个文件中。在这方面的研究过程中,还要面对巨大的复杂性:着手一项新任务时,我们通常会面临大量文件名和扩展名没有具体含义的文件,以及处理这些文件的程序。为此,我们需要使用十六进制编辑器逐个检查文件,并检测其异同,考察其可能的各种结构,检查是否存在文本文件,等等。之后,我们才会考察程序本身。当完成审查后,我们可能会得到一些独立的线索,重要的是,留下线索的人并不希望让我们搞清楚。在后面的文章中,我们将为读者具体介绍如何处理这些棘手的问题。
数据库逆向工程,第2部分:主要的逆向分析方法
原文:https://medium.com/@MorteNoir/database-reverse-engineering-part-2-main-approaches-ae9355b2d429
前言
在本系列的第一篇文章中,我们为读者简要介绍了数据库研究的一个特殊领域。从本文开始,我们将转向数据库逆向分析的实战方面。在本文中,将为读者详细描述我对数据库逆向工程过程的见解,当我说“应该”、“需要”和“必须”时,只代表我自己的主观感受,而没有任何硬性要求。另外,请注意,“交叉引用”、“绑定”、“连接”、“互连”和“依赖”这些词,在本文中都是可以互换的同义词。
任务的拟定
这里,假设我们的研究对象是Microcat Ford USA软件的数据库,其中,Microcat Ford USA是汽车制造商为服务中心开发的一款软件。这种软件的用途就是显示汽车零件、维修时间,以及根据VIN号搜索汽车等。它们为逆向工程师提供了广阔的施展空间,因为它们是针对不同的体系结构、不同的编程语言、不同的时间、不同级别的程序员编写的,最重要的是,它们不仅是紧密相关的,并且使用的也非常频繁。
这种软件的数据库逆向分析目标之一,就是直接访问原本由程序提供给用户的信息,换句话说,我们需要绕过GUI来直接操纵数据。如果开发人员使用的是基于SQL语言的主流DBMS,而不是他们自己创建的专有DB的话,则根本不需要逆向工程——至少对于我遇到的大多数情况来说,都是如此。这些DB在车辆软件开发人员之间没有实现标准化处理,彼此之间的实现常常是截然不同的,并且具有非常复杂的内部构造。
我们的任务是,搞清楚数据库是如何保存车辆信息,如何获取每辆车的部件列表以及如何处理零件图的。需要说明的是,这里之所以选择这项任务,只是为了阐明数据库逆向工程的具体过程;而选择Microcat Ford USA的原因,只是因为它贴近生活。当然,我们对数据的含义没有多大的感兴趣,所以,即使您对于汽车相关术语不太了解的话,也没有多大的影响。
第一种数据库逆向工程方法
考虑到使用DB的每个程序都含有相关的DBMS组件或者本身就是DBMS这一事实,所以,将考察的程序视为DBMS也是非常合理的。对于第一种主要的数据库逆向方法来说,这个假设是非常有用的。
[2.1]将使用DB的程序视为DBMS。
这里的重点在于,如果有一个数据库跟一个程序之间存在交互行为的话,那么,只要重现DBMS所执行的操作,就足以了解DB的内部机制。由于存在对DB结构“门清”的程序,因此,我们根本无需从头开始对DB进行逆向分析。这一点的重要性将在后面的实践中得到证实。
初步分析
在安装程序后,我们可以找到如下两个文件夹:MCFNA和FNA_Data。
C:\MCFNA
│ ANIBUTON.VBX
│ BTDESIGN.DLL
│ CMDIALOG.VBX
...
│ MCFNA.EXE
│ MCI.VBX
│ MCLANG02.DLL
...
│ XCDUNZIP.DLL
│ XCDZIP.DLL
│ XCEEDZIP.VBX
│
├───DMS
...
├───Lex
...
├───Locator
...
├───mcindex
...
└───Print32
...
C:\FNA_DATA
│ AAEXT.DAT
│ ASI.idx
│ avsmodel.dat
│ AVSXRef.DAT
│ Calib.dat
│ DSET.DAT
│ EngDate.dat
│ EngDateB.dat
│ EngXRef.dat
│ FNAc.DAT
│ grp.dat
│ grp.idx
│ grpavs.idx
│ grpbasic.idx
│ grpdesc.idx
│ grpinc.dat
│ grppub.dat
│ grpxref.idx
│ LM.txt
│ MCData.DAT
│ MCData.IDX
│ MCHELP32.EXE
│ MCImage.DAT
│ MCImage.IDX
│ MCImage2.DAT
│ MCOSI.DAT
│ MCPart.IDX
│ MCPartLx.IDX
│ MotorCS.IDX
│ MS.dat
│ MY.IDX
│ partid.DAT
│ PB.idx
│ PL.idx
│ RECALL.Dat
│ SecID.DAT
│ XGROUPS.IDX
│
├───Help
...
├───Install
...
├───Lex
│ FEULex.DAT
│ LexInd.IDX
│
├───MFNotes
...
├───Preface
...
├───Pricing
...
├───Res
...
└───VIN
│ BrVIN.DAT
│ Last8.idx
│ MCMFC.DAT
│ MCRego.DAT
│ MCVIN.DAT
│
├───Decode
│ 10.dat
│ 11.dat
│ 123.dat
│ 80_C_1.dat
│ 80_C_2.dat
│ 80_C_34.dat
│ 80_C_5.dat
│ 9.dat
│ BR_10.dat
│ BR_11.dat
│ BR_123.dat
│ BR_4.dat
│ BR_567.dat
│ BR_8.dat
│ C_4.dat
│ C_5.dat
│ C_67.dat
│ C_8.dat
│ E_8.dat
│ LTT_4.dat
│ LTT_567.dat
│ LTT_8.dat
│ MED_8.dat
│ Prod20-FNARelease-Vin-Decode
│
├───TSL
│ FNITVIN.dat
│ TSL.dat
│ TSLCatalogue.dat
│ TSLHi.dat
│ TSLPT.dat
│ TSLRef.dat
│ TSLSection.dat
│ TSLVIN.IDX
│ TSLVINR.IDX
│ VBOM.dat
│
└───VCIS
1F01.xcd
1F0B.xcd
1F14.xcd
...
4M2P.xcd
4M2R.xcd
4M2S.xcd
...
WF05.xcd
Z6FD.xcd
Z6FE.xcd
通过文件扩展名不难看出,MCFNA是可执行文件所在目录,而FNA_Data则是数据文件所在目录。请注意,这里的数据文件扩展名只有三种,分别是:dat、idx和xcd。需要注意的是,大家不要被这些扩展名所误导,因为单独靠扩展名通常是看不出什么门道的。
主要的分析工作涉及四个步骤:
- GUI概览;
- 数据文件审查;
- 代码文件审查;
- 查找可重用的代码。
GUI概览
下面给出一些截图,以便对我们所讨论的程序有一个直观的感受。

车辆的选择
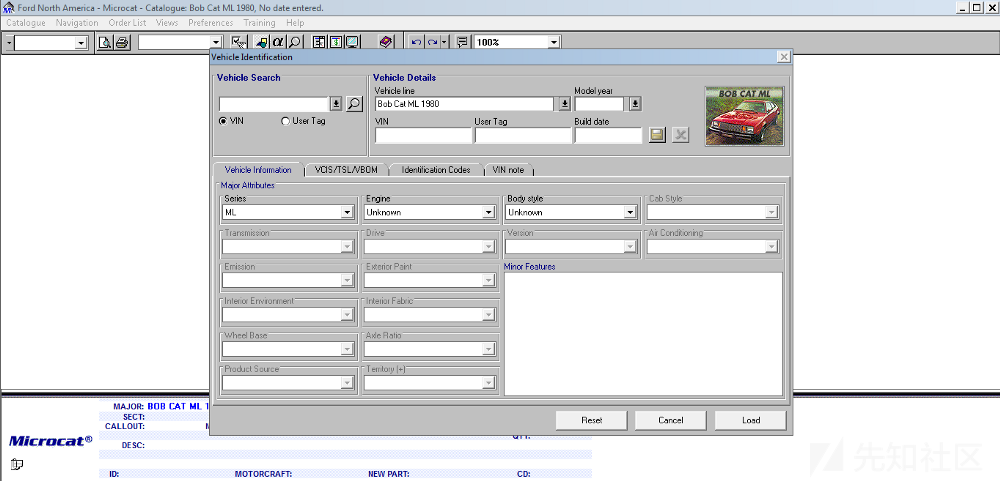
车辆的属性

零件图
数据文件审查
我们可以通过快速浏览十六进制编辑器中的各个文件来研究其特点(如,文本/二进制文件,开源/专有等)。 如果您使用Hiew的话,请从文本模式开始下手,并且在必要时可以切换到十六进制模式。下面显示的是几个文件的屏幕截图。

avsmodel.dat(文本模式)

FNAc.dat(文本模式)

MCData.dat(十六进制模式)
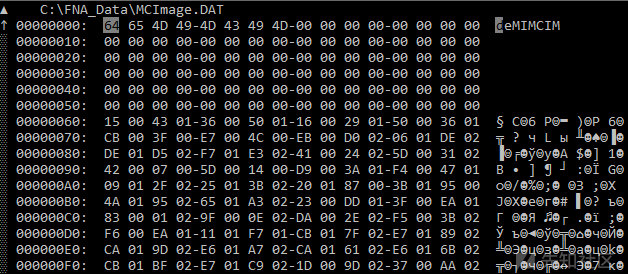
MCImage.dat(十六进制模式)
如您所见,尽管这些文件的扩展名是一致的,但文件的结构却完全不同。 唯一标准化的扩展名是xcd:实际上,它们是些zip存档,但我们这里对它们没有什么兴趣。
代码文件的审计
借助于DiE或Hiew之类的PE工具,我们可以发现,这些可执行文件采用的是NE格式,即16位Windows程序的新型可执行文件(New Executable)格式。对于这些可执行文件来说,有一些采取了VBX文件扩展名,并且通过内容可以猜出,它们是用Visual Basic语言编写的。此外,许多DLL也是用这种语言编写的。

CMDIALOG.VBX
此外,一些DLL和VBX则经过了加壳处理,这种情况下,它们无法借助PE/NE工具进行识别。

FILE16.DLL
在谷歌搜索引擎的帮助下,我们发现这其实就是Shrinker,一个古老的、针对Visual Basic 3.0编译的NE文件的加壳器。此外,我们还在一个死链接中找到脱壳器(NED 2.30),这真是太好了,因为这就意味着不用浪费时间来静态脱壳或通过NTVDM进行调试了(当然,虽然我还是这样做了,具体原因后面再说)。
我们已经审查了正在处理的数据和代码——一堆“古董”。 下面,我们来做一个简单的总结。
[2.2]对待处理的数据和代码进行初步分析。对于在审查期间找到的关键字,可以通过互联网进行搜索,尽量挖掘更多的信息。
查找可重用代码
在编程过程中,代码重用是一种很好的习惯,在我看来,对于逆向工程来说也是如此。不同之处只是在于,程序员通常都有模块接口文档可用,而我们必须首先找到相关的模块和函数,然后对其接口进行逆向工程,虽然有些繁琐,但是比起从头编写代码来说,还是要容易得多。在我的一个项目中,遇到了一个定制版的开源SQL数据库,如果从头开始逆向分析的话,那就需要大量的时间。幸运的是,我们发现该程序使用了一个代码库,其导出过程类似于存储过程,于是,我根据这一点重建了几个类,这样一来,不仅可以将对象传递给库函数,还能接收数据库返回的响应数据。
于是,我们将这种技术应用于自己的任务,并考察了所有库的导出内容。尽管某些数据库术语(CODESTR,DMC,NISSANSECNUM,TMCSECNUM等)的含义是未知的,但我们发现,这些都是我们所感兴趣的东东。

FNAUTIL2.DLL库的导出内容
[2.3]审查各个程序模块,查找可重用代码。在数据库逆向分析的过程中,需要定期应用该方法,之所以这么做,是因为许多时候并不清楚哪些代码是可重用的,哪些不是。
实际上,这是一种非常强大的方法,能够帮助我们节省数周甚至数月的时间,但是,它有一个缺点:需要处理的黑盒子越多,它们执行的操作越少,代码重用过程就越复杂。在上图中,展示了用于进行计算和验证的相关函数。不过,它们也许还必须以某种顺序调用,或者依赖于全局程序状态,等等。但是,如果有一个GetAllDatabaseRecords函数的话,事情就会变得更简单了,对吧?
有时,我们所遇到的软件是用易于反编译的语言(如Java和.NET)编写的。不过,除非存在简单易用的数据库界面,否则的话,还是忽略(通过反编译得到的)源码为妙,一则这些代码实在太长,二则弄懂这些代码所需的时间通常是难以接受的。这时候,与其阅读源码,还不如进行逆向工程来的简单。
[2.4]代码重用的复杂性与黑盒子的数量成正比,与其执行的动作数量成反比。
如果有很多函数,并且每个函数的作用都很小,那么花太多时间研究它们的接口是有风险的。如果函数代码都很少,但是它们执行的工作可以简化您的工作,那么可以评估一下从研究它们的接口所需的时间,以及从头开始逆向分析所需时间,然后再做决定。如果有很多函数,而且它们做了很多事情,那么一定要尽量使用它们!
这就完成了一个初步的分析。当然,还可能包括其他步骤,如阅读文档、将正在分析的数据库/程序与以前的项目进行比较等等,但对于我来说,我总是会执行上面描述的三个步骤。
选择入口点
为了理解数据库,接下来要做的就是选择一个入口点,即这样一个数据集:首先,其结构不依赖于其他结构,其次,可帮助我们调查其他结构。如果用形象的方式来解释的话,就是这样的:任务所需数据对应于坐标轴上的各个点,且从概念上来说,右边的数据依赖于左边的数据,那么,最左边的点就是我们的入口点。

依赖轴
在我们的任务中,需要处理的第一个数据集就是车辆信息。此外,我们知道,该程序在启动时会显示车辆选择菜单,由此可以得出结论:车辆是原始入口点;我们可以把它想象成数据库的OEP。所以,这里假设“车辆”不依赖于其他结构,并且是EP的正确选择。

将假想的依赖树转换为实际的依赖树
另一方面,对于某些任务来说,可能无需借助于依赖树的根节点处的数据。在这种情况下,您有两条路可走。
- 直接从所需的点开始下手,前提条件是不需要了解前面的点的结构。如果使用这种方式的话,有可能对以后理解复杂的结构有影响。因此,只有当您熟悉主题领域和/或具有数据库RE经验时,才可以选择这种方式。
- 从树的根节点开始下手,一直研究到所需的点。虽然这种方式比较耗时,但是却更加稳妥,所以,我总是选择这种方式。
[2.5]选择数据库入口点:离初始入口点越近,需要预先研究的结构就越少。理想情况下,所需的入口点正好就是初始入口点。
那么,我们如何才能正确选择EP呢?除了直觉经验之外,没有什么好法子。选择入口点之后,继续进行逆向分析,如果发现自己处于死胡同,那就试着寻找其他方法。实在没辙了,就祭出反汇编程序作为最后的手段。
入口点探测
选择EP后,接下来要做的事情便是找到包含所需数据的文件或文件,就本文来说,就是车辆信息。为此,我的做法是,选择几个关键字,然后在所有文件中搜索它们。关键字是深入刻画您要查找的数据的那些字符串。例如,已知有一辆车的名称为“Bob Cat ML 1980”,发动机下拉菜单中有“2.3 L OHC”信息等,这些都可以作为关键字。

选择关键字
在搜索字符串时,需要注意一些事项。
- 它们可能采用了不同的编码,通常是ASCII或UTF-16。我们可以通过Total Commander解决这个问题,它允许我们一次搜索多种编码形式的词语(也许Far Manager也可以完成这些工作)。
- 它们能够以非标准形式存储、压缩或保存在压缩文件中。
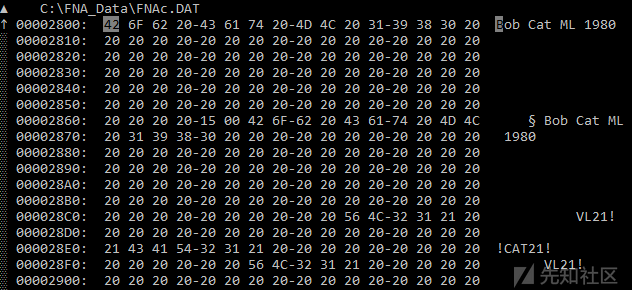
搜索后,我们仅在一个文件中找到了“Bob Cat ML 1980”字符串,这个文件就是FNAc.dat
在检查该文件后,我们发现它确实包含程序主菜单中显示的所有车辆的名称。我们将这个文件称为catalogue。 因此,我们已经找到了入口点的物理表示。
[2.6]考察代表数据库入口点的文件。
(未完待续)